作者:网易伏羲实验室人工智能研究员 本座
NeurIPS 2020 文章专题
第·11·期
奖赏塑形 (Reward Shaping) 是提升强化学习算法学习效率的重要途径之一 , 其核心思想是用塑形奖赏函数 (Shaping Reward Function) 表达先验知识 , 避免不必要的探索 。 目前的大多数奖赏塑形方法都不加甄别地使用塑形奖赏 , 忽略了其中是否存在不完美甚至是谬误的地方 。
本文是 网易伏羲实验室、 天津大学和 中国科学与技术大学的研究者发表于 NeurIPS 2020的一项工作 , 提出了一种能够自适应地利用给定塑形奖赏、有效甄别其好坏的新型奖赏塑形方法 。
「NeurIPS 2020群星闪耀云际会·机构专场」 圆满结束 , 公众号【将门创投】后台回复“ NeurIPS” , 获取完整版回顾视 频及pdf资源!

文章图片
1. 引 言
奖赏塑形 (Reward Shaping)是提升强化学习算法学习效率的重要途径之一 , 其核心思想是用塑形奖赏函数 (Shaping Reward Function)表达先验知识 , 避免不必要的探索 。
然而 , 将规则性的知识转化为算法能够理解的数值奖励通常会涉及一些人工操作 , 因而往往也会将人的认知偏差引入其中 。 目前的大多数奖赏塑形方法都不加甄别地使用塑形奖赏 , 忽略了其中是否存在不完美甚至是谬误的地方 。
在本文中 ,网易伏羲实验室、 天津大学和 中国科学与技术大学的研究者尝试解决上述问题 ,提出了一种能够自适应地利用给定塑形奖赏、有效甄别其好坏的新型奖赏塑形方法 。 其主要贡献包括:
2. 背景和相关工作
随着强化学习 (Reinforcement Learning , RL), 尤其是深度强化学习 (Deep RL) 的蓬勃发展以及它在游戏AI领域显现的巨大应用潜力 , 越来越多的游戏厂商开始在游戏中进行这项技术的落地 。 强化学习在实际项目的应用中面临着稀疏奖励问题 (Sparse Reward Problem) 的挑战 , 在游戏中也不例外 。 在游戏中 , 如果没有人为设计的奖励信号 , 一般只能将一局游戏胜负作为奖励信号提供给学习算法 , 而仅仅靠这样的奖励信号很难学习到好的策略 。 因此 , 通常研究者都会根据自己的经验和对游戏环境的认知 , 人为设计一些奖励来辅助学习算法 。 这种将先验知识转化为附加奖励函数 , 从而引导学习算法学得更快、更好的方式 , 就叫做奖赏塑形 (Reward Shaping) 。 奖赏塑形的应用案例非常多 , 例如文献[1]在训练VizDoom机器人时 , 就设计了若干种奖励 (捡物品奖励、射击奖励、掉血惩罚、掉护甲惩罚等) 来辅助训练 。
总的来说 , 奖赏塑形是提升强化学习算法学习效率的重要途径之一 , 其核心思想是用附加奖赏函数 (也叫塑形奖赏函数 , Shaping Reward Function)表达先验知识 , 避免不必要的探索 。 关于奖赏塑形能够加速学习的理论层面的原因 , 可以参考文献[2]和[3] 。
尽管如此 , 研究者在具体应用奖赏塑形方法的时候还是会遇到一些棘手的问题 , 比如:如何设置附加奖赏的大小?什么样的奖赏尺度才能够保证既能够加速学习又不削弱原有奖励的影响?如果附加奖赏函数设置得不好影响了学习效果怎么办?正是因为没有一些通用的法则去指导怎么设置塑形奖励 , 研究者往往会在一个问题或项目中反复尝试若干种奖赏塑形方案 (俗称:调reward), 直到取得比较好的学习效果 。 即便用上了奖赏塑形方法 , 也还是免不了要人工调节奖励大小 , 带来较大的人力和算力的消耗 。 此外 , 现有的奖赏塑形方法 (如[4]、[5]、[6]) 还存在一个问题 , 即:完全信任给定的附加奖赏函数 , 不加甄别地使用塑形奖赏而不管其对应的先验知识是否存在不完美甚至是谬误的地方 。
2.1 奖赏塑形
本文假设读者已经具备一些强化学习基础知识 , 所以直接从奖赏塑形相关背景开始介绍 。 给定一个马尔可夫决策过程 (MDP), 奖赏塑形是指在奖赏函数加一个附加奖励函数 , 从而得到一个修正的奖赏函数 和修正的马尔可夫决策过程。 可以看到 , 和 只有奖赏函数有所不同 , 其他组成部分均一致 。 显然 , 由于 和 的奖赏函数不同 , 它们各自的最优策略很可能也不相同 。 但如果原有问题的最优策略发生了改变 , 那么添加塑形奖赏就失去了意义 。
因此 , 有很多工作关注于如何保持策略不变性 (policy invariance), 即如何使得 的最优策略也是原有问题 的最优策略 。 这其中最经典的工作当属Andrew Ng所提出的基于势函数的奖赏塑形方法 (Potential-based Reward Shaping , PBRS) [7] 。 其核心思想是将附加奖励函数 表达为势函数的差分形式:
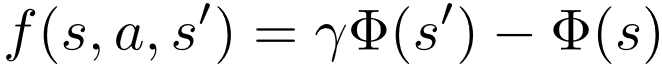
文章图片
其中 , 是定义在状态空间 上的势函数 。 不难证明 , 对于任意势函数, 具有这种差分形式的附加奖励函数 不会影响相同状态上不同动作的值函数大小关系 , 也就不会改变原有问题的最优策略 。 读者们也可以参照文献[7]中的证明自行推导一遍 。
至于为什么PBRS能够对学习起到促进作用 , 已有相关研究者从值函数初始化[2]和缩小奖赏范围 (reward horizon) [3]的角度进行了理论层面的分析 。 PBRS方法只是将势函数定义在状态空间上 , 其后续的一些工作还尝试 (但不限于)
需要指出的是 , 基于势函数的奖赏塑形方法虽然能够保证策略不变性 (policy invariance , 即附加奖励函数不改变原有问题的最优策略), 但仍然无法解决这个问题 。 原因有二:
2.2 相关工作
以上这些工作研究的重点还是如何保证奖赏塑形方法的策略不变性 。 但随着深度强化学习的发展以及越来越复杂的实际问题的出现 , 近年来的一些奖赏塑形方面的工作更多地关注如何让学习算法学得更好 , 如:基于信念的奖赏塑形方法[9]、基于元学习的奖赏塑形方法[10]、塑形奖赏函数自动选择框架[11]等 。
这是因为 , 策略不变性更多地只是一种期望的目标 , 并不是能够引导学习算法学到最优策略的方法 。 况且 , 在函数近似 (function approximation) 的设置下 , 即便能够保证策略不变性 , 学习算法也没有百分百的保证能够学习到最优或者局部最优策略 。
同样是考虑如何通过引入新的奖励来促进学习 , 基于内部奖赏 (Intrinsic reward) 的强化学习方法在最近几年也受到了极大的关注 。 其核心思想是自动学习一个内部奖赏函数来促进探索 (如:ICM[12]、RND[13]), 或者直接让agent基于内部奖赏函数学习策略、同时根据外部奖赏 (extrinsic reward , 即环境真实奖赏) 对这个内部奖赏函数进行优化 。 其中 , 后者典型的代表就是最优奖赏框架系列方法 (Optimal Reward Framework) [14]-[17] 。
与本文工作最相似的应该是Deepmind发表在《Science》上的重要工作 (文献[18]), 该工作将内部奖赏函数的优化建模为双层优化问题 , 并采用演化计算的方法来求解该问题 。 除了求解双层优化的方法有所不同之外 , 本文和Deepmind的工作最大的不同还是在于解决的问题上 。
本文所要解决的问题是 , 在给定已有的塑形奖赏函数的情况下 , 学会识别其中好的部分和坏的部分 , 并选择性地加以利用 。 也就是说 , agent既要得到好的策略 , 又要得到一个关于已有奖赏函数的评价 。
3. 问题建模
给定一个马尔可夫决策过程 和塑形奖赏函数, 本文提出一种新形式的奖赏塑形方法——带参奖赏塑形 (parameterized reward shaping) , 即在原有加和形式的奖赏塑形方法中引入一个参数化的权重函数:
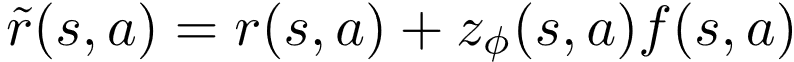
文章图片
(1)
其中 , 就是新引入的塑形权重函数 (shaping weight) , 其参数用 来表示 。 对于任意状态动作对,
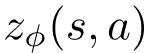
文章图片
表示利用对应塑形奖赏 的程度 。 请注意 , 带参奖赏塑形可以直接扩展到具有多个塑形奖赏函数的情况 。 但为了方便讨论 , 本文还是在只有一个塑形奖赏函数的情况下展开 。
用 来表示agent的策略 , 其中 表示策略函数的参数 。 带参奖赏塑形的学习目标实际上有两个方面:(1) 根据修正后的奖赏函数 优化agent的策略 ;(2) 根据 能够获得环境外部奖赏优化塑形权重函数。
首先 , 因为要利用先验知识 , 所以策略的优化一定是基于加了塑形奖赏后的信号 。 其次 , agent的最终目标依然是最大化环境真实的长期累积奖赏 , 所以需要根据环境真实奖赏来优化, 进而间接引导策略 往最大化真实奖赏的方向变化 。
下面开始介绍具体的优化方法 。 给定塑形奖赏函数 和塑形权重函数, 策略 的优化目标就是修正奖赏 (modified reward) 的长期累积值
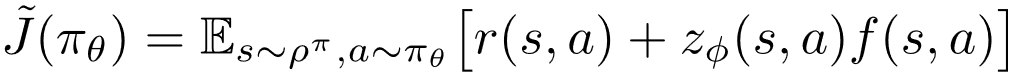
文章图片
(2)
根据上面的讨论 , 当给定 来优化 时 , 其优化目标为环境真实的长期累积奖赏
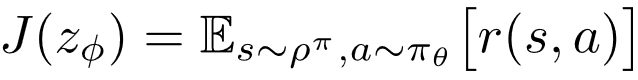
文章图片
(3)
将公式 (2) 和 (3) 综合起来 , 可以得到如下双层优化问题
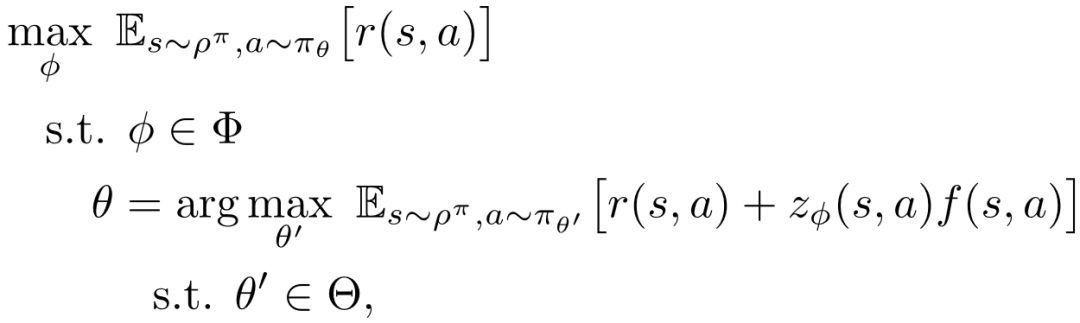
文章图片
(4)
上述优化问题被命名为带参奖赏塑形的双层优化问题 (Bi-level Optimization of Parameterized Reward Shaping , BiPaRS), 下文将用BiPaRS来代称 。 为了方便理解 , 这里给出BiPaRS框架的简单示意图 。
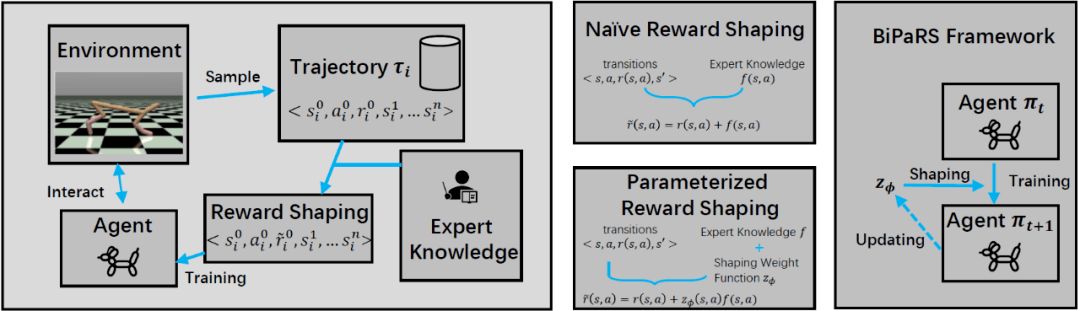
文章图片
BiPaRS框架示意图
4. 方 法
本文采用一种交替优化的方式作为求解公式 (4) 中双层优化问题的总体框架 , 即:在公式 (4) 的内层固定权重函数而优化策略 , 在外层固定策略而优化权重函数 。 显然 , 内层优化是一个典型的策略优化问题 , 可以采用任意一个策略梯度算法 (如:PPO、A2C、REINFORCE) 来优化策略 。 给定塑形权重函数, 根据策略梯度定理 (policy gradient theorem) [19]有
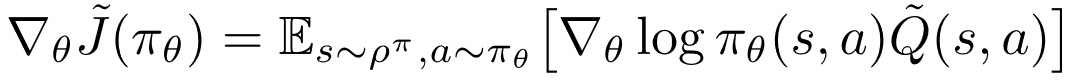
文章图片
(5)
在这里 , 表示策略 在修正MDP
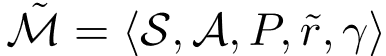
文章图片
中的状态动作值函数 。 相比于求解内层优化 , 外层优化问题的求解要稍微复杂一些 , 其关键在于计算真实累积奖赏关于塑形权重函数的参数的梯度 。 本文给出如下定理作为计算该梯度的基础:
定理1. 给定策略 和塑形权重函数, BiPaRS问题的外层优化目标 关于变量 的梯度为
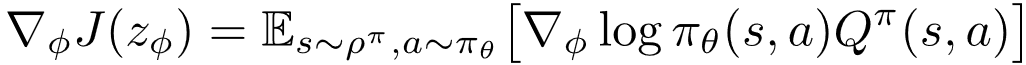
文章图片
(6)
该定理的证明类似于策略梯度定理的证明方法 , 证明过程请参考论文的附录 。 请注意 , 即便有了定理1 , 的值还是难以计算 , 因为 关于 的梯度没办法直接得到 。 接下来将给出几种近似计算 的方法 。
4.1 显式映射法 (Explicit Mapping , EM)
显式映射法的思路是:既然策略 与权重函数 之间不存在显式的函数关系 , 那就构造出这样的一种关系 , 让前者成为后者的一个函数 。 具体做法是重新定义agent的策略为, 其中 是在状态中加入塑形权重后的扩展状态空间 (extended state space)。 由于 直接作为了 的输入 , 则 可以简单地通过链式法则得到 , 即:
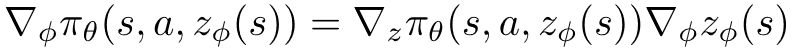
文章图片
对应地 , 可以得到使用显式映射法时的外层优化目标关于参数 的梯度
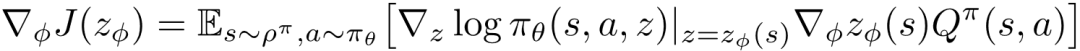
文章图片
(7)
关于该方法的合理性 , 请参考论文原文的4.1小节 。
4.2 元梯度学习法 (Meta-Gradient Learning , MGL)
元梯度学习法的思路是直接计算元梯度 的值 , 则通过链式法则可以得到。 给定, 令 和分别表示经过一次内层优化迭代之前和之后策略参数 。 不失一般性 , 假设从 更新到 所使用的样本集合为。 根据公式 (5) 可得
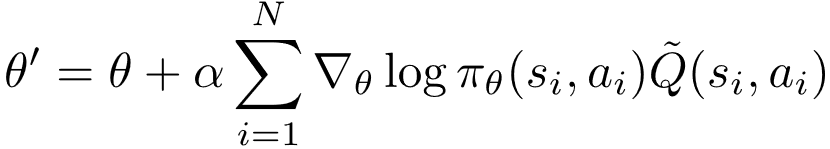
文章图片
(8)
在这里 , 表示策略更新的学习率 。 请注意 , 当策略参数从 更新到 之后 , 后者将会用来在外层优化中更新, 涉及 的计算 。 下文将 简化为, 则 可以如下计算:
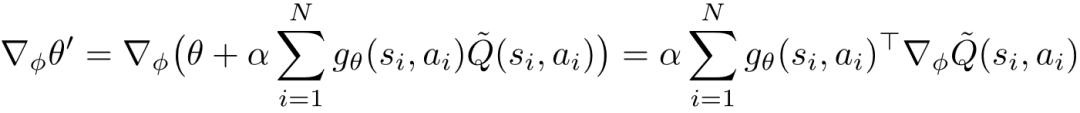
文章图片
(9)
这里将 视为关于 的常量 (因为 是更早一轮内层优化的结果), 所以接下来只需要考虑如何计算
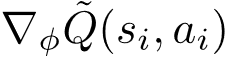
文章图片
。 实际上 , 在公式 (8) 中值函数 可以用它的任何一个无偏估计来取代 (如:Monte Carlo回报)。 对于样本集合 中的任意样本i , 令
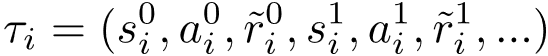
文章图片
表示以 为起始的采样轨迹 。 对于轨迹中的任意一个时间步 t , 有
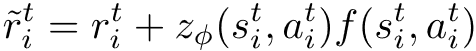
文章图片
, 其中 表示对应的环境真实奖励 。 因此 , 可以近似计算为
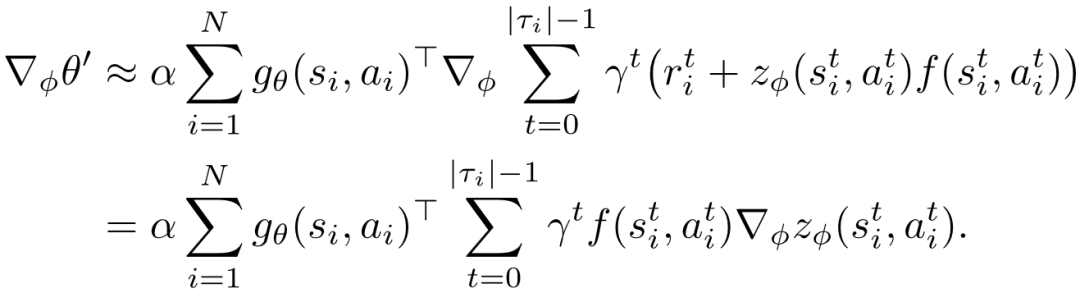
文章图片
(10)
根据之前的讨论 , 每当进行完一轮内层优化 , 进而开始进行外层优化时 , 就可以按照公式 (10) 计算出 并带入到 中 。
4.3 增量元梯度学习法 (Incremental Meta-Gradient Learning , IGML)
第三种方法增量元梯度学习法其实是元梯度学习法的更一般形式 。 在公式 (9) 中 , 策略参数 被看成是关于 的常量 。 实际上 ,也可以看作关于 的非常量 。 这是因为在上一轮的外层优化中 , 权重参数 是根据 采样出的奖赏值进行更新的 。 再者 , 策略参数和塑形权重参数是交替增量更的 , 所以它们都分别与对方的历史取值相关 。 所以 , 可以将公式 (10) 重写为
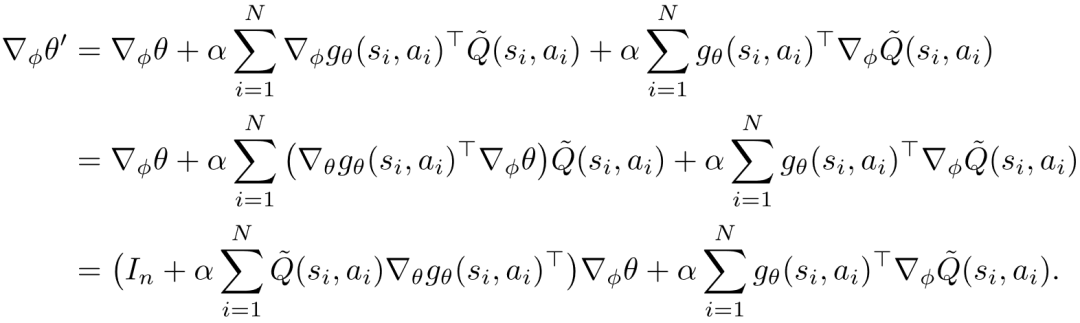
文章图片
(11)
在这里 , 是一个n阶单位矩阵 , 而n为 包含的参数个数 。 可以将策略参数关于 的元梯度初始化为一个零矩阵 , 然后按照公式 (11) 进行迭代式地更新 。 以上三种近似计算元梯度的方法在计算复杂度和近似精确程度之间做出了不同的权衡 , 论文的附录给出了三种方法的复杂度分析 。 最后 , 将上面的所有讨论总结为求解BiPaRS问题的完整算法 , 具体如下图所示:

文章图片
算法1. 求解BiPaRS的完整算法
忙了这么久 , 又快到周末啦!
, 加入我们的聚会
5. 实 验
5.1 小车立杆 (Cartpole)
本文首先在小车立杆实验Cartpole中验证所提出方法的正确性 , 即:这些方法能否正确识别给定塑形奖赏的好坏并选择性地加以利用 。 在Cartpole实验中 , agent需要对放置在小车上的立杆施加一个水平方向的力来保证它不会倒下 。 对于环境真实的奖励 , 采用的是一种稀疏奖励的设置:agent只会在立杆倒下时得到奖励-1 , 其余情况下agent收到的奖励为0 。
对于塑形奖励 , 首先采用一种有利于agent学习的设置:当agent施加的力的方向和减小立杆倾角的方向一致时 , agent将会得到0.1的奖赏 , 其余情况下塑形奖励为0 。 然后 , 将这种塑形奖励设置完全反过来 , 构造出一种对agent学习有害的设置:当agent施加的力的方向和减小立杆倾角的方向一致时 , agent将会得到-0.1的奖赏 , 其余情况下塑形奖励为0 。 实验将测试三种奖赏塑形方法在使用这两种完全相反的塑形奖励设置的情形下的表现 。
实验中采用的基础学习算法是PPO , 并在此基础上实现了本文提出的三种奖赏塑形方法:BiPaRS-EM、BiPaRS-MGL和BiPaRS-IGML 。 实验中采用的对比方法是naive shaping (NS) 方法和dynamic potential-based advice (DPBA) 方法[5] 。 其中 , NS方法是直接将塑形奖励加到原有环境真实奖励上 , 而DPBA方法能够将任意奖励转化为势函数值 (potential value) 进而基于势函数构造学习算法需要的塑形奖励 。
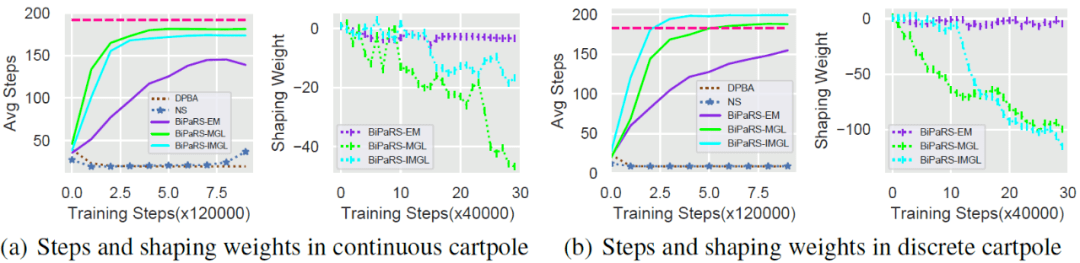
在连续动作空间Cartpole和离散动作空间Cartpole环境中分别进行了实验 , 每个方法的测试包含1,200,000个训练步 , 并且每训练4,000步将会进行一次包含20局 (episode) 的评估 (evaluation)。 每一次评估将会记录下被测方法在这20局中的每局平均步数 (average step per episode , ASPE)。 请注意 , 每局平均步数ASPE反映的是agent能够让立杆坚持多少步不倒 。 每一局的最大长度为200 , 这也就意味着ASPE的最高值是200 。
对于本文提出的三种方法 , 实验中也按照4,000的间隔记录下它们在所经历的状态动作上的平均塑形权重 , 以此反应塑形权重函数 在学习过程中变化情况 。 对于每个方法均采用了20个不同的随机种子进行测试 , 并将这些结果进行了平均 。 最终结果展示在图1和图2中 。
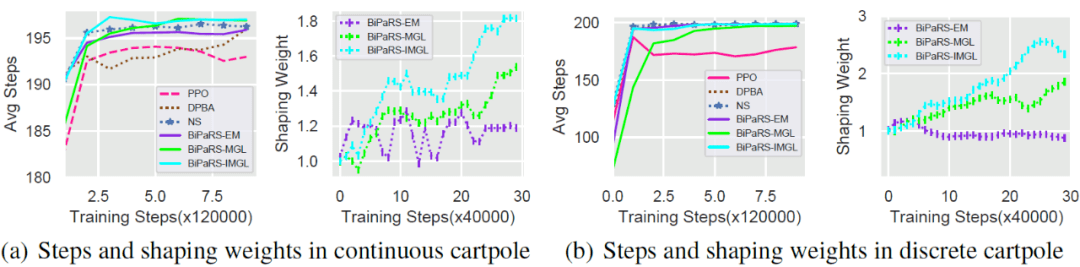
文章图片
图1. 有利塑形奖赏情形下连续动作空间和离散动作空间Cartpole任务中的实验结果
文章图片
图2. 有害塑形奖赏情形下连续动作空间和离散动作空间Cartpole任务中的实验结果
从图1可以看到 , 在有利的塑形奖励的帮助下 , 所有测试方法都能够改善PPO算法的学习性能 。 在连续动作空间Cartpole中 , PPO和奖赏塑形方法的性能差别还不算很大 。 但是在离散动作空间Cartpole中 , 可以看到PPO最终仅收敛到170步左右 , 而带奖赏塑形的方法基本上都收敛到了最高的200步 。
在图2中 , 本文的三种方法表现出了克服不利塑形奖励的能力 , 而另外两种baseline塑形方法则完全被塑形奖励所误导 , 其平均步数曲线基本保持在一个较低的值上 。 图2的两幅平均步数曲线图中的洋红色横线代表PPO在图1中所能达到的最高值 (因为PPO不受塑形奖励影响 , 所以画出来作为参考)。
通过考查图中的权重曲线 , 可以发现三种BiPaRS方法成功识别出了塑形奖赏的好坏 。 在图1中 , 三种BiPaRS方法的塑形权重曲线都在0之上 , 而在图2中这些曲线又都在0之下 。 值得一提的是 , BiPaRS-MGL和BiPaRS-IMGL两种方法在离散动作空间Cartpole和不利塑形奖励的测试中 , 竟然比PPO算法学得还要好 。 这也就意味着这些不利的塑形奖励反而被转化成了对学习有帮助的奖励 。
5.2 MuJoCo实验
为了验证本文所提出的奖赏塑形方法在复杂环境下的效果 , 作者从OpenAI Gym中选取了5个MuJoCo任务来做进一步测试 , 即:Swimmer-v2、Hopper-v2、Humanoid-v2、Walker2d-v2和HalfCheetah-v2 。 在这些任务中 , agent都是由若干关节连接而成 , 而agent需要施加一定的力矩 (torque) 在每一个关节上 。 在这些MuJoCo实验中 , 环境的真实奖励由Gym提供 , 塑形奖赏函数的设置参考了《带奖赏约束的策略优化》论文[20]中的MuJoCo实验 , 具体设置为:对于任意状态动作对, 其塑形奖赏为
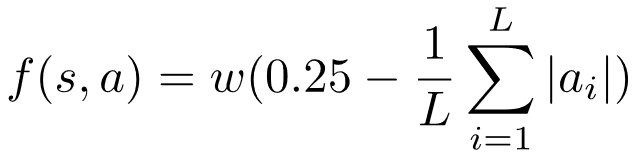
文章图片
其中 , L表示agent关节的数量 , 为施加在第i个关节上的力矩 , w是一个将塑形奖赏缩放到与真实奖赏相同尺度上的系数 (论文附录中给出)。 简单来说 , 这个塑形奖赏函数要求agent施加的平均力矩大小不超过0.25 , 同时有可能对学习产生负面影响[20] 。 注意 , 这里并非想效仿文献[20]用该奖赏函数来做约束条件 , 而是想检验当塑形奖赏与真实奖赏产生冲突时 , 本文提出的BiPaRS方法是否会放弃使用塑形奖赏 。
本实验仍采用PPO作为基础学习算法 , 并对比NS和DPBA两种奖赏塑形方法 , 同时 , 文献[20]中提出的RCPO算法也一并作为对比算法 。 除了Walker2d-v2任务的测试包含4,800,000训练步之外 , 其余4个任务中的测试都包含3,200,000个训练步 。 和Cartpole实验一样 , 每隔4,000训练步会进行一次20局的评估 。 每一次评估会记录下对应算法所获得的平均每局奖励 (average reward per episode , ARPE) 和平均每步的力矩大小 。 每一局评估的最大步数为1000 。
实验结果展示在图3中 , 可以看到 , BiPaRS方法能够很好地根据塑形奖赏函数进行自适应调整 。 例如 , 在Hopper-v2中 , BiPaRS-MGL和BiPaRS-IMGL获得了远超其他方法的平均奖赏值 , 而BiPaRS-EM方法虽然表现稍差 , 但仍然好于其他对比方法 。 每个方法的平均力矩曲线和对应的奖赏曲线也是相一致的 (力矩越小 , 奖赏值越低)。 在Swimmer-v2和HalfCheetah-v2中 , 本文的BiPaRS方法减缓了力矩变小的速度 , 而在其他任务中 , 它们甚至将力矩值变高了 。
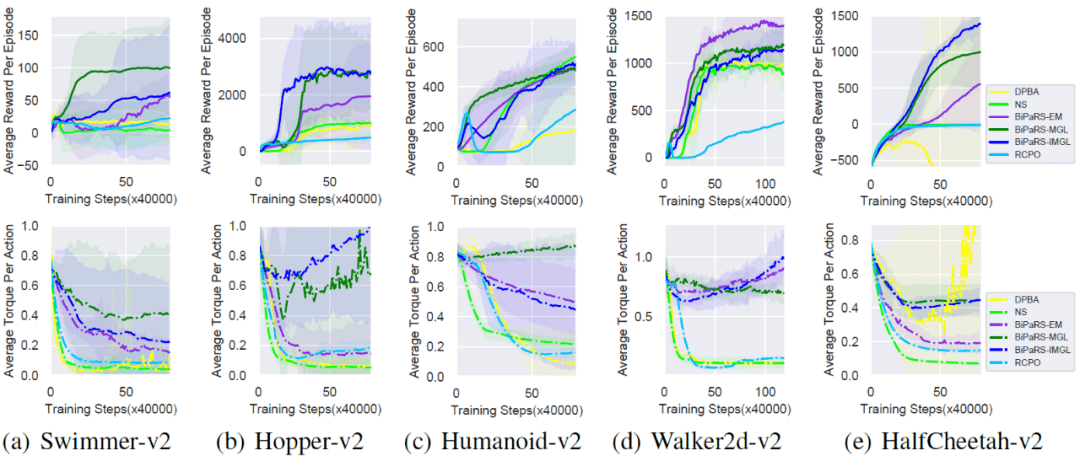
文章图片
【奖赏|网易伏羲联手天大、中科大提出: 自适应奖赏塑形的双层优化建模和求解】图3. MuJoCo实验中每个被测方法的平均奖赏曲线和平均力矩曲线
有趣的是 , 可以在Hopper-v的力矩图中发现两个V型的曲线 (即BiPaRS-MGL和BiPaRS-IMGL的力矩曲线), 这表明这两个方法一开始跟随塑形奖赏尝试减小作用在每个关节的力矩的 , 但当它们发现减小力矩不利于最大化环境真实奖励时 , 便反过开始增大力矩了 。
5.3 适应性验证实验 (Adaptability Test)
除了以上两个实验之外 , 本文还在Cartpole环境中对BiPaRS方法进行了适应性的验证实验 。
首先 , 作者在使用有害塑形奖励的设置下 (和图5的设置相同), 让三种BiPaRS方法直接加载之前学到的塑形权重函数 , 考查学习算法在学好的塑形权重下的表现 。 其次 , 采用随机的塑形奖赏设置 (塑形奖赏为[-1, 1]随机均匀分布) 来考查BiPaRS方法面对任意一个塑形奖赏函数的效果 。 实验的其他设置和5.1节的实验设置相同 。
图4中的虚线与BiPaRS方法在图2(b) 中的曲线相同 (这里用作对比), 而实线就是BiPaRS方法在重新加载 时的曲线 。 显然 , 对已经学到的 进行重新利用极大地改善了这些方法的学习性能 (严格地来说应该是学习算法 , 因为这里已经不涉对塑形权重的学习)。 实际上 , 重新加载 之后 , 所有的BiPaRS方法学习到的策略都要好于基础算法PPO学到的策略 , 这也证明了之前学到的塑形权重是正确且有用的 。
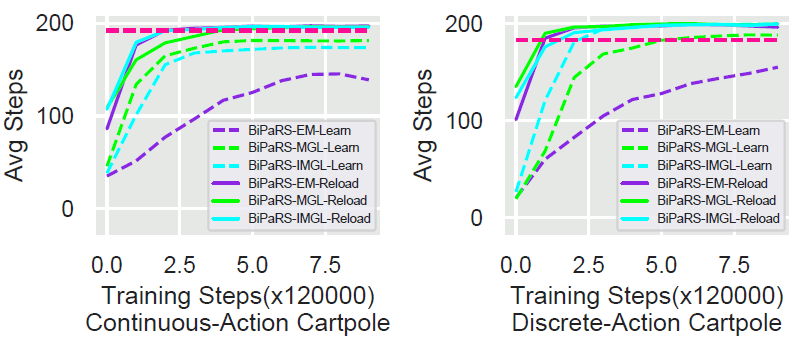
文章图片
图4. 重载塑形权重函数实验结果 , 左右图分别为连续动作空间和离散动作空间Cartpole
在随机塑形奖赏实验中 , 三种BiPaRS方法也其他方法学得更好 。 如图5所示 , BiPaRS-EM方法在连续动作空间Cartpole中取得了最高的平均步数性能 (170左右), 而在离散动作空间Cartpole中所有三种方法的平均每局步数都超过了150 。 请注意 , 随机塑形奖励的设置其实并不比有害塑形奖励的设置简单 , 这是因为学习算法很可能被相似的状态动作对中正好随机设为相反的塑形奖励所迷惑 。
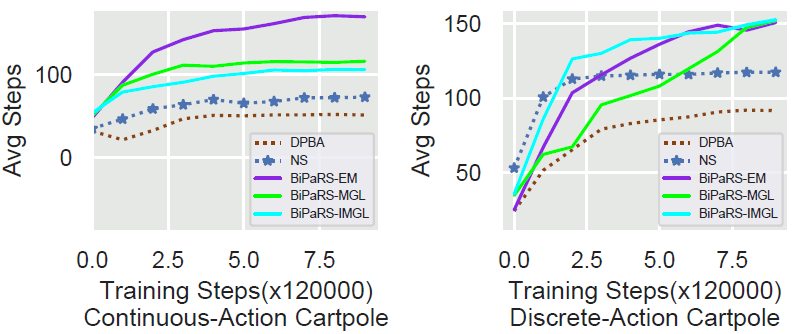
文章图片
图5. 随机塑形奖赏实验结果 , 左右图分别为连续动作空间和离散动作空间Cartpole
5.4 塑形权重与状态动作的相关性
细致的读者应该已经发现在以上绝大部分实验采用的塑形奖赏函数要么是完全有利的 , 要么是完全有害的 。 这也就意味着一个统一的状态 (或状态动作对) 无关的塑形权重也能解决问题 。 实际上 , 在5.1节的Cartpole实验中 , 本文的BiPaRS方法学到的塑形权重的确在不同状态 (或状态动作对) 上差别不大 。 作者在5.1节的Cartpole实验中额外实现了一个采用单值塑形权重的方法 , 对应的测试结果如图6所示 。
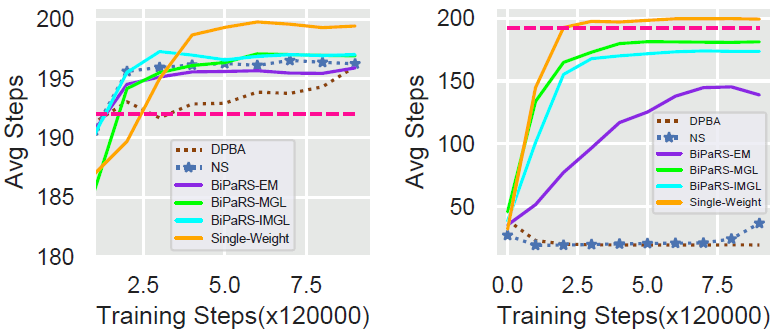
文章图片
图6. 单值塑形权重方法在5.1节实验连续动作空间Cartpole问题中的结果 , 左图为有利塑形奖赏设置 , 右图为有害塑形奖赏设置
从中可以看到这个单值塑形权重学习法要比其他奖赏塑形方法学得更快更好 。 因此 , 即便前面几节的实验证明了BiPaRS方法可以有效识别有利和有害的塑形奖赏 , 但这些方法是否可以学到状态 (或状态动作对) 相关的塑形权重仍然存疑 。 为了验证这一点 , 本节在连续动作空间Cartpole中进行了一个附加实验 , 设置一半的塑形奖赏为有利奖赏 , 而另一半的塑形奖赏为有害奖赏 。 具体地 , 当agent的动作能够在立杆往右倾斜时减小其倾角 , 那么它将获得一个0.1的正奖赏;而当agent的动作能够在立杆往左倾时减小其倾角 , 它反而将获得-0.1的奖赏 。
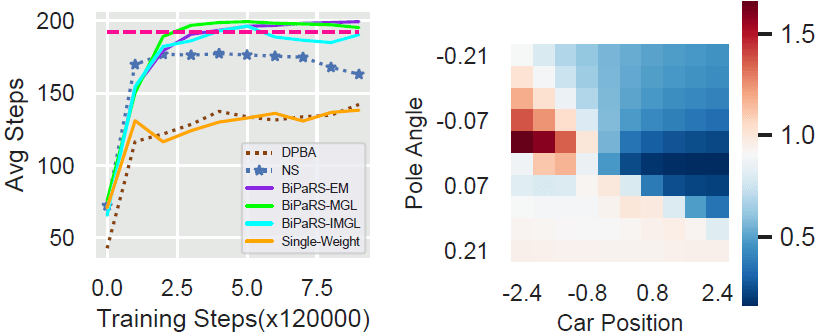
文章图片
图7. 状态相关塑形权重验证实验结果 , 右图为实验中BiPaRS-EM方法的塑形权重热力图
实验的结果展示在图7中 , 可以看到BiPaRS方法学得最好 , 同时单值塑形权重方法在该实验中已经无法像图6那样学得很好 。 作者选取了BiPaRS-EM方法最终所学到的权重函数在100个状态上的值并用热力的图的方式进行呈现 (图7的右边子图)。 需要注意的是 , Cartpole环境的状态一共有4个维度 , 作者将其中的小车速度特征固定为1.0 , 立杆速度固定为0.01 , 然后变化另外两个维度的值来生成这100个状态 。 从热力图中可以看出 , 随着小车位置或立杆倾角任意一维发生变化 , 相应的塑形权重也发生了比较明显的变化 , 证明BiPaRS-EM学到了状态相关的塑形权重 。
6. 总 结
本文提出了一种自适应利用给定塑形奖赏的新方法——带参塑形奖赏的双层优化 (bi-level optimization of parameterized reward shaping)。 本文对塑形奖赏的自适应利用问题进行了形式化定义 , 并提出相应的理论结果和近似求解方法 。 在小车立杆和MuJoCo中的实验表明 , 本文所提出的方法可以有效识别给定塑形奖赏的好坏并选择性地加以利用 。 在某些实验中 , 这些方法还能够将有害的塑形奖赏转化为有利的信号 , 使得学习算法学得更快更好 。
滑动查看参考文献!
[1] Guillaume Lample and Devendra Singh Chaplot. Playing fps games with deep reinforcement learning. In Proceedings of the 31st AAAI Conference on Artificial Intelligence (AAAI’17) , pages 2140–2146, 2017.
[2] Adam Laud and Gerald DeJong. The influence of reward on the speed of reinforcement learning: An analysis of shaping. In Proceedings of the 20th International Conference on Machine Learning (ICML’03) , pages 440–447, 2003.
[3] EricWiewiora. Potential-based shaping and q-value initialization are equivalent. Journal of Artificial Intelligence Research (JAIR) , 19:205–208, 2003.
[4] Sam Michael Devlin and Daniel Kudenko. Dynamic potential-based reward shaping. In Proceedings of the 11th International Conference on Autonomous Agents and Multiagent Systems (AAMAS’12) , pages 433–440, 2012.
[5] Anna Harutyunyan, Sam Devlin, Peter Vrancx, and Ann Nowe. Expressing arbitrary reward functions as potential-based advice. In Proceedings of the 29th AAAI Conference on Artificial Intelligence (AAAI’15) , pages 2652–2658, 2015.
[6] Eric Wiewiora, Garrison W Cottrell, and Charles Elkan. Principled methods for advising reinforcement learning agents. In Proceedings of the 20th International Conference on Machine Learning (ICML’03) , pages 792–799, 2003.
[7] Andrew Y Ng, Daishi Harada, and Stuart Russell. Policy invariance under reward transformations: Theory and application to reward shaping. In Proceedings of the 16th International Conference on Machine Learning (ICML’99) , pages 278–287, 1999.
[8] Sam Devlin and Daniel Kudenko. Theoretical considerations of potential-based reward shaping for multi-agent systems. In Proceedings of the 10th International Conference on Autonomous Agents and Multiagent Systems (AAMAS’11) , pages 225–232, 2011.
[9] Ofir Marom and Benjamin Rosman. Belief reward shaping in reinforcement learning. In Proceedings of the 32nd AAAI Conference on Artificial Intelligence (AAAI’18) , pages 3762–3769, 2018.
[10] Haosheng Zou, Tongzheng Ren, Dong Yan, Hang Su, and Jun Zhu. Reward shaping via metalearning. arXiv preprint, arXiv:1901.09330, 2019.
[11] Zhao-Yang Fu, De-Chuan Zhan, Xin-Chun Li, and Yi-Xing Lu. Automatic successive reinforcement learning with multiple auxiliary rewards. In Proceedings of the 28th International Joint Conference on Artificial Intelligence (IJCAI’19) , pages 2336–2342, 2019.
[12] Deepak Pathak, Pulkit Agrawal, Alexei A Efros, and Trevor Darrell. Curiosity-Driven Exploration by Self-supervised Prediction. In ICML, 2017
[13] Burda, Y., Edwards, H., Storkey, A., and Klimov, O. Exploration by random network distillation. arXiv preprint arXiv:1810.12894, 2018b.
[14] Satinder P. Singh, Andrew G. Barto, and Nuttapong Chentanez. Intrinsically motivated reinforcement learning. In Advances in Neural Information Processing Systems 17 (NIPS’04) , pages 1281–1288, 2004.
[15] Jonathan Sorg, Satinder P. Singh, and Richard L. Lewis. Reward design via online gradient ascent. In Advances in Neural Information Processing Systems 23 (NIPS’10) , pages 2190–2198, 2010.
[16] Zeyu Zheng, Junhyuk Oh, and Satinder Singh. On learning intrinsic rewards for policy gradient methods. In Advances in Neural Information Processing Systems 31 (NeurIPS’18) , pages 4649–4659, 2018.
[17] Zeyu Zheng, Junhyuk Oh, Matteo Hessel, Zhongwen Xu, Manuel Kroiss, Hado van Hasselt, David Silver, and Satinder Singh. What can learned intrinsic rewards capture? In Proceedings of the 37th International Conference on Machine Learning (ICML’20) , 2019.
[18] Max Jaderberg, Wojciech M Czarnecki, Iain Dunning, Luke Marris, Guy Lever, Antonio Garcia Castaneda, Charles Beattie, Neil C Rabinowitz, Ari S Morcos, Avraham Ruderman, et al. Human-level performance in 3d multiplayer games with population-based reinforcement learning. Science, 364(6443) :859–865, 2019.
[19] Richard S. Sutton, David A. McAllester, Satinder P. Singh, and Yishay Mansour. Policy gradient methods for reinforcement learning with function approximation. In Proceedings of Advances in Neural Information Processing Systems 12 (NIPS’00) , pages 1057–1063, 1999.
[20] Chen Tessler, Daniel J. Mankowitz, and Shie Mannor. Reward constrained policy optimization. In Proceedings of the 7th International Conference on Learning Representations (ICLR’19) , 2019.
//
作者介绍:
本座 , 网易伏羲实验室人工智能研究员 , 此前分别于2010年6月和2015年12月从南京大学计算机科学与技术系获得学士和博士学位 。 本座于2016年3月加入阿里巴巴 , 于2018年9月加入网易伏羲实验室 。 本座的研究兴趣包括强化学习、多智能体系统、博弈论、游戏人工智能 , 并在相关领域的会议和期刊 (NeurIPS、ICML、ICLR、KDD、IJCAI、AAAI、AAMAS、IEEE CoG、TCYB等) 上发表论文十余篇 。
推荐阅读







- Waymo|PayPal CEO:积极在日本展开收购,开拓支付市场;网易入股虚拟数字研发商世悦星承 | 思维独角兽
- 大叔|从治愈到共振,网易云音乐的刷屏套路升级了
- 平台|【生活】网易云/QQ音乐/美团/抖音年度报告出炉 你最常听/刷谁?
- 海豚计划|来真的!网易有道词典“海豚计划”百亿流量亿元现金全力扶持知识创作者
- 上海|萌新知识博主靠创作实现梦想,网易有道词典学习社区成新风口
- 来源|史上最严!腾讯、网易都出手了
- banner|2021 年度 QQ 音乐、网易云听歌报告出炉,你喜欢的是什么
- 公司|百家名企看高质量|专访周枫:网易有道转型“先刹车,再加速”
- 技术|12 月 22 日发布,vivo WATCH 2 确认内置网易云音乐、喜马拉雅
- 青少年|网易CC直播张金通:保护未成年人应有真诚、合作、沟通态度