实验结果
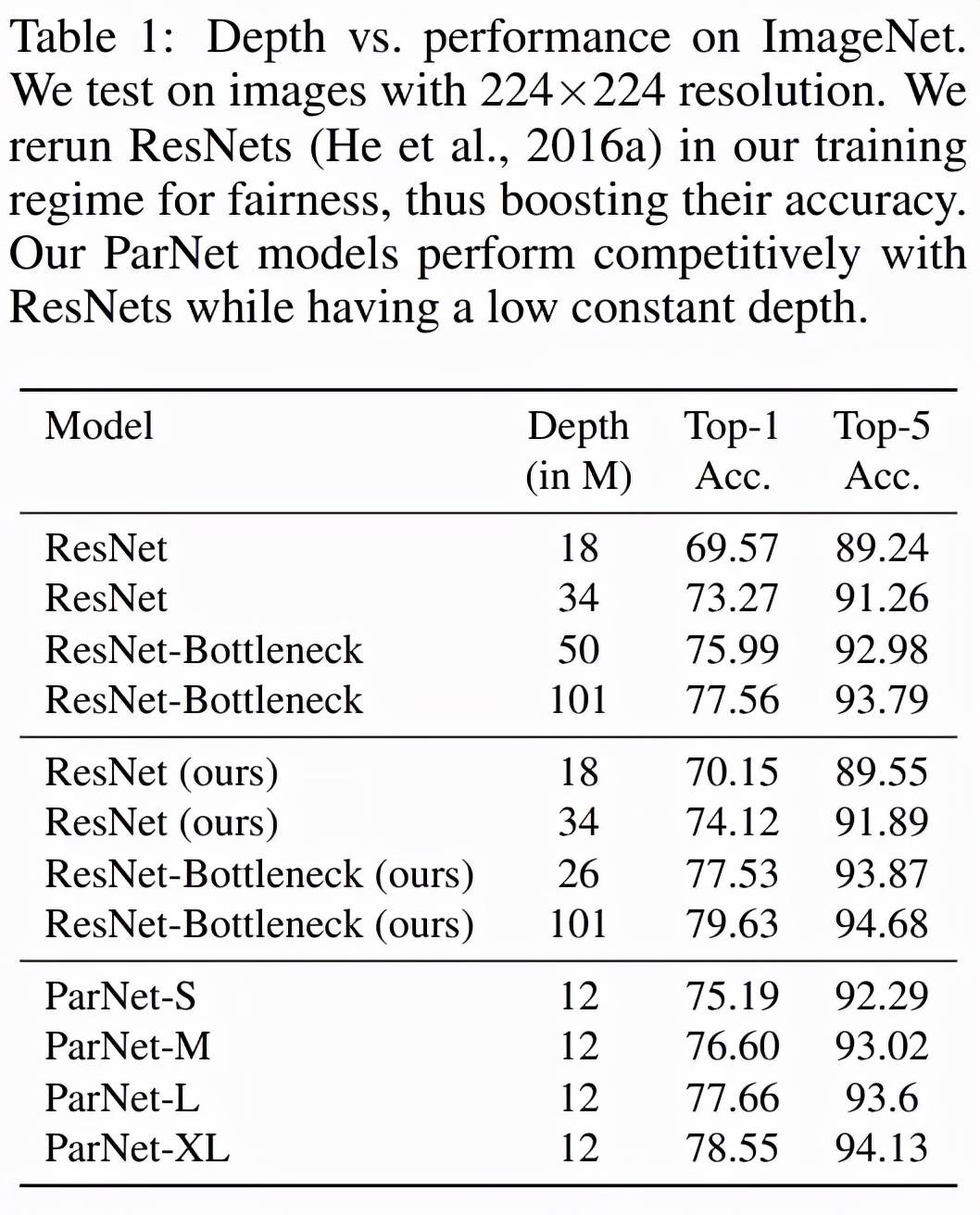
表 1 展示了 ParNet 在 ImageNet 上的性能 。 该研究发现 , 深度仅为 12 的网络就可以实现惊人的高性能 。 为了与 ResNet 进行公平比较 , 研究者使用相同的训练协议和数据增强重新训练 ResNet , 这将 ResNet 的性能提升到了超越官方结果的水平 。 值得注意的是 , 该研究发现 ParNet-S 在参数数量较少的情况下(19M vs 22M)在准确率上比 ResNet34 高出 1 个百分点以上 。 ParNet 还通过瓶颈设计实现了与 ResNet 相当的性能 , 同时深度减少到 1/4-1/8 。
文章图片
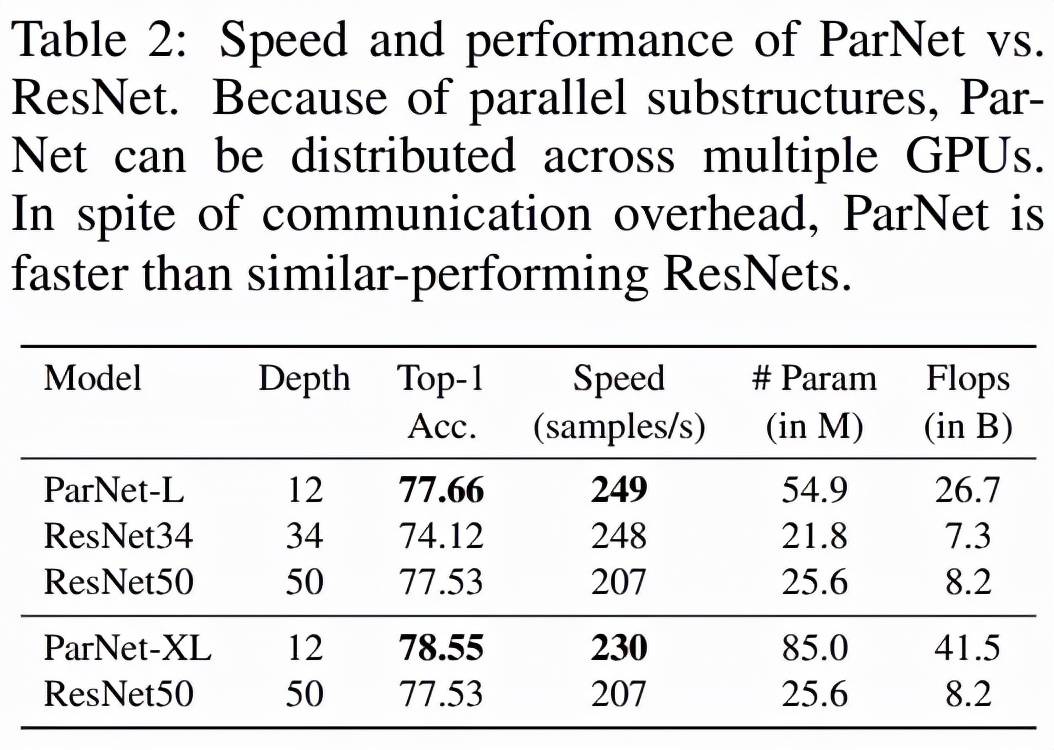
如下表 2 所示 , ParNet 在准确率和速度上优于 ResNet , 但参数和 flop 也更多 。 例如 , ParNet-L 实现了比 ResNet34 和 ResNet50 更快的速度和更好的准确度 。 类似地 , ParNet-XL 实现了比 ResNet50 更快的速度和更好的准确度 , 但具有更多的参数和 flop 。 这表明使用 ParNet 代替 ResNet 时存在速度与参数和 flop 之间的权衡 。 请注意 , 可以通过利用可以分布在 GPU 上的并行子结构来实现高速 。
文章图片
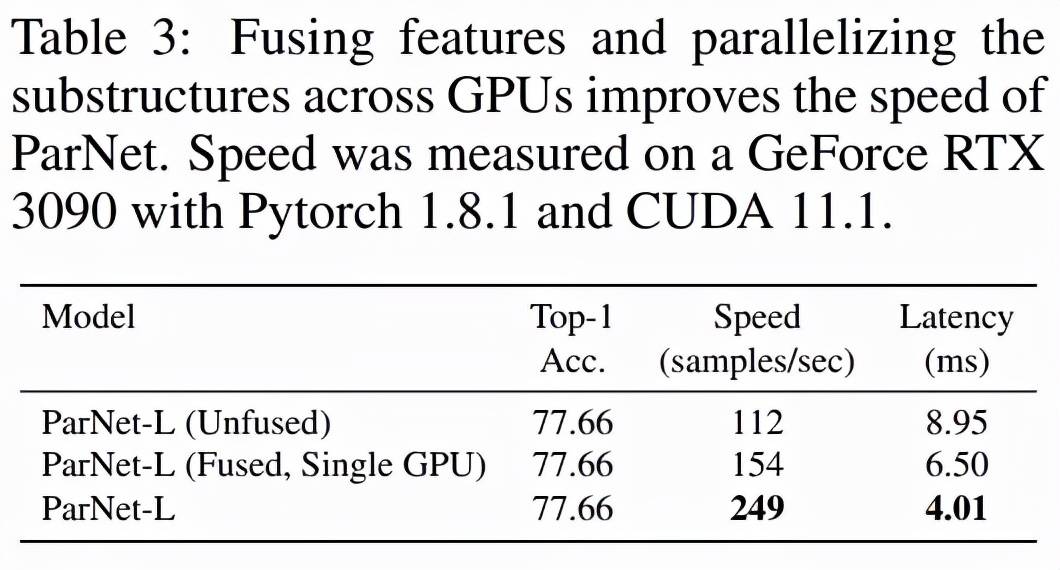
该研究测试了 ParNet 三种变体的速度:未融合、融合和多 GPU , 结果如下表 3 所示 。 未融合的变体由 RepVGG-SSE 块中的 3×3 和 1×1 分支组成 。 在融合变体中 , 使用结构重参数化技巧将 3×3 和 1×1 分支合并为一个 3×3 分支 。 对于融合和未融合变体 , 该研究使用单个 GPU 进行推理 , 而对于多 GPU 变体 , 使用了 3 个 GPU 。 对于多 GPU 变体 , 每个流都在单独的 GPU 上启动 。 当一个流中的所有层都被处理时 , 来自两个相邻流的结果将在其中一个 GPU 上连接并进一步处理 。 为了跨 GPU 传输数据 , 该研究使用了 PyTorch 中的 NCCL 后端 。
文章图片
该研究发现尽管存在通信开销 , 但 ParNet 仍可以跨 GPU 有效并行化以进行快速推理 。 使用专门的硬件可以减少通信延迟 , 甚至可以实现更快的速度 。
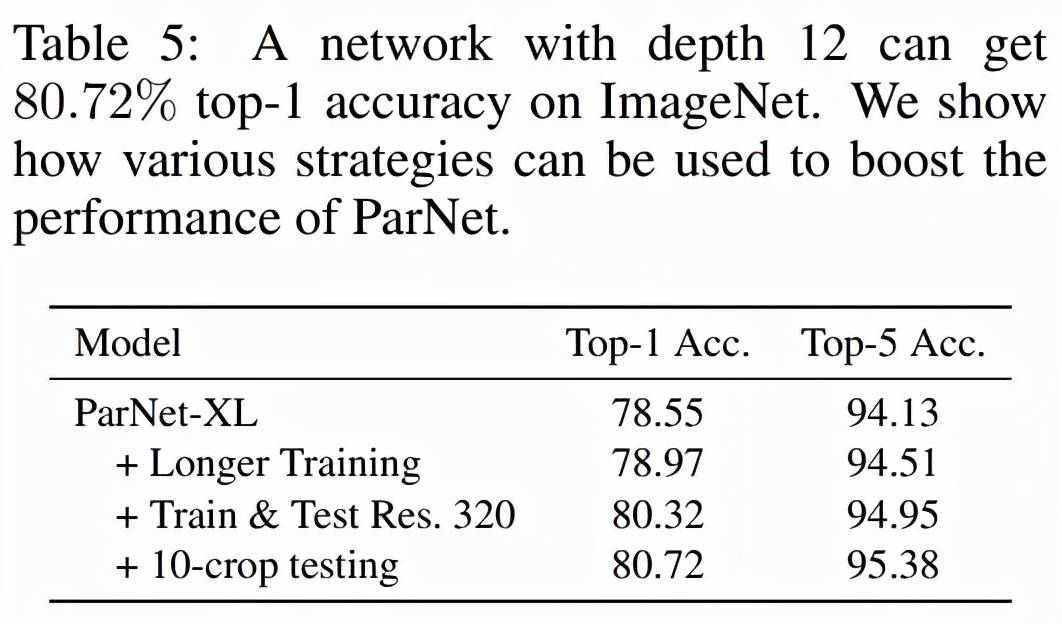
表 5 展示了提高 ParNet 性能的其他方法 , 例如使用更高分辨率的图像、更长的训练机制(200 个 epoch、余弦退火)和 10-crop 测试 。 这项研究有助于评估非深度模型在 ImageNet 等大规模数据集上可以实现的准确性 。
文章图片
MS-COCO (Lin 等 , 2014) 是一个目标检测数据集 , 其中包含具有常见对象的日常场景图像 。 研究者用 COCO-2017 数据集进行了评估 。 如下表 4 所示 , 即使在单个 GPU 上 , ParNet 也实现了比基线更高的速度 。 这阐明了如何使用非深度网络来制作快速目标检测系统 。
推荐阅读





- 技术|“2”类医械有重大进展:神经介入产品井喷、基因测序弯道超车
- 重大进展|“2”类医械有重大进展:神经介入产品井喷、基因测序弯道超车
- Tencent|原生版微信上架统信UOS应用商店:适配X86、ARM、LoongArch架构
- 国家|2022上海国际热处理、工业炉展览会
- IT|8号线、14号线将全线贯通 北京地铁?今年开通线路段创纪录
- 软件和应用|iOS/iPadOS端Telegram更新:引入隐藏文本、翻译等新功能
- Intel|Intel谈DDR5内存价格贵、缺货问题:新技术升级在所难免
- IT|宝马电动转型成果初显:i4、iX供不应求 新能源车销量已破百万
- 制造业|稳健前行开新局 制造业未来五年转型升级迎来“加速度”
- 银行|银行卡、社保卡可直接刷卡坐公交 上海公交开始试点