2021年7月1日 , Graphcore(拟未科技)正式公布其参与的首次MLPerf?提交结果 。 MLPerf还对比了市面上的Graphcore系统与NVIDIA的最新产品 , 结果证实Graphcore在“每美元性能”(Performance-Per-Dollar)指标上稳居领先地位 。
MLPerf基准测试
据Graphcore高级副总裁兼中国区总经理卢涛(Jason Lu)介绍 , MLPerf代表了今天工业界比较主流部署的应用场景 。 全球有各种各样的处理器 , 也有各种各样衡量性能的维度 , 所以在对比不同处理器的时候 , 所对比的维度可能不尽相同 。 相比无论在整体架构上、还是在计算机体系结构上都比较类似的CPU , 各个AI处理器的架构之间会有较大的差异 , 对于最终用户来说 , 很难比较出来所选择的架构对于业务受益产生的影响 , 而MLPerf可让用户在选择AI处理器时不必再特别关注各个厂商的基准测试之间的差别 。 从某种意义上 , MLPerf将不同的厂商拉到了同一个维度里进行对话 , 因此MLPerf对于AI芯片产业具有较大的参考意义 。
MLPerf的提交工作量非常大 , 对于目前500名左右员工的Graphcore来说 , 这是一项很大的挑战并需要很大的投资 。 为了Graphcore的第一次MLPerf提交 , 公司有十几个团队成员分别直接、间接地参与了这个项目 , 并投入了至少半年以上的时间 。 而提交MLPerf从某种意义上证明 , 和以前相比Graphcore的实力有了进一步提高 , 也意味着有资源来做提交MLPerf的相关工作 。
卢涛还说 , Graphcore今后会继续积极参与MLPerf的提交 , 提供一些不同的任务 , 让MLPerf的工作负载(Workload)更具代表性 。
据悉 , Graphcore在这次MLPerf中提交了两个模型 , 主要聚焦在关键图像分类和自然语言处理的应用基准测试类别 。 对于MLPerf图像分类基准 , Graphcore使用了流行的ResNet-50版本1.5模型 , 并在ImageNet数据集上训练 , 以达到适用于所有提交情况的准确率 。
对于自然语言处理 , 该公司使用了BERT-Large模型和选取的一个代表性片段 , 这一片段大约占总训练计算工作负载的10% , 并使用维基百科数据集进行训练 。 据了解 , Graphcore决定提交使用ResNet-50和BERT的图像分类和自然语言处理 , 很大程度上是由客户和潜在客户驱动的 , 这两个模型在相应领域里面颇具代表意义 , 且已被广为使用 。

文章图片
图:Graphcore提交的两个模型 , 对于图像分类提交了ResNet-50 , 对于自然语言处理提交了BERT
Graphcore所提交的硬件形态也是两个 , 即IPU-POD16和IPU-POD64 。 这两个硬件形态都是基于基础构建块IPU-M2000进行不同配置组合的 , 该公司此次在IPU-POD16和IPU-POD64上都提交了ResNet-50和BERT两个训练任务的结果 。

文章图片
图:Graphcore提交的两种硬件形态 , IPU-POD16和IPU-POD64
MLPerf测试包含开放分区和封闭分区两个提交分区 。 就封闭分区来讲 , 其严格要求提交者使用完全相同的模型实施和优化器方法 , 包括定义超参数状态和训练时期 。 开放分区则相对灵活一些 , 虽然需要保证和封闭分区完全相同的模型准确性和质量 , 但支持更灵活的模型实施以促进创新 。 尽管对于像Graphcore IPU这样的创新架构 , 开放分区更能体现自己的优越性 , 但Graphcore还是选择在开放和封闭分区都进行提交 。 而即使是在相对限制的封闭分区上 , 测试结果也证明了Graphcore的优越性能 。
Graphcore中国工程总负责人、AI算法科学家金琛详细介绍了测试结果:在IPU-POD16上 , 自然语言处理模型BERT在MLPerf v1.0 Training开放分区中的训练时间小于半个小时 。 而在IPU-POD64上 , BERT在开放分区的训练时间小于10分钟 , 对于很多科研工作者来说这是非常令人兴奋的消息 , 这意味着在训练过程中他们可以更快地得到研究结果 。 而对于图像分类模型ResNet-50 , 在IPU-POD16上的训练时间也是半小时左右 , 在IPU-POD64上则仅需不到15分钟 。
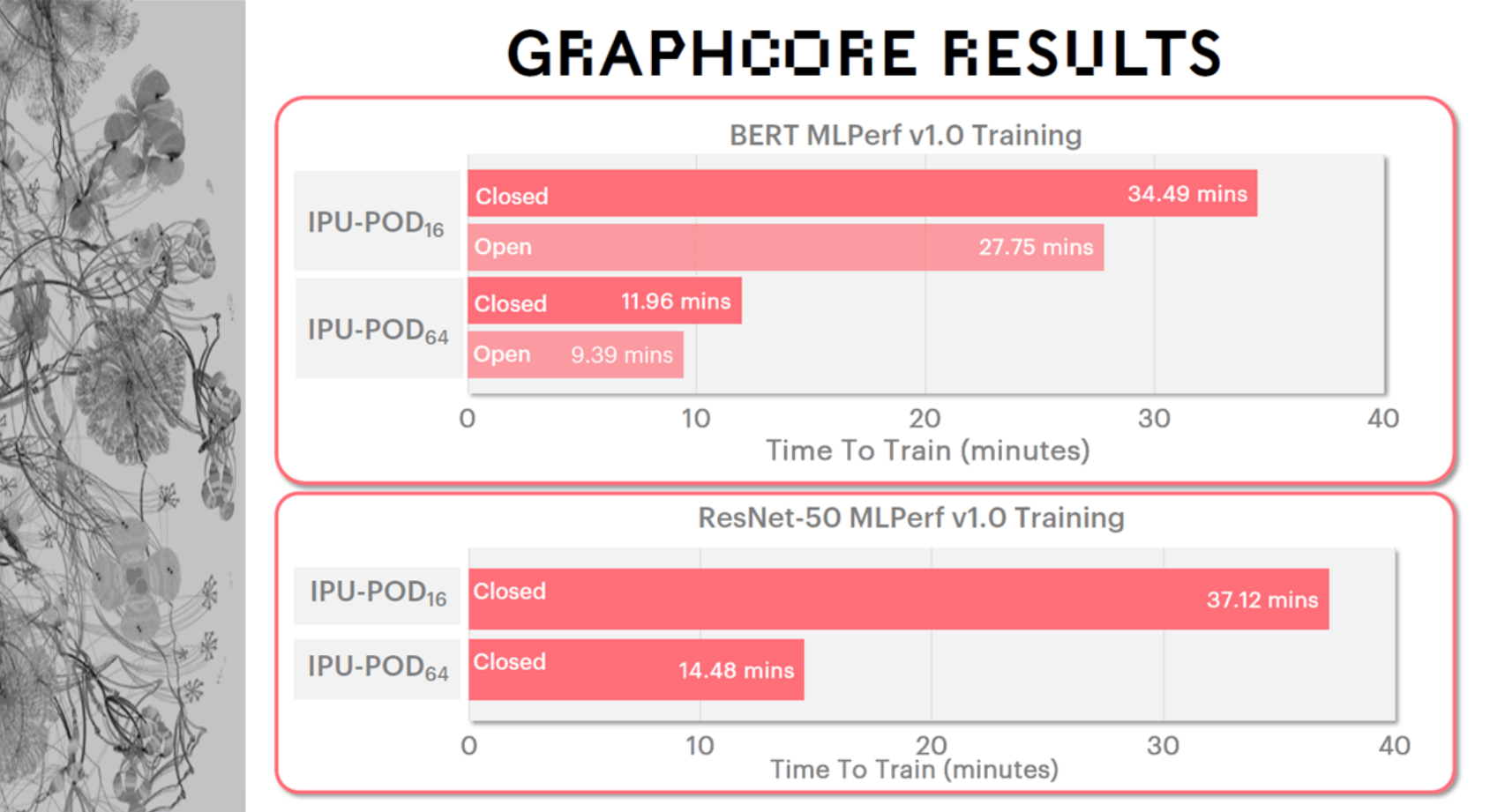
文章图片
图 | Graphcore提交的ResNet-50与BERT模型在提交的两种硬件IPU-POD16和IPU-POD64上
“每美元性能”指标
不同厂商会使用不同的系统提交训练任务 , 以ResNet-50为例 , 当对比Graphcore在MLPerf提交的IPU-POD16与NVIDIA公司提交的DGX A100 640G版本时 , IPU-POD16上ResNet-50的MLPerf训练时间是37分钟左右 , DGX A100 640G版本上是28分钟左右 。 IPU-POD16的市场指导价是将近15万美金/台 , DGX A100的厂商指导零售价则接近30万美金/台 。 如果将训练收益和目录价折算成性价比的话 , IPU-POD16相对DGX A100 640G版本的性价比收益有1.6倍 。
类似地对比两者在BERT的训练表现时 , IPU-POD16上BERT的MLPerf训练时间是34分钟左右 , NVIDIA是21分钟左右 , 折算成性价比的话 , IPU-POD16相对DGX A100 640G版本的性价比收益有1.3倍 。

文章图片
Graphcore在“每美元性能”指标上的优越性证明了自己的经济性 , 这将可以更好地帮助客户实现其AI计算目标 , 同时 , 由于IPU专为AI构建的架构特点 , Graphcore系统还可以解锁下一代模型和技术 。
Graphcore技术团队
Graphcore IPU(智能处理器)硬件和Poplar软件帮助创新者在机器智能领域取得新突破 。 据卢涛介绍 , Graphcore中国团队主要聚集了三种核心软件人才:首先是机器学习框架方面的人才 , 负责跟机器学习框架的合作、适配 , 以及框架周边的一些库和算子覆盖等相关工作 , 库和算子等代表着支撑不同应用的底层能力 。

文章图片
图 | Graphcore高级副总裁兼中国区总经理卢涛;Graphcore中国工程总负责负责人、AI算法科学家金琛
【MLPerf|Graphcore公布MLPerf提交结果】另外是模型开发 , 即AI方面的人才 。 Graphcore模型开发方向的人才覆盖较广 , 包含视觉、自然语言处理、语音、多模态等多方面相关算法模型的团队 , 此后Graphcore还计划组建强化学习团队 。 还有一类人才负责基于垂直行业应用的、更高层的SDK , 包括AI模型和非模型 。
推荐阅读







- 平板|MIUI 13推出无字模式,内测机型名单公布
- 汽车|现代汽车公布CES 2022参展主题:打造机器人和元宇宙全新移动出行体验
- Xiaomi|小米公布小米12基于Android 12的全系内核源码
- IT|TuSimple半挂卡车道路全无人驾驶视频公布:全长130千米
- Samsung|[图]Galaxy S21 FE官方保护套公布 共计15款
- 音箱|跨设备自然流转!小米MIUI 13妙享中心支持设备列表公布
- 平板|小米公布 MIUI 13 、MIUI Home、MIUI TV 发版计划
- Lenovo|联想新款拯救者Y7000P外观公布:比上代薄11.6%
- IT|约36-44万元 丰田首款电动车bZ4X海外价格公布
- 影像|官方公布 5 米光学 02 星融合影像图,卫星刚完成发射