降采样和融合 block
除了输入和输出大小相同的 RepVGG-SSE block 之外 , ParNet 还包含降采样(downsampling)和融合 block 。 降采样 block 降低了分辨率并增加了宽度以实现多尺度(multi-scale)处理 , 而融合 block 将来自多个分辨率的信息组合 。 在降采样 block 中 , 没有残差连接(skip connection);相反 , 该研究添加了一个与卷积层并行的单层 SE 模块 。
此外 , 该研究在 1×1 卷积分支中添加了 2D 平均池化 。 融合 block 和降采样 block 类似 , 但还包含一个额外的串联(concatenation)层 。 由于串联 , 融合 block 的输入通道数是降采样 block 的两倍 。 为了减少参数量 , 该研究的降采样和融合 block 的设计如下图所示 。
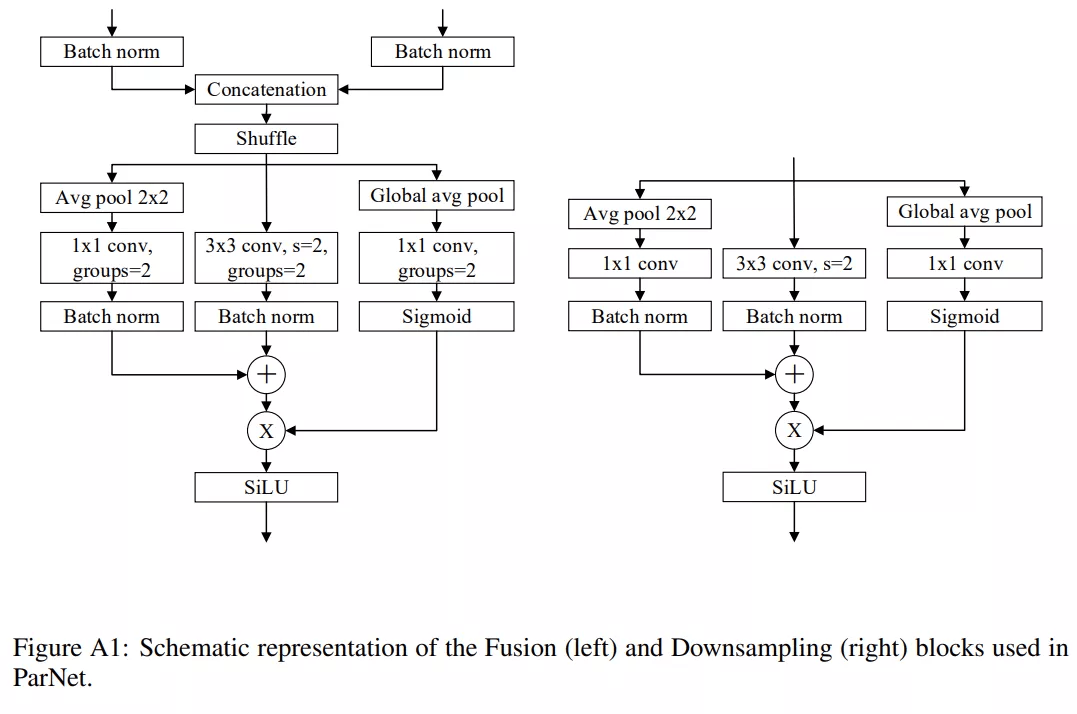
文章图片
网络架构
图 2a 展示了用于 ImageNet 数据集的 ParNet 模型示意图 。 初始层由一系列降采样块组成 , 降采样 block 2、3 和 4 的输出分别馈送到流 1、2 和 3 。 研究者发现 3 是给定参数预算的最佳流数(如表 10 所示) 。 每个流由一系列不同分辨率处理特征的 RepVGG-SSE block 组成 。 然后来自不同流的特征由融合 block 使用串联进行融合 。 最后 , 输出被传递到深度为 11 的降采样 block 。 与 RepVGG(Ding 等, 2021)类似 , 该研究对最后一个降采样层使用更大的宽度 。
扩展 ParNet
据观察 , 神经网络可以通过扩大网络规模来获得更高的准确度 。 之前的研究 (Tan & Le, 2019) 扩展了宽度、分辨率和深度 。 由于本研究的目标是评估是否可以在深度较低的情况下实现高性能 , 因此研究者将模型的深度保持不变 , 通过增加宽度、分辨率和流数来扩展 ParNet 。
对于 CIFAR10 和 CIFAR100 , 该研究增加了网络的宽度 , 同时将分辨率保持为 32 , 流数保持为 3 。 对于 ImageNet , 该研究在三个不同的维度上进行了实验 , 如下图 3 所示 。
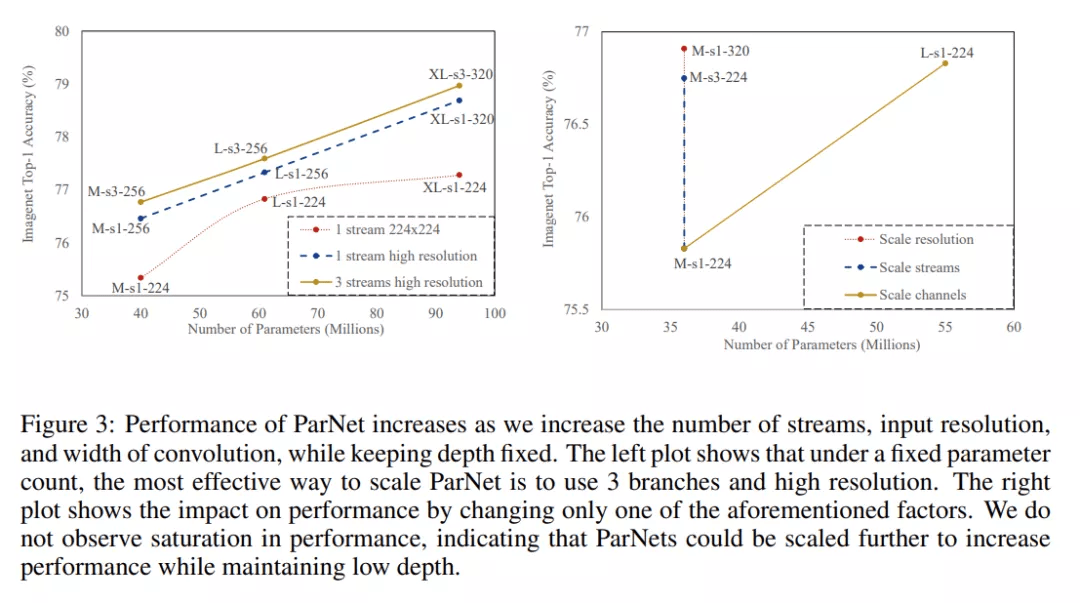
文章图片
并行架构的实际优势
目前 5 纳米光刻工艺已接近 0.5 纳米晶硅尺寸 , 处理器频率进一步提升的空间有限 。 这意味着神经网络的更快推理必须依赖计算的并行化 。 单个单片 GPU 的性能增长也在放缓 , 预计传统光刻可实现的最大芯片尺寸将达到 800 平方毫米(Arunkumar 等 , 2017) 。 总体而言 , 未来在处理器频率、芯片尺寸以及每个处理器的晶体管数等方面都将维持一个平稳状态 。
为了解决这个问题 , 最近的一些工作提出了多芯片模块 GPU (MCM-GPU) , 比最大的可实现单片 GPU 更快 。 用中型芯片取代大型芯片有望降低硅成本 。 这样的芯片设计有利于具有并行分支的分区算法 , 算法之间交换有限的数据并且尽可能地分别独立执行 。 基于这些因素 , 非深度并行结构将有利于实现快速推理 , 尤其是对于未来的硬件 。
推荐阅读







- 技术|“2”类医械有重大进展:神经介入产品井喷、基因测序弯道超车
- 重大进展|“2”类医械有重大进展:神经介入产品井喷、基因测序弯道超车
- Tencent|原生版微信上架统信UOS应用商店:适配X86、ARM、LoongArch架构
- 国家|2022上海国际热处理、工业炉展览会
- IT|8号线、14号线将全线贯通 北京地铁?今年开通线路段创纪录
- 软件和应用|iOS/iPadOS端Telegram更新:引入隐藏文本、翻译等新功能
- Intel|Intel谈DDR5内存价格贵、缺货问题:新技术升级在所难免
- IT|宝马电动转型成果初显:i4、iX供不应求 新能源车销量已破百万
- 制造业|稳健前行开新局 制造业未来五年转型升级迎来“加速度”
- 银行|银行卡、社保卡可直接刷卡坐公交 上海公交开始试点