机器之心专栏
机器之心编辑部
图灵奖得主 Yoshua Bengio 和 Yann LeCun 在 2020 年的 ICLR 大会上指出 , 自监督学习有望使 AI 产生类人的推理能力 。 该观点为未来 AI 领域指明了新的研究方向——自监督学习是一种不再依赖标注 , 而是通过揭示数据各部分之间关系 , 从数据中生成标签的新学习范式 。近年来 , 自监督学习逐渐广泛应用于计算机视觉、自然语言处理等领域 。 随着该技术的蓬勃发展 , 自监督学习在图机器学习和图神经网络上的应用也逐渐广泛起来 , 图自监督学习成为了图深度学习领域的新发展趋势 。
本文是来自澳大利亚蒙纳士大学(Monash University)图机器学习团队联合中科院、联邦大学 , 以及数据科学权威 Philip S. Yu 对图自监督学习领域的最新综述 , 从研究背景、学习框架、方法分类、研究资源、实际应用、未来的研究方向的方面 , 为图自监督学习领域描绘出一幅宏伟而全面的蓝图 。

文章图片
全文链接:https://arxiv.org/pdf/2103.00111.pdf
1. 绪论
近年来 , 图深度学习广泛应用于电子商务、交通流量预测、化学分子研究和知识库等领域 。 然而 , 大多数工作都关注在(半)监督学习的学习模式中 , 这种学习模式主要依赖标签信息对模型进行训练 , 导致了深度学习模型获取标签成本高、泛化能力能力不佳、鲁棒性差等局限性 。
自监督学习是一种减轻对标签数据的依赖 , 从而解决上述问题的新手段 。 具体地 , 自监督学习通过解决一系列辅助任务(称为 pretext task , 代理任务)来进行模型的学习 , 这样监督信号可以从数据中自动获取 , 而无需人工标注的标签来对模型进行监督训练 。
自监督学习目前已经被广泛应用于计算机视觉(CV)和自然语言处理(NLP)等领域 , 具体技术包括词嵌入、大规模语言预训练模型、图像的对比学习等 。 然而 , 与 CV/NLP 领域不同 , 由于图数据处于不规则的非欧几里得空间 , 其具有独特的特点 , 包括:1)需要同时考虑特征信息与不规则的拓扑结构信息;2)由于图结构的存在 , 数据样本(节点)间往往存在依赖关系 。 因此 , 图领域的自监督学习(graph self-supervised learning)无法直接迁移 CV/NLP 领域的代理任务设计 , 从而为图自监督学习带来了独有的概念定义和分类方法 。
不同领域的自监督代理任务对比
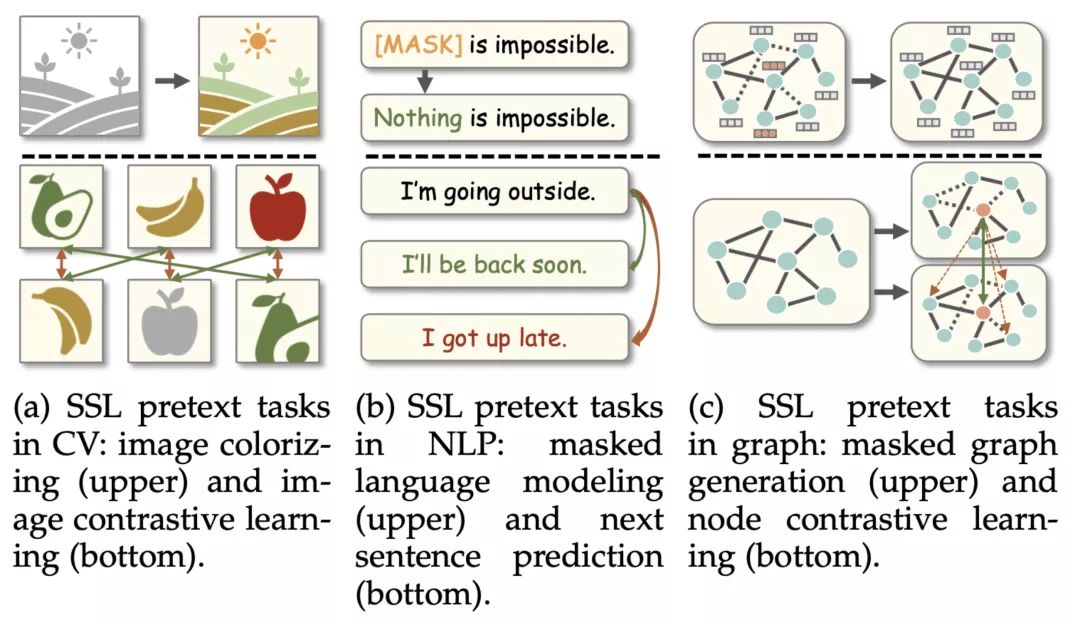
文章图片
图自监督学习的历史最早可追溯到经典的图嵌入方法 , 包括 DeepWalk、Line 等 , 而经典的图自编码器(GAE)模型也可被视为一种图自监督学习 。 自 2019 年以来 , 一系列新工作席卷了图自监督学习领域 , 涉及到的技术包括但不限于对比学习、图性质预测、图生成学习等 。 然而 , 目前缺少系统性的分类法对这些方法进行归类 , 同时该技术相关的框架与应用也没有得到规范化的统计与调查 。
推荐阅读







- 文章|美媒文章:古人类领域2021年六大新突破
- 核心|中科大陈秀雄团队成功证明凯勒几何两大核心猜想,研究登上《美国数学会杂志》
- 器件|6G、量子计算、元宇宙…上海市“十四五”聚焦这些前沿领域
- 领域|上海市电子信息产业“十四五”规划:以集成电路为核心先导
- VIA|x86研发团队卖给Intel后 VIA出售厂房和设备:北美分部就此终结
- 前瞻|6G、量子计算、元宇宙……上海市“十四五”聚焦这些前沿新兴领域
- 团队|深信院41项科研项目亮相高交会 11个项目获优秀产品奖
- 产品|数梦工场通过CMMI V2.0 L5评估,再获全球软件领域最高级别认证加冕
- 团队|玉米和水稻基因组引导编辑效率提高3倍
- 电磁场|首届全国颠覆性技术创新大赛领域赛(青岛)举办