- 行业高效解决方案 , 比如教育行业的题库理解、车载对话场景等;
- 辅助标注 , 在审核、客服、医疗问诊问答等领域 , 通过语义和知识减少不必要的人工交互和标注;
- 提升多模态场景的语义 , 优化多模态对齐效果 。
「神舟」借鉴了摩天模型的大量基础训练数据 , 包括企鹅号、小说、各类百科、新闻、社区问答等内容 。 并在此基础上额外引入了大量互联网网页数据 , 经过精准清洗优化 , 在数据量保障的前提下同时避免低质数据导致的模型漂移 。
自蒸馏预训练算法
知识蒸馏(Knowledge Distillation)指的是将训练好的教师模型(Teacher Model)的知识通过蒸馏的方式迁移到学生模型(Student Model) , 以提升学生模型的效果 , 往往学生模型参数量较小 。 而与知识蒸馏不同的是 , 自蒸馏(Self-Distillation)则指的是模型参数量不变 , 通过自己蒸馏到自己来不断提升自己的效果 。
目前在 CV 和 NLP 领域 , 自蒸馏技术已经得到广泛的应用 , 并且也验证了其效果的普适性 。 而在预训练中 , 标准的自蒸馏技术并没有很好地得到广泛的应用 , 原因主要在于预训练过程中非常消耗时间和资源 , 而标准的自蒸馏技术需要经历几次的模型训练、预测和蒸馏过程才能有比较好的效果提升 , 这非常消耗时间 , 显然不太适合预训练 。
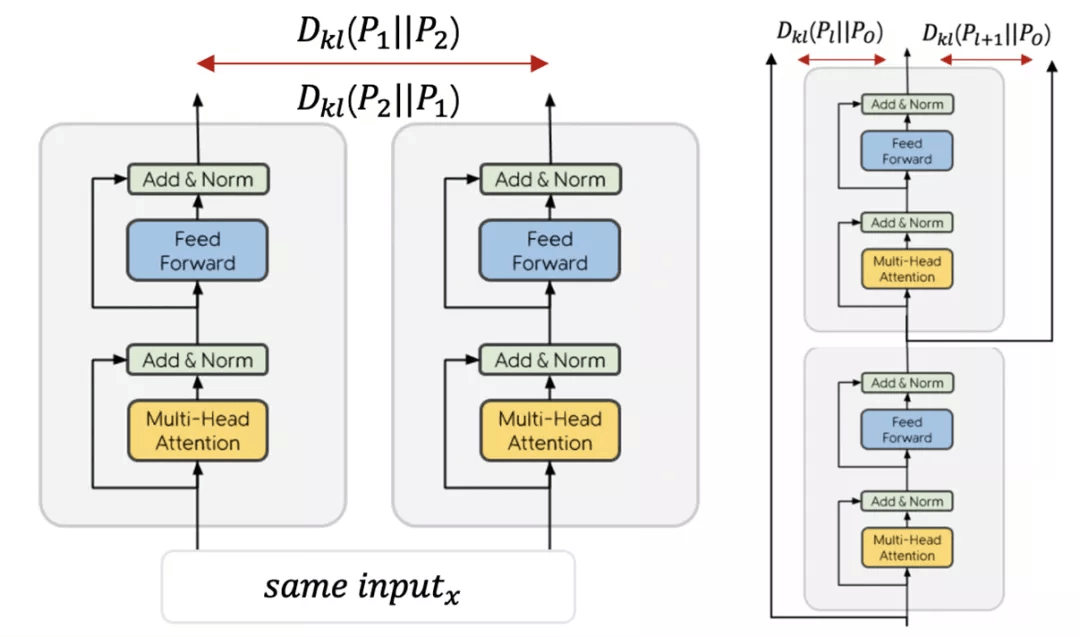
受 ALBEF 的动量蒸馏技术以及 r-drop(ICLR2021) 技术启发 , QQ 浏览器实验室团队探索了 layer-wise 和 instance-wise 自蒸馏在预训练模型上的应用 , 期望在尽量减少时间和资源消耗的情况下 , 在训练过程中在线进行自蒸馏 , 达到快速提升模型效果的目的 。 实验效果证明 , 两种方式对下游任务都有普适性的提升 , 其中 instance-wise 自蒸馏效果表现更优 , 但是对显存的消耗也会较高 。
其中下图左为 layer-wise 自蒸馏技术 , 在训练过程中使用每一层的输出蒸馏最后模型的输出来不断提升模型性能;下图右则为 instance-wise 自蒸馏技术 , 利用 dropout 的随机性 , 对于同样的输入可以产出两个不同输出 , 在线自己蒸馏自己 , 快速提升效果 。
文章图片
引入知识图谱增强预训练增强知识理解能力
预训练模型对于真实世界的知识理解 , 需要更多的知识『投喂』 , 业界对于预训练引入知识也是多有探索 。 「神舟」同样在知识增强方面做了进一步深度优化:基于搜索构建的知识图谱数据及百科语料 , 团队尝试了 3 种知识性任务——远监督关系分类、同类实体替换预测和三元组 - 文本 Mask 预测 。
推荐阅读







- 安全|Redline Stealer恶意软件:窃取浏览器中存储的用户凭证
- 水管|柔性泄水管概述、性能参数
- 地球|马斯克否认“星链”占用地球空间轨道:能容纳数百亿颗卫星
- SpaceX|马斯克否认“星链”占用地球空间轨道:能容纳数百亿颗卫星
- 人物|马斯克否认星链卫星挤占太空空间:地球低轨道能容纳几百亿颗卫星
- 多多|小米 12 系列开售,拼多多百亿补贴领券最高直降 300 元
- 镜面|耗资百亿美元、花费25年建造的韦伯太空望远镜终于升空!与哈勃有何不同?
- 参数|CELL+100 细胞制备隔离器,欢迎咨询
- Microsoft|微软丰富Edge浏览器功能 引入游戏面板
- 海豚计划|来真的!网易有道词典“海豚计划”百亿流量亿元现金全力扶持知识创作者