机器之心专栏
作者:张颖、王晓瑞、王仲远
语音转换的应用在电影配音、角色模仿、复刻人物音色等领域至关重要 。 近年来 , 基于深度学习的快速发展 , 语音转换已经取得很大的进步 , 然而小数据的语音转换仍是个热点问题 。 来自快手MMU的研发人员提出了一种基于说话人感知模块(SAM)的单样本语音转换的解决方案 , 仅通过说话人的单句语音样本提取用户的音色表征 , 就可以实现该说话人作为目标说话人音色的语音转换 。语音转换(VC)是指在保证一句话内容不变的基础上 , 将原始语音中说话人音色迁移到目标说话人音色 。 语音转换在电影配音、角色模仿以及复刻人物音色等方面都有重要的应用 。
当前基于深度学习实现到特定目标说话人的语音转换已经取得很大的进步 , 例如基于 CycleGAN、VAE 以及 ASR 的语音转换方法都可以很好的实现到训练集内说话人的语音转换 。
然而 , 如果想要增加一个目标说话人音色 , 或者进行用户音色的自定义复刻 , 通常需要大量的说话人数据以重新训练一个以该说话人音色为目标音色语音转换模型 , 或者通过少量数据对现有模型进行自适应训练 。 实际应用中 , 数据库录制的周期和成本都比较高 , 而对于普通用户而言 , 也很难获得用户大量的语音数据 。 因此 , 小数据的语音转换成为亟待解决的热点问题 。
【目标|一句话复制你的音色:快手单样本语音转换研究入选ICASSP 2021】而来自快手负责音频技术研发部门 MMU 的研发人员提出了一种基于说话人感知模块(SAM)的单样本语音转换的解决方案 。 该方案仅通过说话人的单句语音样本提取用户的音色表征 , 就可以实现该说话人作为目标说话人音色的语音转换 。 目前该成果已被 ICASSP 2021 接收 , 并且已经在中国提交发明专利申请 。
论文地址:
https://ieeexplore.ieee.org/document/9414081
基于说话人感知模块的单样本语音转换
要完成单样本的语音转换 , 核心有两点:一是完成对语音中内容特征的提取;二是利用目标说话人的单样本完成目标说话人的特征向量的解耦 , 然后将目标说话人的特征向量与提取的语音内容特征进行耦和 , 完成到该目标音色的语音转换 。
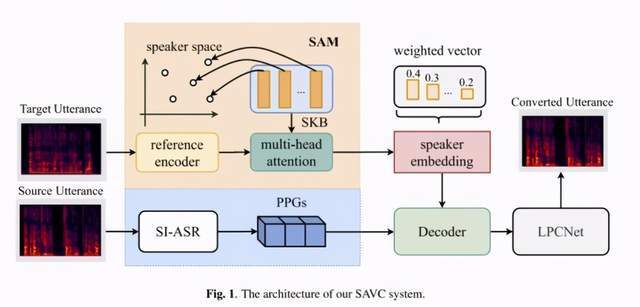
文章图片
说话人感知语音转换(SAVC)系统 , 其中包括:
预训练的说话人无关的语音识别模型(SI-ASR) , 用以从语音中提取说话人无关的声学后验概率(PPGs) 。 声学后验概率可以表征语音每帧的内容信息 。
说话人感知模块(SAM) , 用以从语音中解耦出说话人特征向量;为了避免语音中内容信息对说话人特征向量提取的干扰 , 辅助模型更好的解耦说话人的信息 , SAM 的输入特征和 SI-ASR 的输入特征来自同一说话人的不同语音 。
解码器 , 对声学后验概率和说话人向量进行耦和 , 预测特定说话人相关的声学特征 。
声码器 , 采用 LPCNet 作为后端声码器 , 将解码器预测的声学特征重建为语音信号 。
SAM 的设计受启发于声纹识别的成果以及注意力机制的应用 , 包括以下三个模块 。
参考编码器
对变长的目标说话人语音特征进行编码 , 因为原始说话人语音和目标说话人语音通常不等长 , 而且理论上说话人向量不随说话内容改变 , 因此用帧级别的特征向量表示目标说话人的参考编码显然是不合适的 。 将其压缩为定长的参考编码向量不仅可以使其对时域信号变化不敏感 , 也以方便进一步与原始语音中提取的 PPGs 进行特征耦和 。
假设输入是 X=[x_1,x_2,…,x_T] , T 是输入的长度 , 因此目标说话人编码向量可以表示为 R=RefEncoder(X) , 其中 R∈ , d_r 是定长目标说话人编码向量的维度 。
说话人先验知识模块(SKB)
声纹识别任务中通常使用 x-vector、i-vector 等特征表征不同的说话人向量 , 这些向量分布在同一超曲面空间 , 不仅可以表征不同说话人的区别 , 也包含了不同说话人之间的相关性 。 通过预训练的声纹模型提取说话人向量 x-vector , 多个说话人的向量组合成 SKB 。 SKB 中的数据分布可以看作是说话人的表征空间 , 更多的说话人向量可以将说话人空间的信息表征的更详细 。
假设说话人的向量特征维度是 1×d_x , 挑选 N 个说话人作为说话人先验知识模块的基础说话人 , 在挑选训练集说话人的时候考虑到性别均衡(一半男性 , 一半女性) 。 那么 SKB 可以表示为 S=[S_1 , S_2,…,S_N] , 其中 S∈ 。 文章使用的说话人向量 x-vector 为 200 维 , 选择 200 个基础说话人 。
多头注意力层
用于建模全局说话人向量 , 对参考说话人向量和 SKB 求距离相似性 。 SKB 中一个特定的说话人向量可以看成是说话人表示空间的一个坐标点 。 因此 , 一个新的说话人向量可以通过对所有基础说话人在先验说话人向量空间表征的加权量化表示 。
自注意力层的输出可以表示为:
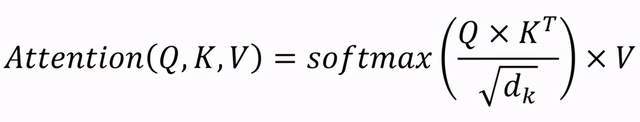
文章图片
其中 , Q,K,V 是注意力的查询(Query)、以及键(Key)值(Value) , d_k 用于表示 Key 的维度 。
多头注意力层的计算可以表示为:
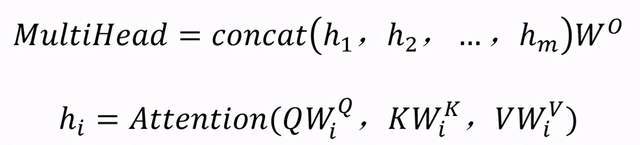
文章图片
文章中选择四头注意力层 , 且 W_i^Q , W_i^K , W_i^V,W^O 为参数矩阵 。
最终得到的目标说话人向量表示为:
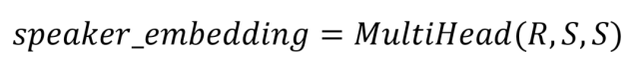
文章图片
SAM 模块网络参数如下表所示:
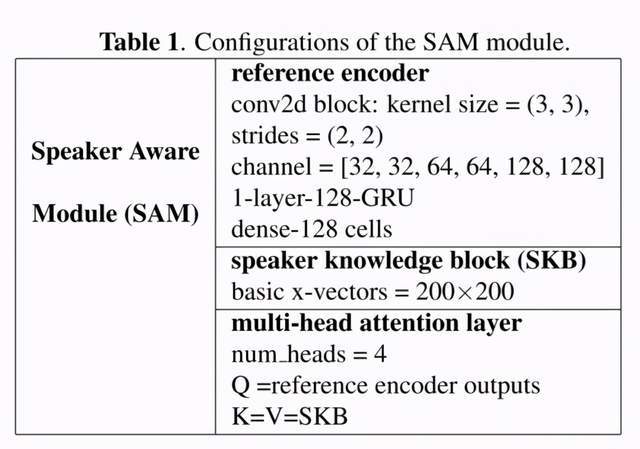
文章图片
实验对比
文章中对比了几种当前最优的基于单样本的语音转换网络 , 基线模型和文章中提出的 SAVC 模型均使用 Aishell-1 训练集的 340 人中文数据作为训练数据集;选择 Aishell-1 测试集中的集外说话人作为测试时使用的原始说话人和目标说话人 。
实验对比结果如下 , 可以看出该论文方法在单样本语音转换任务上主观和客观的测试指标均好于 SOTA 。
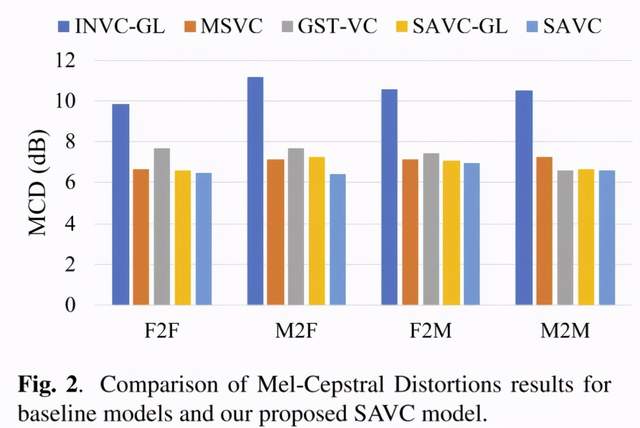
文章图片
文章中提出的 SAVC 模型和基线模型的梅尔谱失真 (MCD) 结果如图 2 所示 。 从结果中可以很明显看出 , SAVC-GL 模型的梅尔谱失真比 INVC-GL 模型的低很多 。 此外 , SAVC 模型的梅尔谱失真结果优于 SAVC-GL 模型的结果 , 说明后端声码器的改进可以进一步提高性能 。 与 MSVC 模型和 GST-VC 模型的失真结果相比 , SAVC 模型表现更优秀 , 而且 SAVC 模型的结果在同性别之间和跨性别语音转换的结果没有明显的差距 。 这些都证明了 SAVC-GL 模型的有效性 。
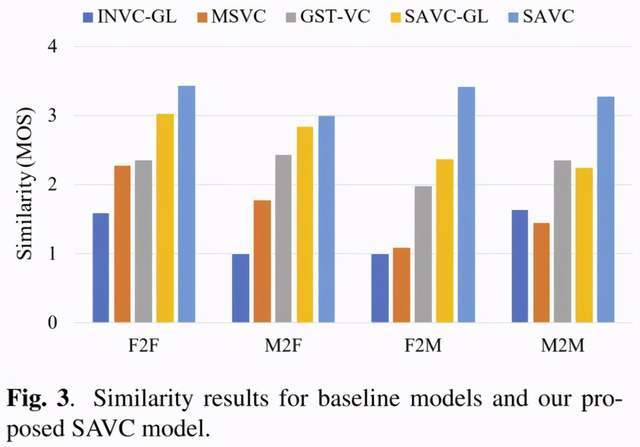
文章图片
图 3 的结果表明 , 相比于基线模型 , SAVC 模型在所有转换对中均获得了最佳的相似度评分 。 值得注意的是 , GST-VC 的男女转换得分低于其他转换对 。 这可能是因为 Aishell-1 的训练集中女性数据更多 , 性别不平衡导致 GST-VC 表征不同的目标说话人能力有区别 。 因为 GST-VC 中表征说话人信息的模块是完全基于无监督训练的 , 无法对这种现象进行人工干预 。 但是 , 在 SAVC 模型中未观察到此问题 , 因为作者在设计 SKB 时考虑到了性别均衡 , 有效的减少了训练集合中数据不均衡造成的干扰 。 结果符合作者对 SAVC 设计的期望 。
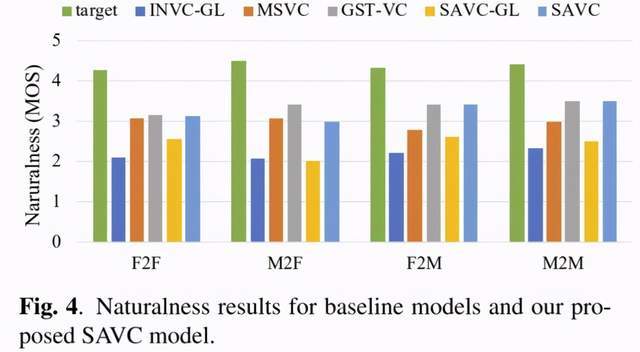
文章图片
基线模型和 SAVC 模型的自然度平均意见得分如图 4 所示 。 通过 Griffin Lim 算法重构的语音得分比 LPCNet 重构的语音得分差很多 。 这是因为 Aishell-1 语料库是语音识别数据集 , 由移动电话记录 。 音频中存在许多噪声 , 例如混响 , 信道噪声等 , 这些均不利于 Griffin Lim 算法从频谱参数中预测相位 , 导致合成语音质量变差 。 但是 , LPCNet 声码器在训练时对数据进行随机加噪处理 , 增强了数据的多样性 , 因而对带噪信号更鲁棒 。 尽管后端声码器都是 LPCNet , 但 MSVC 模型的自然度主观意见得分低于 GST-VC 模型和 SAM-VC 模型 。 因为说话人编码器中建模的说话人空间和 MSVC 模型是完全独立的 , MSVC 模型只对训练过程中遇到的说话人向量进行建模 。 在预测阶段 , 对于已经训练好的 MSVC 模型而言 , 新的目标说话人向量是是完全未知的信息 , 因而声学后验概率和新的说话人向量之间的可能存在不匹配 , 这导致了语音质量的下降 。 GST-VC 模型和 SAVC 模型之间自然度主观意见分数非常的接近 , 这也是很容易理解的 , 因为这两个模型中用到的说话人向量均是由语音转换模型预测的 , 并且它们都使用 LPCNet 重建波形 。
下面的视频展示了 SAVC 模型和基线模型基于单样本语音转换的效果 , 输入语音和目标说话人语音均来自集外说话人 。 视频中依次展示了男声变女声 , 女声变男声的效果 。 更多 demo 可以参见作者展示的链接 。 (
https://vcdemo-1.github.io/SAVC/savc.html)
应用
变声技术在快手有丰富的应用场景 , 比如短视频编辑 , 直播变声 , 个性化定制用户音色等 。 而通过单样本语音转换复制音色 , 不仅可以大大降低对训练数据库的要求 , 而且也可以显著节省计算资源 。 基于单样本的语音转换是快手在语音交互领域的一个重大技术突破 , 有望引领变声应用的新潮流 。
快手 MMU 介绍
快手MMU(Multimedia understanding)部门负责快手全站海量音视频、直播的内容理解 , 为公司提供500+智能服务 , 应用在搜索、推荐、生态分析、风险控制等诸多场景 , 团队拥有业内最顶尖的算法工程师和应用工程师 , 持续招募相关领域技术人才 。
推荐阅读







- 曾学忠|光弘科技 2000 万台小米智能手机下线,明年目标 4000 万台
- 曾学忠|小米手机部总裁曾学忠:希望明年与光弘科技完成智能手机4000万台目标 将引入高端和旗舰项目提升合作规模
- 能源|新思科技葛群:以科技重塑能源格局,助力双碳目标实现
- 车路|首份聚焦AI助力“双碳”目标报告发布:到2030年将推动交通减碳7000万吨
- 苹果|苹果目标达成,Apple Music中的9000万首歌曲已全部达到无损标准
- 识别率|一群年轻人教“AI”学手语,目标是让千万聋人被“听见”
- 产业|绿色和平强调,数字基础设施需加速转型以助力实现碳中和目标
- 具体目标|《“十四五”智能制造发展规划》发布
- 目标|12月28日:所有问题,最终的最终都是个人的问题
- Windows|Windows 11中让你更轻松的复制文件/文件夹路径