技术|华为诺亚Transformer后量化技术:效率百倍提升,视觉&NLP性能不减( 二 )
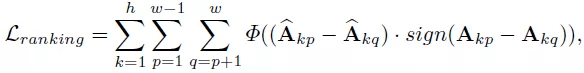
文章图片
其中表示成对的排序损失函数 , 表示权衡系数 。 然后 , 研究者将排序损失函数与相似度损失函数相结合 , 得到了最终的优化目标函数:
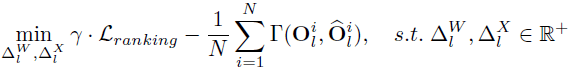
文章图片
【技术|华为诺亚Transformer后量化技术:效率百倍提升,视觉&NLP性能不减】论文当中采用了比尔森相关系数作为特征相似度的度量 , 研究者认为皮尔森相关系数减去了均值 , 所以对特征的分布表示更加地敏感 。
为了进一步减少量化带来的误差 , 他们在优化量化步长过程中采用了量化误差补偿的方法 , 以减小量化误差对之后的网络层带来影响 。 因此对每个网络层的输出都进行了量化误差补偿 。
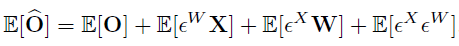
文章图片
在实现过程中 , 误差的期望值可以通过校验数据集来计算 , 然后在网络层的 bias 参数中去修正 。
混合比特量化
不同的 transformer 网络层有不同的数据分布 , 因为有不同的量化「敏感度」 。 研究者提出了混合精度量化 , 对于更加「敏感」的网络层分配更多的比特宽度 。
在论文中 , 研究者提出使用 MSA 模块中注意力层特征和 MLP 中输出特征矩阵的核范数来作为度量网络层「敏感度」的方法 。 与 HAWQ-V2 中的方法类似 , 他们使用了一种帕累托最优的方式来决定网络层的量化比特 。 该方法的主要思想是对每个候选比特组合进行排序 , 具体的计算方式如下所示:
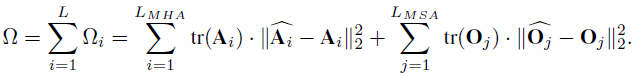
文章图片
给定一个目标模型大小 , 会对所有的候选比特组合进行排序 , 并寻找值最小的候选比特组合作为最终的混合比特量化方案 。
实验验证
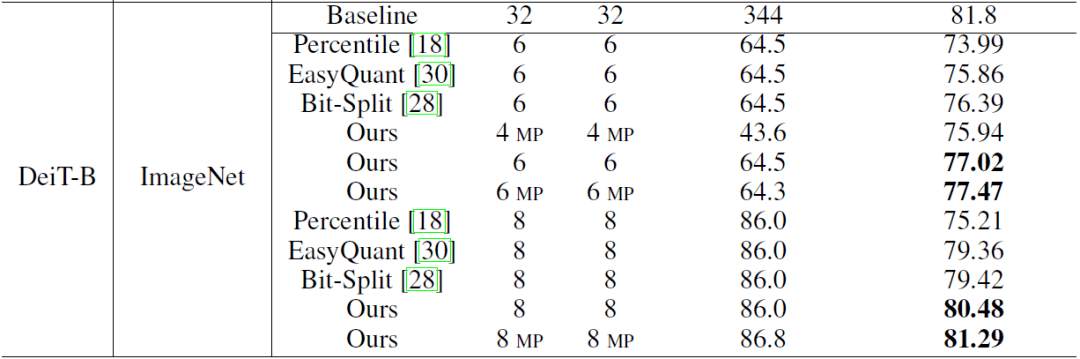
研究者首先在图像分类任务上对后训练量化算法进行了验证 。 从下表可以看出 , 在 ViT(DeiT)经典 transformer 模型上 , 论文的量化算法均优于之前的卷积神经网络量化算法【1】【2】 。 例如 , 在 ImageNet 数据集上 , 量化 Deit-B 模型也取得了 81.29% 的 Top-1 准确率 。
文章图片
图像分类任务上的后训练量化结果 。
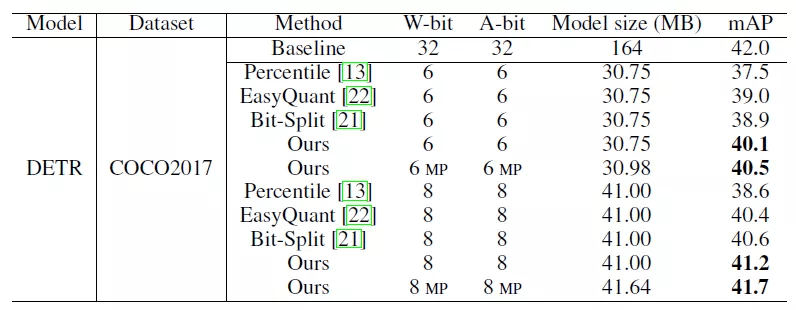
研究者还将后训练量化算法应用于目标检测任务中 , 其中在 COCO2017 数据集上 , 对 DETR 进行量化 , 8bit 模型的性能可以达到 41.7 mAP , 接近全精度模型的性能 。
推荐阅读







- 生物|两项国家标准发布实施 为畜禽生物育种提供技术参考
- IT之家|华为nova系列4G新机入网图公布:6.78英寸LCD屏,1.08亿像素主摄
- 该机|华为 nova 系列 4G 新机入网图公布:6.78 英寸 LCD 屏
- 财产|折叠屏手机冲击高端,荣耀从华为继承的最后财产
- 俄罗斯|22岁天才少女加入华为俄罗斯研究院,曾获「编程界奥赛」冠军
- 平台|韩国科学技术研究院开发出世界首款 AI 运算专用 SSD
- 爆发|从1G到5G 技术成熟与应用爆发相辅相成
- 技术|Magic V正式发布,一部难到位,荣耀的高端之路刚刚开始
- 关键特性|5G超级频率聚变技术成功纳入3GPP R18标准立项
- 专利技术|抗幽别听忽悠