机器之心发布
作者:腾讯QQ浏览器实验室
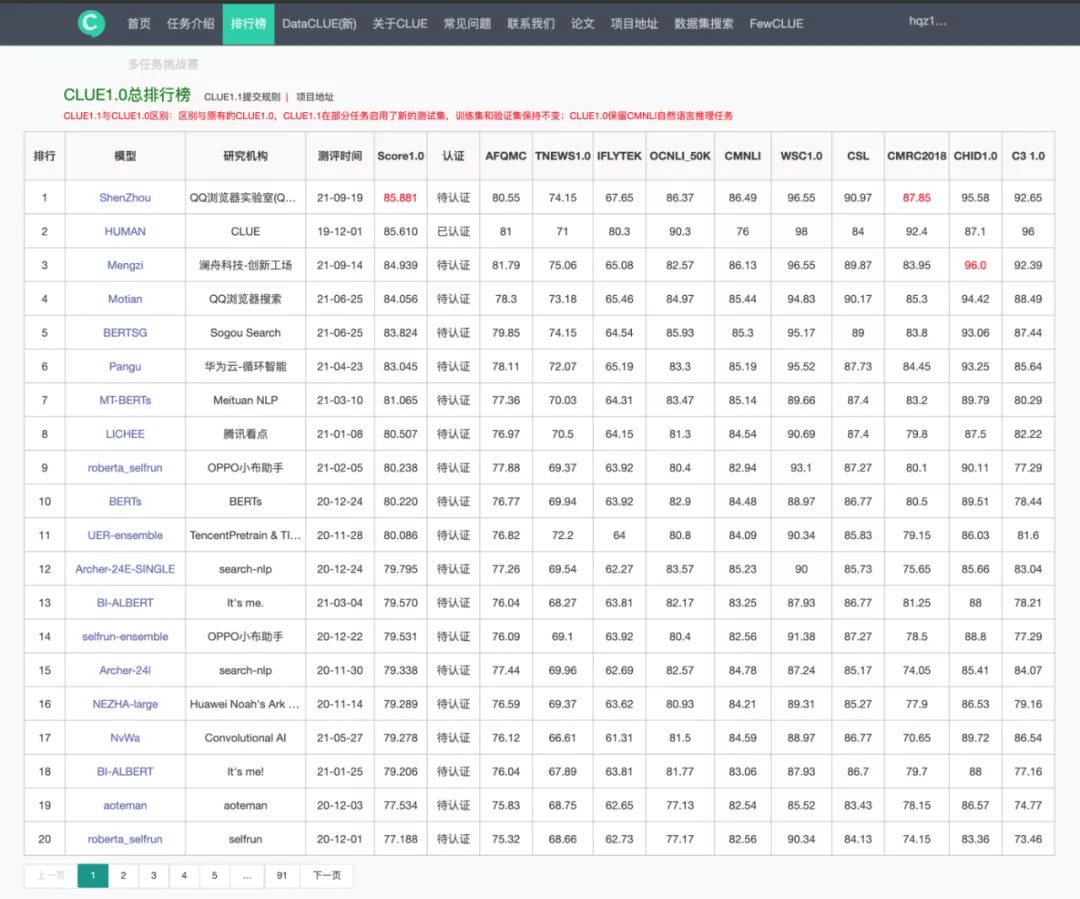
近日 , 腾讯 QQ 浏览器实验室研发的预训练模型「神舟」(Shenzhou)在 9 月 19 日的中文语言理解评测 CLUE 榜单上登顶 , 刷新业界记录 , 成为首个在中文自然语言理解综合评测数据上超过人类水平的预训练模型 。
文章图片
作为中文语言理解领域最具权威性的测评基准之一 , CLUE 涵盖文本相似度、分类、自然语言推理、阅读理解等 10 项语义分析和理解类子任务 。 QQ浏览器“神舟”模型凭借顶尖的语言理解能力 , 登顶 CLUE1.0 总榜单 / 分类榜单 / 阅读理解榜 , 刷新三项榜单世界纪录 。 总排行榜分数突破 85.88 分 , 超过人类基准分数0.271 。
构建出百亿参数量级的「神舟」1.0 模型
【浏览器|百亿参数、中文NLU能力首次超越人类,QQ浏览器大模型神舟登顶CLUE】自然语言处理和理解(NLP&NLU)是内容领域的一项核心能力 , 也是 AI 领域持久不衰的核心方向 , 应用范围涵盖了搜索、推荐、商业算法以及更多 AI 领域的方方面面 。
在当前的学术界和工业界 , 预训练(pretrain)+ 微调(finetune)+ 蒸馏(distill)应用的模式 , 已经成了一种新的语义理解范式 。 BERT 作为预训练的基础模型已经被大量应用在相关算法技术上 , 在此基础上 , 拥有一个更好更优质的预训练模型可以为所有的语义理解能力带来更强的天花板 。
「神舟」自然语言预训练模型是由腾讯 QQ 浏览器实验室于 2021 年自研的成果 。 通过联合腾讯 QQ 浏览器搜索和内容算法团队 , 在 6 月登顶 CLUE 的摩天预训练模型基础上进一步进行了大量创新:引入跨层衰减的 Attention 残差链接算法、并将 instance-wise 的自蒸馏技术引入到预训练模型的训练中 , 以及自回归的 MLM 训练策略等 。 同时 , 在此基础上通过二次预训练的方式进行知识增强 , 进一步提高预训练模型效果 。
大规模深度学习模型的效果在各方面获得了成功 , 但是训练一个百亿的双向自编码模型一直是一个挑战 。 「神舟」模型通过 ZeRO 分割方案 , 将百亿模型分割到 N 张卡上 , 并结合 FP16 训练、梯度检查进一步降低显存使用 。 底层通信将 TCP 改为 GPUDirect RDMA 通信 , 大大提高了通信效率 , 并进一步通过梯度聚集算法减少通信量 。
最终 , QQ 浏览器实验室通过业界领先的训练能力 , 最终训练得到了神舟 - 百亿参数量的双向自编码预训练模型 。 通过「神舟」预训练的能力 , 仅需要沿用该范式更新模型 , 即可在几乎所有的语义类理解任务上提升模型效果 , 有极大的适用性;其次 , 「神舟」预训练能力作为多模态预训练的基础 , 帮助提升多模态预训练的综合效果 , 提升视频理解多模态预训练的综合效果;同时神舟还基于腾讯现有的中台二次输出 , 进一步扩大辐射范围 。
推荐阅读







- 安全|Redline Stealer恶意软件:窃取浏览器中存储的用户凭证
- 水管|柔性泄水管概述、性能参数
- 地球|马斯克否认“星链”占用地球空间轨道:能容纳数百亿颗卫星
- SpaceX|马斯克否认“星链”占用地球空间轨道:能容纳数百亿颗卫星
- 人物|马斯克否认星链卫星挤占太空空间:地球低轨道能容纳几百亿颗卫星
- 多多|小米 12 系列开售,拼多多百亿补贴领券最高直降 300 元
- 镜面|耗资百亿美元、花费25年建造的韦伯太空望远镜终于升空!与哈勃有何不同?
- 参数|CELL+100 细胞制备隔离器,欢迎咨询
- Microsoft|微软丰富Edge浏览器功能 引入游戏面板
- 海豚计划|来真的!网易有道词典“海豚计划”百亿流量亿元现金全力扶持知识创作者