我们认为 , 无论是从参与的厂商(AI产业相关大咖云集) , 还是其接近市场和用户实际应用场景(项目设置更符合实际应用)以及独立第三方的分析和解读 , MLPerf?榜单不仅权威 , 还更接地气 , 是它对于市场和用户的真正价值所在 , 即市场和用户以此榜单作为标准做出的选择 , 与其在实际业务场景中的应用表现应相差无几 。
当我们明确了MLPerf?榜单的权威性及实用性再来看看中国系统厂商浪潮信息的表现 。
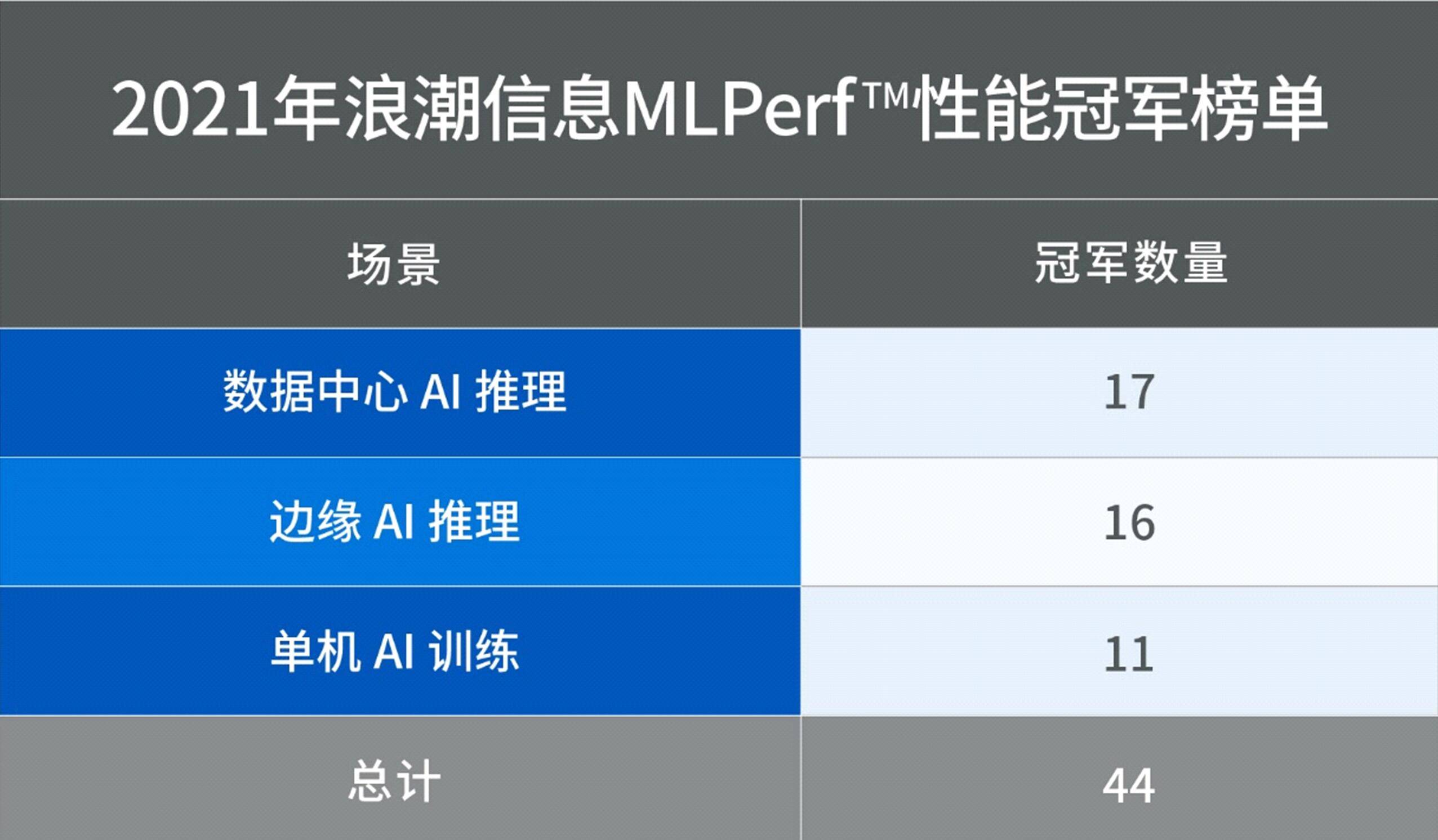
2021年 , 浪潮AI服务器在MLPerf?数据中心AI推理场景的总32项任务中斩获17项冠军 , 在边缘AI推理场景的总31项任务中斩获16项冠军 , 从云到边全面领先;在单机AI训练场景的16项任务中浪潮AI服务器共斩获11项冠军 。
文章图片
可以说 , 无论是从MLPerf?榜单 , 还是实际应用的角度 , 中国系统厂商在AI计算确实走在了前列 。
系统级创新 , 榜单背后的硬核支撑
所谓知其然 , 需知所以然 。 中国系统厂商缘何会在MLPerf?榜单中名列前茅?
众所周知 , 对于AI算力 , 虽然芯片是核心 , 但事实是 , 芯片从造出来到大规模用起来 , 往往还隔着一个巨大的产业链鸿沟 , 主要体现在 , 算力的供给需要构建算力平台 , 需要解决架构设计、核心部件、高速互联、散热设计等一系列工程问题 。 而要解决这些问题 , 就涉及到系统创新 。
需要提醒的是 , 千万不要忽视系统创新的难度 , 具体到一台AI服务器 , 除了芯片外 , 系统厂商需要解决超过300个关键的过程控制点和设计难题 , 同时还需要解决与算法框架和AI应用的优化和适配等挑战 。
业内知道 , 与单纯的芯片厂商相比 , 系统厂商由于长期位居服务市场和客户的最前沿(离市场和用户最近) , 最知晓他们的痛点和需求 , 所以在我们看来 , 有且只有系统厂商 , 依靠其系统级的创新能力 , 有的放矢 , 化解我们前述面临的挑战 , 最终释放出AI算力的最大价值 , 高效率地输出算力 , 满足市场和用户实际的应用场景及业务需求 。 而这一规律 , 通过此次和全年霸榜MLPerf?的中国系统厂商浪潮信息在AI计算系统创新方面的系统设计和全栈优化能力的表现得到了很好的验证 。
具体表现在 , 针对AI训练中常见的密集I/O传输瓶颈 , 浪潮AI服务器以领先设计大幅降低通信延迟 , 极大提升了AI训练效率;同时 , 针对高负载多GPU协同任务调度 , 对NUMA节点与GPU之间的数据传输进行全面优化和深度调校 , 确保训练任务中的数据IO无阻塞;在散热层面 , 针对目前业界功率最高的A100-SXM-80GB(500W) GPU , 浪潮率先开发的先进冷板液冷系统 , 确保GPU在全功率甚负载下依然稳定工作 , 将AI计算系统的性能发挥到极致 。
推荐阅读





- 生活|气笑了,这APP的年度报告是在嘲讽我吧
- 语境|B站2021个人年度报告发布:你共计看了多少个视频
- 地球|没有了人类,地球气候环境会怎样|澎湃问吧年度盘点(上)
- 网友|重磅!2021年度『量化』关键词揭榜
- 挖矿|深信服2021年度安全技术盘点,解决了用户哪些需求呢?
- 短片|马蜂窝推全球首份《星际太空旅行指南》,发布年度短片
- 征程|2021年度图片报道·新征程|31张日历记录:中国在路上
- 人物|继“年度恶人”之后 扎克伯格又被批“殖民”夏威夷
- 华为|年度盘点 | 人享其行、物优其流 交通数字化转型开启行业发展新篇章
- 飞船|2021中国航天年度照片,每一张都让人心潮澎湃