下图是 3 个知识性任务的示例 , 实验表明这 3 种任务均能有效地引入知识 , 在下游的知识性任务中带来不错的提升 。

文章图片
优化避免参数遗忘
通过知识性任务能够驱动预训练模型学习到相关的参数 , 但也很容易造成原参数遗忘和模型通用能力的下降 。 常见的解决参数遗忘的做法是针对输入的知识性语料 , 训练 MLM 任务和知识性任务 。
这种做法虽然减缓了参数遗忘 , 但由于知识性语料较为单一和规整 , 引入 MLM 也无法避免模型在通用场景中效果变差 。 针对这个问题 , 团队引入了双路语料输入的机制 , 将通用预训练语料和知识性任务语料组合为双路输入 , 共享模型 Encoder 参数 , 进行联合训练 。 这样做既保证了 MLM 任务的语料输入的多样性 , 又减少了知识性任务都是较规整的百科语料对模型的影响 。
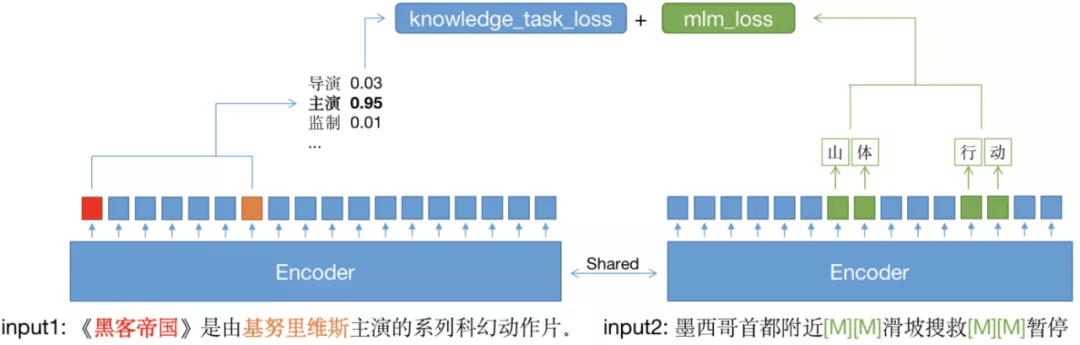
文章图片
实验结果表明 , 采用双路输入比只在百科语料中做联合学习在多个下游任务中平均有超过 0.5% 的提升 。 在引入双路输入后 , 上面提到的 3 个知识性任务均能给预训练模型在下游任务中带来提升 。 其中 , 远监督关系分类、三元组 - 文本 Mask 预测任务能在阅读理解类任务的 EM 指标上上平均提升 0.7%;在自然语言推理类任务上 , 则有 0.15% 到 0.3% 不等的提升 。
结语
当前「神舟」已经逐步应用于 QQ 浏览器的搜索、看点资讯、小说等多个场景 。 随着神舟的进一步完善和结合业务的实践 , 也将进一步改造 QQ 浏览器的搜索能力 , 理解用户表达背后需求 , 最智能的满足用户意图、深度服务用户 。
推荐阅读


- 安全|Redline Stealer恶意软件:窃取浏览器中存储的用户凭证
- 水管|柔性泄水管概述、性能参数
- 地球|马斯克否认“星链”占用地球空间轨道:能容纳数百亿颗卫星
- SpaceX|马斯克否认“星链”占用地球空间轨道:能容纳数百亿颗卫星
- 人物|马斯克否认星链卫星挤占太空空间:地球低轨道能容纳几百亿颗卫星
- 多多|小米 12 系列开售,拼多多百亿补贴领券最高直降 300 元
- 镜面|耗资百亿美元、花费25年建造的韦伯太空望远镜终于升空!与哈勃有何不同?
- 参数|CELL+100 细胞制备隔离器,欢迎咨询
- Microsoft|微软丰富Edge浏览器功能 引入游戏面板
- 海豚计划|来真的!网易有道词典“海豚计划”百亿流量亿元现金全力扶持知识创作者