识别|避免自动驾驶事故,CV领域如何检测物理攻击?(13)
文章图片
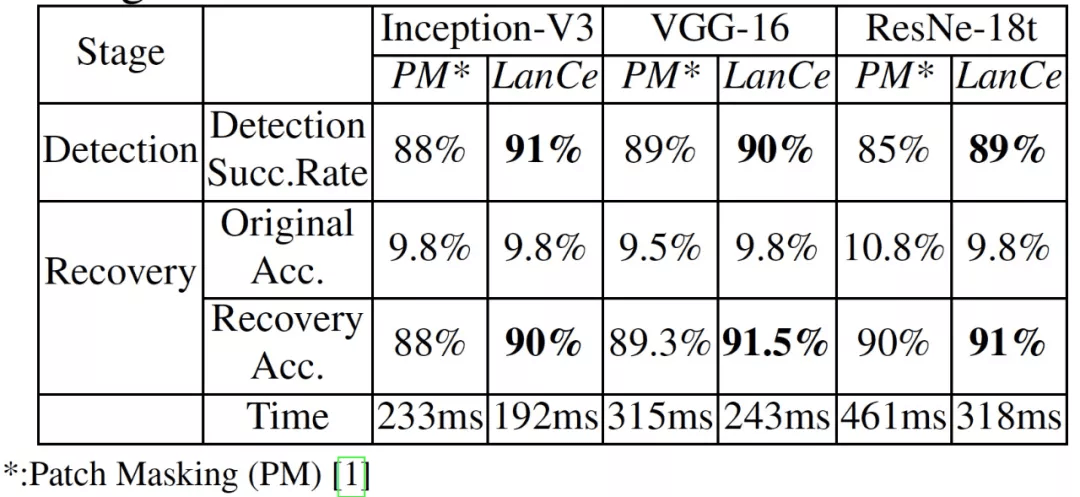
表 7. 图像对抗性补丁攻击防御评估
2.4.2 音频场景
对于音频场景 , 作者在谷歌语音命令数据集上使用命令分类模型(Command Classification Model)进行实验 。 对抗性检测的不一致性阈值是通过网格搜索得到的 , 在本实验中设置为 0.11 。 作为比较 , 作者重新实现了另外两种最先进的防御方法:Dependency Detection [8]和 Multiversion[9] 。
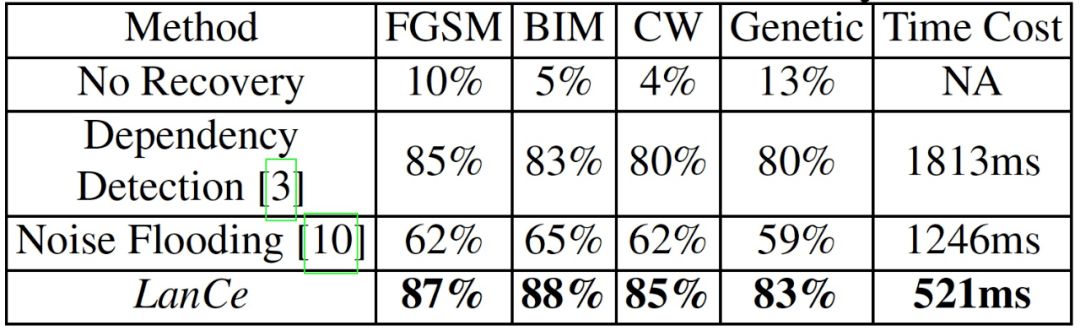
LanCe 对所有的音频物理对抗性攻击都能达到 92% 以上的检测成功率 。 相比之下 , Dependency Detection 平均达到 89% 的检测成功率 , 而 Multiversion 的平均检测成功率只有 74% 。 然后 , 作者评估了 LanCe 的恢复性能 。 TOP-K 指数中的 K 值被设定为 6 。 由于 Multiversion[9]不能用于恢复 , 作者重新实现了另一种方法 Noise Flooding[10]作为比较 。 作者使用没有数据恢复的原始 CNN 模型作为基线方法 。
表 8 给出了整体的音频恢复性能评估 。 应用本文提出的恢复方法 LanCe 后 , 预测准确率明显提高 , 从平均 8% 提高到了平均 85.8% , 即恢复准确率为 77.8% 。 Dependency Detection 和 Noise Flooding 的平均准确率都较低 , 分别为 74% 和 54% 。
文章图片
表 8. 音频对抗性攻击数据恢复评估
3、SentiNet:针对深度学习系统的物理攻击检测[3]

文章图片
这篇文章重点关注的是图像处理领域的物理攻击检测问题 , 具体是指针对图像的局部物理攻击 , 即将对手区域限制在图像的一小部分 , 生成 “对抗性补丁” 攻击 。 这种局部限制有利于设计鲁棒的且物理上可实现的攻击 , 具体攻击形式可以是放置在视觉场景中的对手对象或贴纸 。 反过来 , 这些类型的攻击通常使用无界扰动来确保攻击对角度、照明和其他物理条件的变化具有鲁棒性 。 局部物理攻击的一个缺点是 , 它们通常是肉眼可见和可检测的 , 但在许多情况下 , 攻击者仍然可以通过在自主环境中部署或伪装这些方式来逃避检测 。
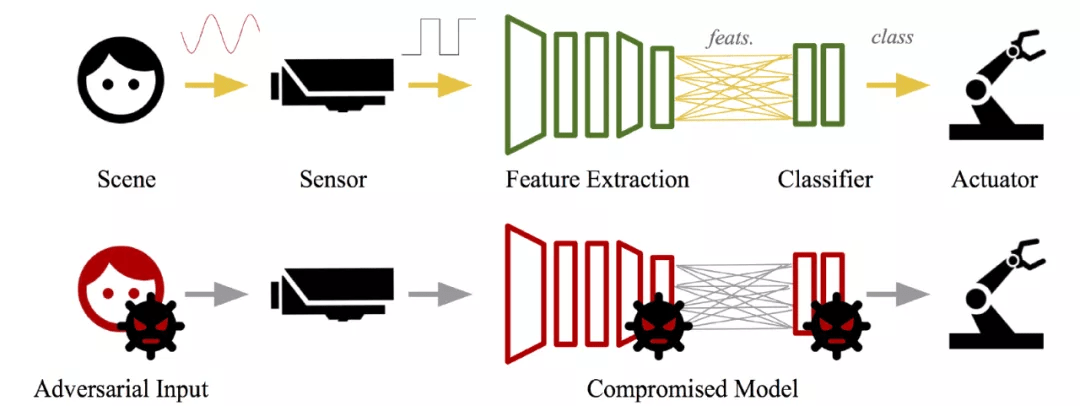
图 9 给出一个深度学习系统示例 , 该系统为人脸识别系统 , 其作用是解锁移动设备或让用户进入建筑物 。 场景包括了用户的脸和其他背景对象 。 传感器可以是返回场景数字图像的相机的 CCD 传感器 。 图像由预测用户身份的人脸分类器处理 。 如果用户身份有效 , 执行器将解锁设备或打开闸门 。
文章图片
图 9. 部署在真实环境中的物理攻击 , 使用物理模式和对象而不是修改数字图像
推荐阅读





- 识别|外卖界又一黑科技 饿了么计划2022年覆盖100000顶智能头盔
- 语言识别|AI技术,让我们“听”懂聋人
- AI财经社|美团公布共享单车指纹解锁专利,网友调侃称期待人脸识别解锁
- Huawei|传大众与华为成立合资自动驾驶技术公司 回应称现阶段没有可以确认的消息
- 视点·观察|如何避免社交电商以“经销之名”行“传销之实”
- 模式|华为拍摄月亮专利获授权:可自动识别月亮并对焦
- 广西|秒级核验通行,广西机场推广刷身份证自动核验健康码
- 澎湃新闻|如何避免社交电商以“经销之名”行“传销之实”
- IT|达拉斯希望成为福特下一个自动驾驶汽车工厂的所在地
- 界面新闻|华为月亮拍摄专利获授权,可自动识别月亮并对焦