识别|避免自动驾驶事故,CV领域如何检测物理攻击?(16)
3.1.2 攻击检测
攻击检测需要两个步骤 。 首先 , 如上所述 , SentiNet 提取可能包含对抗性补丁的输入区域 。 然后 , SentiNet 在一组良性图像上测试这些区域 , 以区分对抗性区域和良性区域 。
测试- 一旦定位了输入区域 , SentiNet 就会观察该区域对模型的影响 , 以确定该区域是对手的还是良性的 。 为此 , SentiNet 将可疑区域叠加在一组良性测试图像 X 上 。 将测试图像反馈到网络中 , 网络计算被欺骗的样本数量并用于对抗性图像 。 直观地说 , 可能欺骗模型的变异图像数量越多 , 疑似区域就越有可能是对抗性攻击 。 当恢复的掩模较小时 , 这种反馈技术能有效区分对抗性和良性输入 , 因为小的良性物体通常不能影响到网络的预测 。 然而 , 这种方法的一个问题是 , 一个覆盖了输入图像较大区域的掩模在叠加到其他图像上时 , 很可能会造成错误的分类 。 例如 , 考虑一个输入图像 x 的较大掩模 , 当叠加时 , 掩模内的特征可能比外面的特征相关性更强 , 这就提高了将变异的测试输入分类为 y 的可能性 。 为了解决这一问题 , 作者引入了惰性模式(inert patterns) , 其作用是抑制掩模内部的特征 , 从而提高网络对掩模外特征的反应 。
检测的决策边界- 有了这两个指标(被欺骗的图像数量和平均惰性模式置信值) , 我们可以确定在哪些条件下输入的 x 是对抗性的 。 下一步 , 作者希望引入一种技术 , 使我们能够根据攻击无关的指标 , 将未见过的对抗性输入识别为攻击 。 图 12 给出一个示例 , 其中红色的三角点代表的是在对抗性样本中发现的指标 , 蓝色的圆点是根据清洁样本计算得到的 。 我们可以看到对抗性样本大多聚集在图中右上角的位置 。
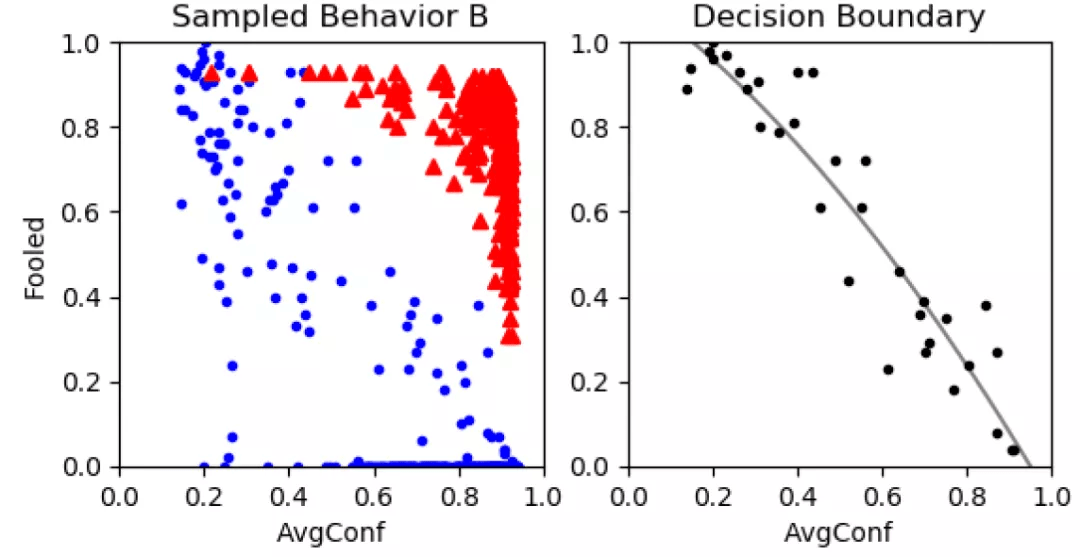
文章图片
图 12. 边界检测示例 , 左侧 , 对抗性和良性指标分别被绘制成红色三角形和蓝色圆圈;右侧 , 来自采样点的曲线建议
作者提出 , 可以使用在清洁样本上收集到的度量来近似一个曲线 , 其中位于曲线函数之外的点可以被归类为对抗性攻击 。 具体的 , 通过提取 x 间隔的最高 y 值的点来收集目标点 , 然后使用非线性最小二乘法函数来拟合生成目标曲线 。 然后 , 使用近似曲线计算曲线和点之间的距离(使用线性近似的约束优化(the Constrained Optimization by Linear Approximation , COBYLA)方法)并确定该距离是否在由位于曲线之外的清洁样本的距离所估计的阈值之内 , 来实现对攻击的分类 。 具体的边界决策过程如 Algorithm 4 所示 。

推荐阅读







- 识别|外卖界又一黑科技 饿了么计划2022年覆盖100000顶智能头盔
- 语言识别|AI技术,让我们“听”懂聋人
- AI财经社|美团公布共享单车指纹解锁专利,网友调侃称期待人脸识别解锁
- Huawei|传大众与华为成立合资自动驾驶技术公司 回应称现阶段没有可以确认的消息
- 视点·观察|如何避免社交电商以“经销之名”行“传销之实”
- 模式|华为拍摄月亮专利获授权:可自动识别月亮并对焦
- 广西|秒级核验通行,广西机场推广刷身份证自动核验健康码
- 澎湃新闻|如何避免社交电商以“经销之名”行“传销之实”
- IT|达拉斯希望成为福特下一个自动驾驶汽车工厂的所在地
- 界面新闻|华为月亮拍摄专利获授权,可自动识别月亮并对焦