原创 刘河庆 定量群学

文章图片
引言
大数据时代算法对我们个体的生活有着愈来愈重要的影响 , 从简历筛选、贷款申请再到刑事司法系统 , 算法都在不断帮助人类做出决策 。 虽然算法在提高决策准确性方面表现出了相当大的潜力 , 但在某些情况下 , 算法可能会对特定社会群体(如女性、黑人)施加不公平对待 。
例如随着深度学习和神经网络等一系列算法的出现 , 人们发现本应毫无偏见的计算机也习得了人类社会中的各种偏见 。 在计算机视觉领域 , 不同性别用户发布的图片内容不同 , 导致视觉语义标注中也存在性别偏见 , 如在厨房中的人物总是被识别为女性 。 对自然语言处理领域的研究发现算法不仅准确复制了训练数据中的性别偏见 , 甚至还在下游应用任务中放大了偏差(Zhao et al. ,2017) 。 本期推文将以词向量算法中反映的社会偏见为例 , 为大家介绍目前测量以及分析算法中偏见的相关研究 。
01
测量词向量算法中的社会偏见
词向量模型是目前众多自然语言处理模型的重要组成部分 , 以word2vec模型为例 , 该模型将文本作为单词序列提供给单词嵌入层 , 该层将每个单词映射为向量空间中的实数向量 , 从而获得每个词汇的向量表示 。 基于词汇的向量表示 , 我们可以直接测量模型中的单词或短语之间的类比或关联 , 这些类比许多都是符合预期的 , 因此被广泛应用于文档分类、问答系统等下游任务 。 如根据词汇的向量表示可以得出等式king - man + woman = queen , 实现单词的类比 。
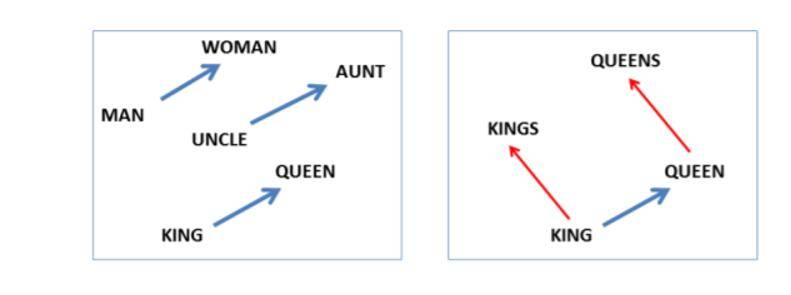
文章图片
图1
然而 , 也有些关联或类比可能会有问题 , 如Bolukbasi等人使用基于 Google 新闻语料库的Word2Vec模型 , 定量地证明了单词嵌入在其几何上的偏差反映了在更广泛的社会中存在的性别刻板印象 , 发现即使训练数据为专业性较强的谷歌新闻数据 , 词向量算法仍习得并放大了传统关于性别的刻板印象 。 具体而言 , 作者发现对于训练完成的向量空间中 , 会发现man - woman = computer programmer – homemaker , 也即如果男性对应程序员 , 女性则更可能对应家庭主妇 。 同时 , 他们也发现如果父亲对应医生 , 那母亲会对应什么呢?训练完成的词向量给出的答案是护士 。
为了准确量化词向量所学习到的性别偏见 , Bolukbasi等同时计算一个词向量和一对性别特定词的向量之间的语义距离 , 例如同时计算护士与父亲、母亲这一对性别特征词的语义距离(类似的性别特征词对还包括哥哥-姐姐 , 男商人-女商人 , 男孩-女孩等) , 这样能准确量化不同性别在向量空间中与不同职业的语义距离 。 如何图1左侧具体呈现了w2vNEWS中分别与she和he最相关(语义距离更近)的职业 , 可以明显看到男性和女性相关职业的巨大差异 。 图2右侧展示了词向量模型中可以与she和he类比的词对(词对在向量空间中余弦距离近似即为可类比) , 上半部分为明显带有性别刻板印象的词对 , 下半部分为不带有性别刻板印象的词对 。

文章图片
图2
02
词向量除偏
如何消除或缓解算法所习得的社会偏见呢 , Bolukbasi等人尝试通过消除性别刻板印象 , 例如服务员和女性之间的联系 , 同时保留所期望的联系 , 比如女王和女性之间的关联 , 来减少性别偏差 。
他们区分了与性别相关的性别特定词 , 如祖父 , 祖母、兄弟、姐妹 , 以及与性别不直接相关的性别中性词 。 此后 , 他们确定了两个正交维度 , 即性别特定词与性别中性词间的差别 , 进而通过折叠性别中立的方向去除性别中性词和性别的关联 。 也即是说作者将doctor或nurse等性别中性词通过移动其在向量空间中的位置来减少或是消除他们的性别歧视趋势 。 以图3为例 , 图中上半部分代表在向量空间中有性别偏见的中性词 , 其中左侧的词汇跟女性语义距离更近 , 右侧的词汇跟男性的语义距离更近 , 作者通过将左侧和右侧的词汇向中间移动来达到减少词向量模型中性别偏见的目的 。
【性别|算法习得并强化了人类偏见吗?如何测量、分析算法中的偏见】
文章图片
图3
03
讨论
算法经常被质疑的一个点是其根据人们过往的行为数据或人们所在群体过往的行为数据来进行决策 , 这往往会强化传统的群体间的不平等 。 从本期所推荐的文章可以看到 , 除行为数据外 , 算法也可以直接学习到现实社会关于不同群体的刻板印象 。 词向量作为当前众多自然语言处理任务的底层训练模型 , 因其能准确学习词汇间的语义关系而得到广泛应用 , 但另一方面也会导致基于词向量模型所得到的词汇的向量表示 , 不仅复制了训练数据中的性别偏见 , 甚至还在下游应用任务中放大了偏差 。
本期所推荐的文章从技术角度对如何消除或缓解算法所习得的社会偏见进行了研究 , 后续也有研究进一步从模型改进、提高训练数据质量等角度进一步尝试消除或缓解算法中的偏见 , 这些研究从表面上减少或隐藏了算法中的偏见 , 但这种偏见的隐藏在现实实践中究竟是否起作用 , 如何更好的平衡算法的公平与效率仍是需要我们不断思考的问题 。
参考文献
Bolukbasi, T., Chang, K. W., Zou, J. Y., Saligrama, V., & Kalai, A. T. (2016). Man is to computer programmer as woman is to homemaker? debiasing word embeddings. Advances in neural information processing systems, 29, 4349-4357.
Zhao, J., Wang, T., Yatskar, M., Ordonez, V., & Chang, K. W. (2017). Men also like shopping: Reducing gender bias amplification using corpus-level constraints. arXiv preprint arXiv:1707.09457.
_原题《算法习得并强化了人类偏见吗——如何测量、分析算法中的偏见》
阅读原文
推荐阅读







- 产品|字节入局音乐流媒体,“算法推荐”会带来新“鲶鱼效应”吗?
- 技术|中电兴发:公司的多种数据算法技术处于业界领先水平并得到大量商用
- 方面|梁正:算法治理应关注技术使用过程及产生的影响
- 经济|崔鹏:对算法监管需秉持友好理念
- 数据|陈昌凤:应在善用算法的同时警惕数据主义
- 模式|首个基于时序平移的视频迁移攻击算法,复旦大学研究入选AAAI 2022
- 隐私|戴思源:提升公众专用智能素养 可建立算法技术信任
- 算法|曾毅:企业算法伦理与应用要做到知行合一
- 算法|李伦:算法伦理是企业数字责任的核心
- 起点|陈玲:将算法治理的“可接受公平”框架落到实处