识别|避免自动驾驶事故,CV领域如何检测物理攻击?( 九 )
2.1 对抗性攻击分析和防御的解释
2.1.1 CNN 漏洞解读
解释和假设 。 在一个典型的图像或音频识别过程中 , CNN 从原始输入数据中提取特征并得出预测结果 。 然而 , 当向原始数据注入物理对抗性扰动时 , CNN 将被误导出一个错误的预测结果 。 为了更好地解释这个漏洞 , 作者以一个典型的图像物理对抗性攻击—对抗性补丁攻击为例进行分析 。
在图 1 中 , 通过与原始输入的比较 , 我们发现一个对抗性补丁通常在颜色 / 形状等方面没有限制约束 。 这样的补丁通常会牺牲语义结构 , 从而导致明显的异常激活 , 并压倒其他输入模式的激活 。 因此 , 作者提出了一个假设:CNN 缺乏定性的语义辨别能力 , 在 CNN 推理过程中可以被非语义的对抗性补丁激活 。
假设验证 。 根据上述假设 , 输入的非语义模式会导致异常的激活 , 而输入的语义模式会产生正常的激活 。 作者提出通过调查 CNN 中每个神经元的语义来评估这种差异 , 并引入一种可视化的 * CNN 语义分析方法—激活最大化可视化 *(Activation Maximization Visualization , AM) 。 AM 可以生成一个 pattern , 将每个神经元最活跃的语义输入可视化 。 图案 V((N_i)^l)的生成过程可以被看作是向 CNN 模型合成一个输入图像 , 使第 l 层中的第 i 个神经元(N_i)^l 的激活度最大化 。 该过程可以表征为:
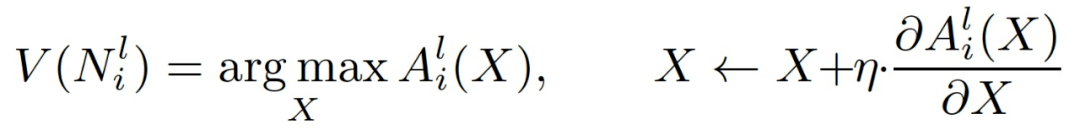
文章图片
其中 , (A_i)^l(X)为输入图像 X 的(N_i)^l 的激活 , (A_i)^l 表征第 l 层的第 i 个神经元对应的激活 , (N_i)^l 为第 l 层的第 i 个神经元 , η为梯度下降步长 。
图 4 展示了使用 AM 的可视化输入的语义模式 。 由于原始的 AM 方法是为语义解释而设计的 , 在生成可解释的可视化模式时 , 涉及许多特征规定和手工设计的自然图像参考 。 因此 , 我们可以得到图 4(a)中平均激活幅度值为 3.5 的三个 AM 模式 。 这三种模式中的对象表明它们有明确的语义 。 然而 , 当我们在 AM 过程中去除这些语义规定时 , 我们得到了三种不同的可视化 patterns , 如图 4(b)所示 。 我们可以发现 , 这三个 patterns 是非语义性的 , 但它们有明显的异常激活 , 平均幅值为 110 。 这一现象可以证明作者的假设 , 即 * CNN 神经元缺乏语义辨别能力 , 可以被输入的非语义模式显著激活 * 。

文章图片
图 4. 通过激活最大化可视化神经元的输入模式
2.1.2 输入语义和预测激活的不一致性度量
不一致性识别 。 为了识别用于攻击检测的输入的非语义模式 , 我们通过比较自然图像识别和物理对抗性攻击 , 检查其在 CNN 推理过程中的影响 。 图 5 展示了一个典型的基于对抗性补丁的物理攻击 。 左边圆圈中的图案是来自输入图像的主要激活源 , 右边的条形图是最后一个卷积层中的神经元的激活 。 从输入模式中我们识别出原始图像中的对抗性补丁和主要激活源之间的显著差异 , 称为输入语义不一致(Input Semantic Inconsistency) 。 从预测激活量级方面 , 我们观察到对抗性输入和原始输入之间的另一个区别 , 即预测激活不一致(Prediction Activation Inconsistency) 。
推荐阅读







- 识别|外卖界又一黑科技 饿了么计划2022年覆盖100000顶智能头盔
- 语言识别|AI技术,让我们“听”懂聋人
- AI财经社|美团公布共享单车指纹解锁专利,网友调侃称期待人脸识别解锁
- Huawei|传大众与华为成立合资自动驾驶技术公司 回应称现阶段没有可以确认的消息
- 视点·观察|如何避免社交电商以“经销之名”行“传销之实”
- 模式|华为拍摄月亮专利获授权:可自动识别月亮并对焦
- 广西|秒级核验通行,广西机场推广刷身份证自动核验健康码
- 澎湃新闻|如何避免社交电商以“经销之名”行“传销之实”
- IT|达拉斯希望成为福特下一个自动驾驶汽车工厂的所在地
- 界面新闻|华为月亮拍摄专利获授权,可自动识别月亮并对焦