技术|华为诺亚Transformer后量化技术:效率百倍提升,视觉&NLP性能不减( 三 )
文章图片
目标检测任务上的后训练量化结果 。
论文 2
《Towards Efficient Post-training Quantization of Pre-trained Language Models》

文章图片
论文链接:https://arxiv.org/pdf/2109.15082.pdf
方法概述
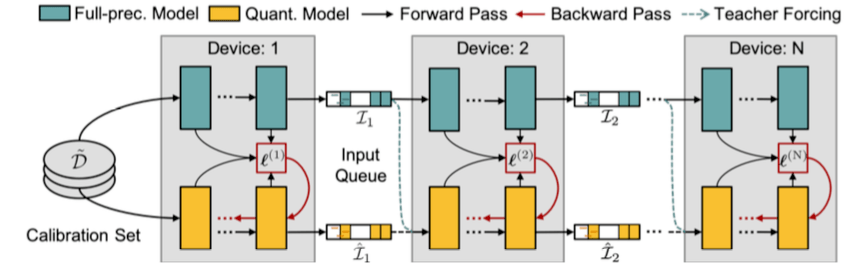
下图为并行蒸馏下的模型后量化总体框架:
文章图片
模块化重构误差最小化
由于 Transformer-based 的预训练语言模型通常含有多个线性层耦合在一起 , 如果采用现有的逐层重构误差优化的方法【3】 , 作者发现很容易陷入局部最优解 。 为了考虑多个线性层内部的交互 , 如上图所示 , 研究者把预训练语言模型切分成多个模块 , 每个模块含有多个 Transformer 层 。
因此该方法聚焦于逐个重构模块化的量化误差 , 即最小化全精度网络模块(教师模型)的输出与量化后模型模块(学生网络)的输出之间的平方损失:
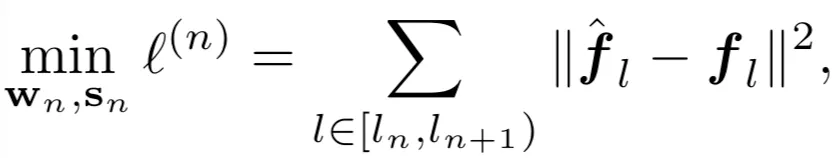
文章图片
并行知识蒸馏训练
与逐个模块化重构量化误差不同 , 后量化还可以并行化训练 。 研究者把每个切分后的模块可以放在不同的 GPU 上 , 在不同模块之间设置输入缓冲池(input queue)
文章图片
来收集上一个模块的输出 , 同时为下一个模块的输入做准备 。 不同模块可以通过重置抽样从输入池获取输入样本来进行本地训练 , 无需等待其前继模块 。 因此 , 该设计可以使并行训练 , 并且实现接近理论加速比 。
另外一个与逐模块训练不同的点在于 , 在并行知识蒸馏训练的初期 , 下一个模块获得的输入是从上一个未经过充分训练的模块中获得 。 因此 , 未充分训练的模块的输出可能依旧含有较大的量化误差 , 并且该误差会逐层传播 , 影响后续模块训练 。
为了解决该问题 , 研究者受教师纠正(teacher forcing) 在训练循环网络中的启发 , 将第 n 个全精度模块的输出导入为第 (n+1) 个量化模块的输入 , 从而中断在后续模块的量化误差传播 。 然而 , 这种跨模块输入打破了与量化模型自身前继模块的联系 , 造成训练和推理前向不一致 。 为了实现平稳过渡 , 他们采用了如下的凸组合:
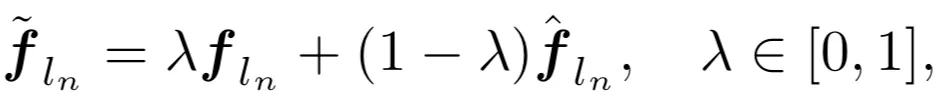
文章图片
并对连接系数
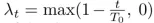
推荐阅读







- 生物|两项国家标准发布实施 为畜禽生物育种提供技术参考
- IT之家|华为nova系列4G新机入网图公布:6.78英寸LCD屏,1.08亿像素主摄
- 该机|华为 nova 系列 4G 新机入网图公布:6.78 英寸 LCD 屏
- 财产|折叠屏手机冲击高端,荣耀从华为继承的最后财产
- 俄罗斯|22岁天才少女加入华为俄罗斯研究院,曾获「编程界奥赛」冠军
- 平台|韩国科学技术研究院开发出世界首款 AI 运算专用 SSD
- 爆发|从1G到5G 技术成熟与应用爆发相辅相成
- 技术|Magic V正式发布,一部难到位,荣耀的高端之路刚刚开始
- 关键特性|5G超级频率聚变技术成功纳入3GPP R18标准立项
- 专利技术|抗幽别听忽悠