作者:清华大学交叉信息学院博士生 朱广翔
第·15·期
本文将分享清华大学联合密歇根大学发表于 NeurIPS 2020的工作: 《兼顾想象与现实的基于模型强化学习算法》 。
为了提高样本利用效率 , 越来越多研究者们关注基于模型的强化学习 , 建立世界模型并基于虚拟轨迹进行策略优化 , 类似人类的“想象”和“规划” 。 然而 , 世界模型的学习容易过拟合训练轨迹 , 基于世界模型的价值估计和策略搜索很容易陷入局部最优 。
本文提出了一种全新的基于模型的强化学习算法 , 最大化了世界模型中生成的虚拟轨迹和真实世界的采样轨迹之间的互信息 , 使得在世界模型中的策略优化过程也会考虑到与真实世界的差异性及各种可能轨迹的置信度 , 因此从虚拟轨迹中学习到的策略提升可以很容易地推广到真实轨迹上 。 在以视觉图像为输入的机器人控制任务公开数据集上 , 该算法超越了当前最先进的基于模型强化学习算法 。

文章图片
https://papers.nips.cc/paper/2020/file/661b1e76b95cc50a7a11a85619a67d95-Paper.pdf
一、研究背景
强化学习 (Reinforcement learning , RL) 作为一种针对人工智能问题的通用学习框架 , 在许多领域取得了巨大的进展 。
无模型强化学习 (Model-Free Reinforcement learning) 采用了一种不断在环境中试错的范式 , 直接学习从观测值映射到行为的策略函数 。 这就类似我们训练狗狗 , 如果做对了动作会给予奖励 , 错误给予惩罚 , 狗狗在不断的试错过程中逐渐学会看到了什么指令做什么动作 。
无模型学习范式由于其简单性、通用性和几乎对环境没有特殊假设 , 它在视频游戏和连续控制任务中取得了大量的领先成果 。 然而 , 无模型方法的样本效率并不高 , 往往需数倍于人的训练样本 , 这限制了它在实际任务中的应用 。
样本利用效率问题一直是深度强化学习的主要挑战之一 。 为了提高样本利用效率 , 近年来越来越多的研究者们开始关注基于模型的强化学习 (Model-Based Reinforcement learning) 。 这一类基于模型的方法 , 旨在通过对外界环境建立世界模型 (World Model) , 然后在世界模型中对策略进行探索 , 对状态的值函数进行估计 , 并进行策略优化来获得世界模型中的最优策略 。 这就类似于人类行为中的“想象”和“规划” , 可以不依赖真实世界的样本进行策略优化 , 在实际做出决策之前预估各种可能性结果并选择最优方案 。
基于模型的强化学习可以大致分为以下四类:
第一类:Dyna式算法(Dyna-style algorithms) 。 这一类算法主要由两个两部分构成:与环境的交互过程中构建世界模型 , 利用模型生成的虚拟数据扩充真实数据池来进行策略优化 。 这两部分交替进行 , 迭代优化 。
第二类:模型预测控制及shooting算法 (model predictive control and shooting algorithms) 。这一类算法主要交替进行模型拟合、策略规划和动作执行 。 策略规划即 , 基于模型生成大量的轨迹并预测收益 , 从其中选择最好的策略作为执行策略 。
第三类:基于模型的值扩展算法 (model-augmented value expansion algorithms)。 这类算法根据贝尔曼方程的有模型展开式 , 来扩展无模型的TD更新目标或策略梯度 。
第四 类:解析梯度算法 (analytic-gradient algorithms) 。 这类算法直接对世界模型生成的虚拟轨迹的收益值关于策略函数求梯度 , 并通过可微分的世界模型将该梯度直接传播到策略网络 。 相比于传统的策略规划 , 解析梯度算法不需要生成一群轨迹进行收益预测和选优 , 而是只根据梯度找到世界模型下最优的策略 , 相当于可微分规划 (differentiable planning) , 因此计算效率更高 , 尤其是在具有深层神经网络的场景中 。
谷歌的最新算法Dreamer , 作为解析梯度算法的最新里程碑式工作 , 在机器人视觉控制任务上达到了最高的性能 。 但是Dreamer在策略优化的过程中 , 只考虑到了世界模型中的策略提升梯度 , 忽略了真实世界的采样 。 而世界模型的学习往往会过拟合训练轨迹 , 因此Dreamer基于世界模型的价值估计和策略搜索很容易陷入局部最优 。
针对这个问题 , 本文提出了一种全新的基于模型的强化学习算法 , 称为BrIdging Reality and Dream (BIRD) 。 它最大化了世界模型中生成的虚拟轨迹和真实世界的采样轨迹之间的互信息 , 使得在世界模型中的策略优化过程也会考虑到与真实世界的差异性及各种可能路径的置信度 , 因此从虚拟轨迹中学习到的策略提升可以很容易地推广到真实轨迹上 。
该学习范式自然地将解释梯度策略优化、熵最大化、世界模型优化、置信度优化四部分整合到了统一的框架下 。 实验证明 , 该方法显著提高了基于模型规划算法的样本利用效率 。 在以视觉图像为输入的机器人控制任务公开数据集上 , 该方法超越了Dreamer , 取得了该领域中最高的性能 。
二、方法介绍
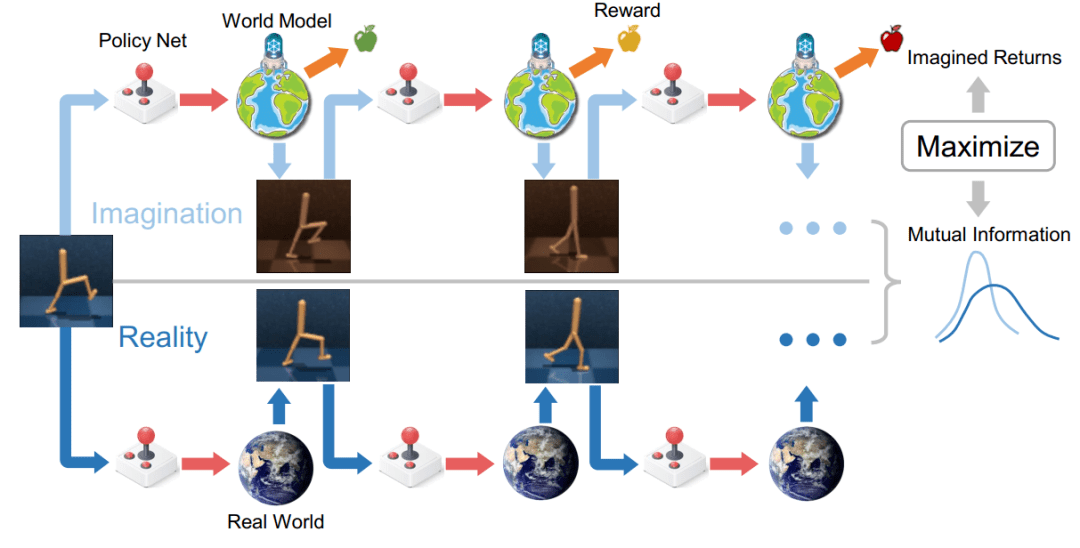
文章图片
该图显示了总体的算法框架 。 一方面 , 作者们利用解析梯度方法对策略函数进行优化 (Policy Improvement) , 使得其在世界模型中的虚拟轨迹上获得最高的预测收益 。 另一方面 , 作者们最大化了虚拟轨迹和真实轨迹之间的互信息 (Mutual Information) , 使得虚拟轨迹尽可能真实 。 因此 , 总体的优化目标函数为:

文章图片
其中 , 表示根据实际执行动作从环境收集到的真实路径 , 表示相同的执行动作在世界模型中得到的虚拟路径 。 表示在解析梯度算法优化过程中 , 将世界模型带入策略函数得到的端到端的虚拟路径 。 分别表示策略网络 , 值网络 , 世界模型的参数 。 SVG表示stochastic value gradients , 一种经典的解析梯度算法 。 TD表示值函数的TD error优化 。
传统的基于模型的强化学习方法中通常也会使用真实轨迹来优化世界模型预测误差 , 但这与BIRD框架有很大不同 。 在复杂的问题中 , 世界模型即使按照真实轨迹优化 , 得到的预测误差也往往无法忽略不计 。 用一个不精确的世界模型预测多步会产生很大的累积误差 , 使生成的轨迹与实际轨迹之间存在很大的差距 。
该问题在解析梯度算法中进一步恶化 , 因为解析梯度算法直接沿着世界模型求策略函数的梯度 , 需要世界模型在当前策略函数的邻域内也要表现良好 , 而邻域的数据往往超出了训练集的覆盖范围 , 对世界模型的泛化能力提出了更高的要求 。
为了解决这个问题 , 我们的方法从 世界模型和 策略函数两方面优化互信息 , 不仅能像传统方法那样优化世界模型的预测误差 , 也会使得策略优化对世界模型的置信度敏感。 也就是说 , BIRD一方面会提高世界模型准确度 , 准确度高的地方会加大力度优化策略 , 另一方面在世界模型精度不够的地方 , 会比较保守的去降低策略的优化强度 。
1. 世界模型中的策略优化
本文采用了一种经典的解析梯度算法 SVG来优化策略函数 , 目标是最大化当前策略在世界模型中的预测收益 , 基于端到端的策略梯度进行优化 。 目标函数如下:
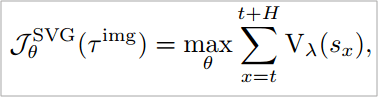
文章图片
其中 , 是指数平均的值估计 , 用于平衡bias和variance , 其公式如下:
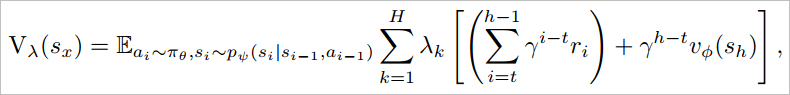
文章图片
对于值函数的优化 , 本文采取了TD 更新:
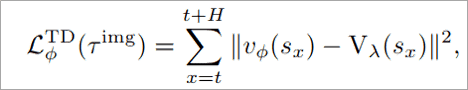
文章图片
2. 虚拟路径和真实路径的互信息优化
本文对互信息优化公式进行了展开 , 并分别对世界模型参数和策略函数参数进行求导 , 得到了三项:模型预测误差最小化、策略熵最大化、基于置信度的策略优化 。
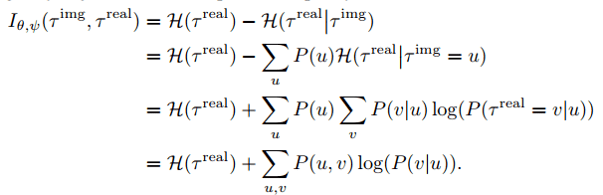
文章图片
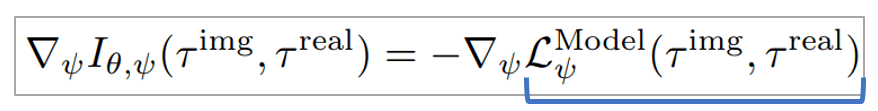
文章图片
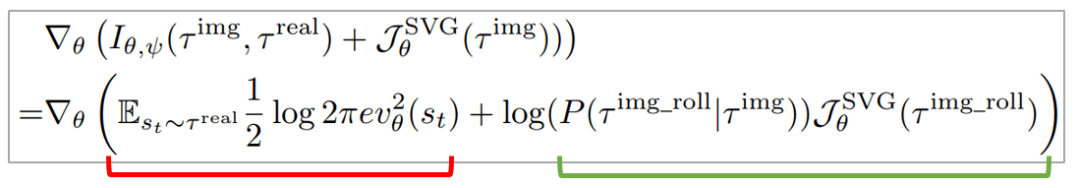
文章图片
第一项模型预测误差最小化 , 与普通基于模型的强化学习算法中的世界模型构建部分完全相同 , 本文采用了常见的似然函数 , 根据利用采样得到的真实样本对此项进行优化 。
第二项策略熵最大化 , 直接对策略的熵进行最大化 , 提高策略的多样性 。 直观上看 , 相当于提高了可微规划过程中的策略搜索空间 。
第三项基于置信度的策略优化 , 鼓励在模型预测置信度高的地方增大学习力度 , 在模型预测置信度低的地方降低学习强度 。 直观上看 , 相当于提高了策略搜索的质量 。
第二项和第三项结合起来看 , 本文的新型策略优化目标 , 相当于一边扩大了搜索的可能性 , 一边保证搜到的新数据能按照置信度去优化 , 从而避免了被高熵策略带来的离群值破坏优化 。 本文从对互信息的优化出发 , 推导出这三项 , 很自然地将模型误差、熵、置信度统一到一个完整的框架内 。
3. 仅最大化熵的对比方法
上一部分提到了策略的熵 , 说到熵 , 我们很容易联想到在无模型的算法领域 , 研究者们通过优化熵 , 提高策略鲁棒性 , 例如SAC算法 (Soft Actor Critic) 。 因此 , 我们产生一个很自然的想法 , 在基于模型的算法领域 , 是不是简单的像SAC那样提高策略的熵 , 提高策略鲁棒性就足够提高解析梯度算法的表现了呢?
对此 , 本文从SAC算法的思路出发 , 在基于模型的强化学习领域 , 在解析梯度算法中融合Soft Bellman Equation来优化熵 , 提出了Soft-BRID 。 基于soft Bellman Equation的目标函数如下:
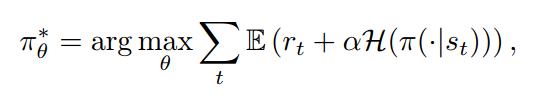
文章图片
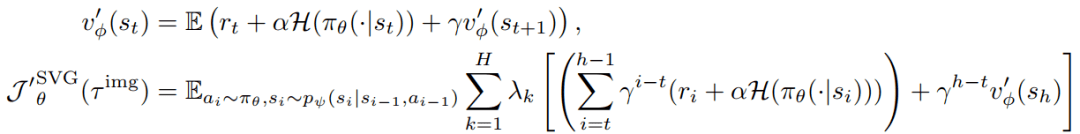
文章图片
本文将该方法与本文提出的BIRD方法对比 , 来检验一下是否仅仅优化熵就已经足够提高算法表现 。
三、实验结果
文章图片
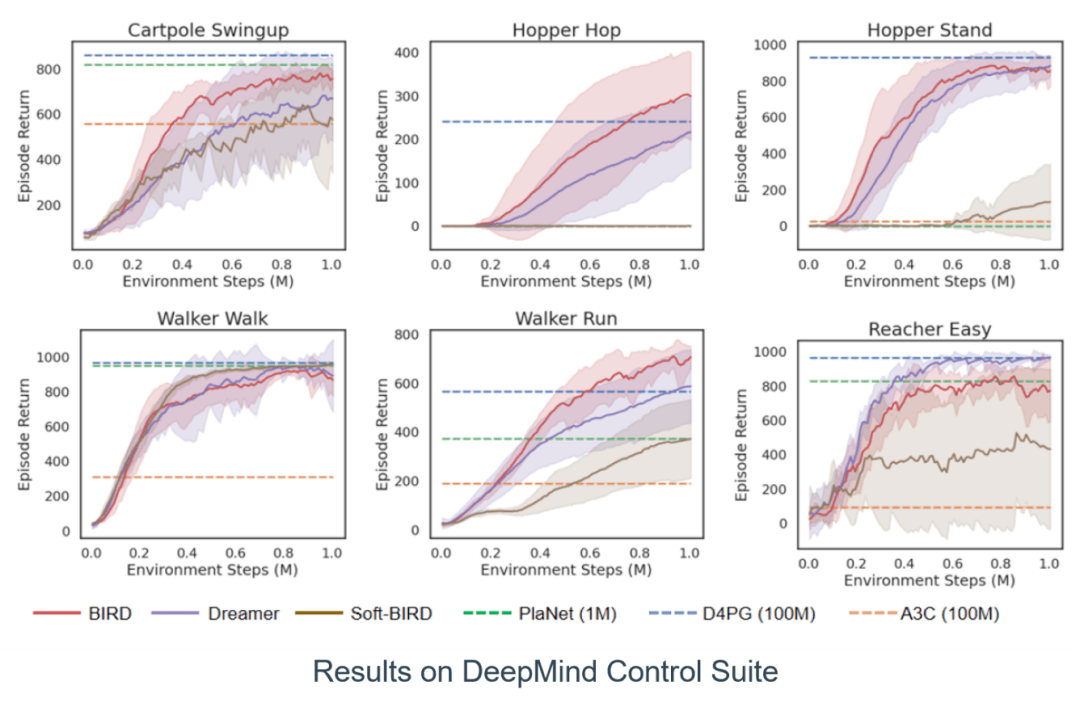
本文在机器人视觉控制数据集Deepmind Control Suite(输入为从第三视角对Mujoco机器人的2D拍摄图像)上进行了测试 , 并与最前沿的基于模型的方法Dreamer、PlaNet , 无模型的方法D4PG、A3C , 熵优化方法Soft-BIRD进行了对比 , BIRD取得了领先的表现 。
实验结果表明 , 基于模型的方法样本利用效率普遍超过了无模型的方法 。 BIRD与Dreamer的对比 , 显示了本文对互信息的优化提高了策略在真实环境中的表现 。 Soft-BIRD在大部分任务表现都不够好 , 说明了不考虑真实环境与虚拟环境的互信息 , 仅提高策略鲁棒性是不够的 , 也说明了互信息的收益不仅靠多出的熵增项 , 也得益于基于置信度的策略优化项 。
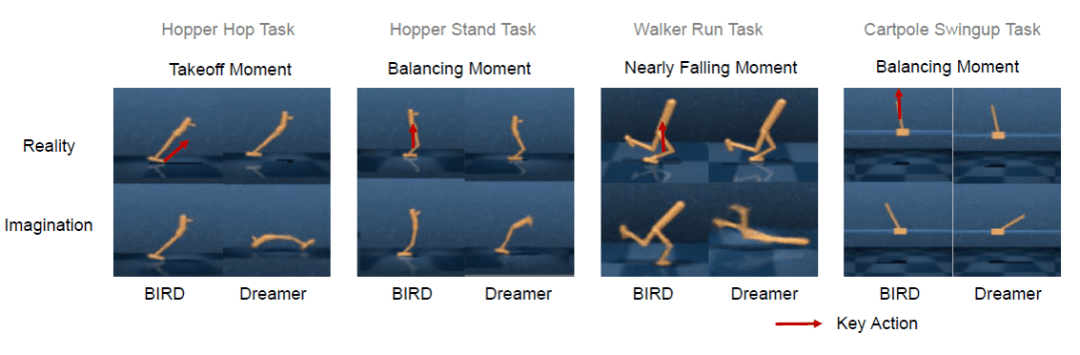
另外 , 本文通过案例分析发现了BIRD在关键动作的预测上会明显超过Dreamer , 在Hopper的起跳瞬间、平衡瞬间 , Walker的将倾瞬间 , Cartpole的平衡瞬间BIRD的预测更接近真实 。
文章图片
作者介绍
朱广翔 , 清华大学交叉信息研究院计算机方向博士生 。 他的研究目标是利用高效表征、世界模型、情景记忆等方法提高深度强化学习中的样本效率 , 研究兴趣也包括深度学习在自动驾驶 , 电商 , 计算生物 , 金融危机、天气预测等场景中的应用 。
更多信息请访问个人主页:
https://guangxiangzhu.github.io/
本周上新!扫码观看!
▼
【世界|NeurIPS 2020 | 清华联合密歇根大学: 兼顾想象与现实的基于模型强化学习算法】微信:thejiangmen
推荐阅读







- 最新消息|世界单体容量最大漂浮式光伏电站在德州并网发电
- 四平|智慧城市“奥斯卡”揭晓!祝贺柯桥客户荣获2021世界智慧城市治理大奖
- 系列|2021中国航天发射圆满收官!年发射55次居世界第一
- 科技创新平台|云南:打造世界一流食用菌科技创新平台
- 堆芯|全球首座,世界领跑!
- 视觉|超高色准打破行业天花板,创维S82还原真实世界
- 机器人|捷报!万州高级中学勇夺机器人比赛世界冠军
- 最新消息|世界规模最大抽水蓄能电站投产发电
- 虚拟世界|周鸿祎:元宇宙最大的风险是数字安全
- 全年|通信技术试验卫星九号成功发射 中国航天全年发射次数世界第一