技术|华为诺亚Transformer后量化技术:效率百倍提升,视觉&NLP性能不减
机器之心专栏
机器之心编辑部
Transformer 在自然语言处理和视觉任务中取得了令人瞩目的成果 , 然而预训练大模型的推理代价是备受关心的问题 , 华为诺亚方舟实验室的研究者们联合高校提出针对视觉和 NLP 预训练大模型的后训练量化方法 。 在精度不掉的情况下 , 比 SOTA 训练感知方法提速 100 倍以上;量化网络性能也逼近训练感知量化方法 。大型预训练模型在计算机视觉和自然语言处理中展现了巨大的潜力 , 但是模型大、参数多的问题也给它们的商业化落地带来了很大挑战 。 模型压缩技术是当前的研究热点 , 模型量化是其中的一个重要分支 。
当下预训练模型的量化为了保证性能 , 大多采用量化感知训练(Quantization-aware Training, QAT) 。 而模型后量化(Post-training Quantization, PTQ)作为另一类常用量化方法 , 在预训练大模型领域却鲜有探索 。 诺亚方舟实验室的研究者从以下四个方面对 QAT 与 PTQ 进行了详细对比:
- 训练时间:QAT 由于模拟量化算子等操作 , 训练耗时远远超出全精度训练(FP) , 而 PTQ 仅仅需要几十分钟 , 大大缩短量化流程;
- 显存开销:QAT 显存消耗大于全精度训练(FP) , 使得在显存有限的设备上难以进行量化训练 。 而 PTQ 通过逐层回归训练 , 无需载入整个模型到显存中 , 从而减小显存开销;
- 数据依赖:QAT 需要获取整个训练数据集 , 而 PTQ 只需要随机采样少量校准数据 , 通常 1K~4K 张 / 条图像或者标注即可;
- 性能:鉴于 QAT 在整个训练集上充分训练 , 其性能在不同的量化 bit 上均领先 PTQ 。 因此性能是 PTQ 的主要瓶颈 。
接下来将分别介绍这两项工作 。
论文 1
《Post-Training Quantization for Vision Transformer》

文章图片
论文链接:https://arxiv.org/pdf/2106.14156.pdf
方法概述
下图为视觉 Transformer 后训练量化算法框架:
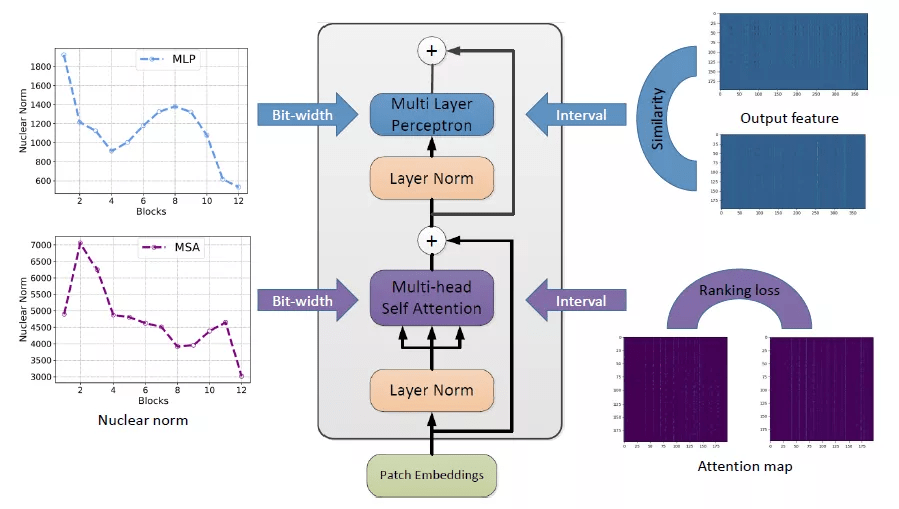
文章图片
排序损失量化
自注意力层是 Transfomer 结构中十分重要的部分 , 也是 Transformer 与传统卷积神经网络不同的地方 。 对于自注意力层 , 研究者发现量化使得注意力特征的相对顺序变得不同 , 会带来很大的性能下降 。 因此 , 他们在量化过程中引入了一个排序损失:
推荐阅读







- 生物|两项国家标准发布实施 为畜禽生物育种提供技术参考
- IT之家|华为nova系列4G新机入网图公布:6.78英寸LCD屏,1.08亿像素主摄
- 该机|华为 nova 系列 4G 新机入网图公布:6.78 英寸 LCD 屏
- 财产|折叠屏手机冲击高端,荣耀从华为继承的最后财产
- 俄罗斯|22岁天才少女加入华为俄罗斯研究院,曾获「编程界奥赛」冠军
- 平台|韩国科学技术研究院开发出世界首款 AI 运算专用 SSD
- 爆发|从1G到5G 技术成熟与应用爆发相辅相成
- 技术|Magic V正式发布,一部难到位,荣耀的高端之路刚刚开始
- 关键特性|5G超级频率聚变技术成功纳入3GPP R18标准立项
- 专利技术|抗幽别听忽悠