机器之心专栏
复旦大学姜育刚团队
复旦大学开展针对视频模型中对抗样本迁移性的研究 , 以促进视频模型的安全发展 。近年来 , 深度学习在一系列任务中(例如:图像识别、目标识别、语义分割、视频识别等)取得了巨大成功 。 因此 , 基于深度学习的智能模型正逐渐广泛地应用于安防监控、无人驾驶等行业中 。 但最近的研究表明 , 深度学习本身非常脆弱 , 容易受到来自对抗样本的攻击 。 对抗样本指的是由在干净样本上增加对抗扰动而生成可以使模型发生错误分类的样本 。 对抗样本的存在为深度学习的应用发展带来严重威胁 , 尤其是最近发现的对抗样本在不同模型间的可迁移性 , 使得针对智能模型的黑盒攻击成为可能 。 具体地 , 攻击者利用可完全访问的模型(又称白盒模型)生成对抗样本 , 来攻击可能部署于线上的只能获取模型输出结果的模型(又称黑盒模型) 。 此外 , 目前的相关研究主要集中在图像模型中 , 而对于视频模型的研究较少 。 因此 , 亟需开展针对视频模型中对抗样本迁移性的研究 , 以促进视频模型的安全发展 。
文章图片
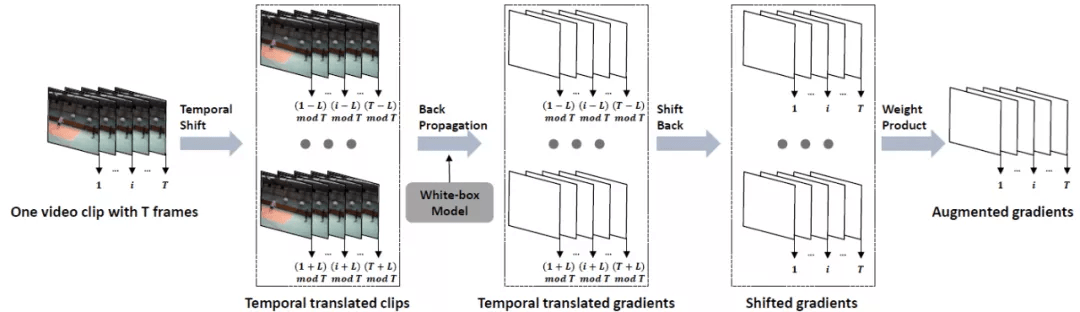
时序平移攻击方法
与图片数据相比 , 视频数据具有额外的时序信息 , 该类信息能够描述视频中的动态变化 。 目前已有多种不同的模型结构(例如:Non-local , SlowFast , TPN)被提出 , 以捕获丰富的时序信息 。 然而多样化的模型结构可能会导致不同模型对于同一视频输入的高响应区域不同 , 也会导致在攻击过程中所生成的对抗样本针对白盒模型产生过拟合而难以迁移攻击其他模型 。 为了进一步剖析上述观点 , 来自复旦大学姜育刚团队的研究人员首先针对多个常用视频识别模型(video recognition model)的时序判别模式间的相似性展开研究 , 发现不同结构的视频识别模型往往具有不同的时序判别模式 。 基于此 , 研究人员提出了基于时序平移的高迁移性视频对抗样本生成方法 。

文章图片
- 论文链接:https://arxiv.org/pdf/2110.09075.pdf
- 代码链接:https://github.com/zhipeng-wei/TT
在图像模型中 , 常常利用 CAM(Class activation mapping)来可视化模型对于某张图片的判别区域 。 然而在视频模型的判别模式由于额外的时序维度而难以可视化 , 且难以在不同模型间进行比较 。 为此 , 研究人员定义视频帧的重要性排序作为视频模型的时序判别模式 。 如果两个模型共享相似的时序判别模式 , 那么视频帧重要性的分布会更加相似 。
推荐阅读







- 平板|MIUI 13推出无字模式,内测机型名单公布
- 模式|荣耀60和iQOO Neo5S,全面对比告诉你谁更值得买
- 商汤|商汤终成AI第一股:挂牌联交所后股价高开 业内人士更关注其盈利和商业模式
- 数据|天问一号火星离子与中性粒子分析仪首个成果面世
- 材料|真我 GT2 Pro 预热:50MP 舰双主摄、realme 首个显微镜镜头
- 疫苗|国内首个自主研发四价流脑疫苗正式获批
- Xiaomi|小米公布小米12基于Android 12的全系内核源码
- 画质|AMD RSR 分辨率缩放技术曝光:基于 FSR,无需游戏适配即可使用
- 启发|小米 MIUI 13 无字模式开启内测,去除桌面应用名称显示
- 样本|国内首个在库运行超百万份生物样本全自动化库落户广州