From: Google; 编译: T.R
由于疫情 , 今年的视频会议系统得到了更加广泛的应用 。 视频会议系统的核心在于会议 , 因此 , 做好隐私保护和无关信息的去除 , 有助于大幅度提高用户体验 。
利用机器学习技术和基于浏览器的高性能计算 , 谷歌研究人员实现了谷歌会议中的背景虚化、背景替换等功能 , 既突出了视频会议中的主体 , 又排除了主体周围不相关信息的干扰 。
当前 , 大多数视频会议软件都依托于额外的安装程序 , 而谷歌会议则仅仅基于浏览器端就能得到良好运行 。 有了MediaPipe套件和浏览器端的先进技术 , 即使是复杂的机器学习功能 , 也能在浏览器里流畅运行 。
谷歌这项基于浏览器的实时、高性能的视频会议技术 , 是为几乎所有现代智能电子设备开发的 , 它融合了高效的移动端机器学习技术、基于WebGL的渲染技术 , 以及集成到web端的XNNPACK和TFLite等推理框架 。

文章图片
基于MediaPipe套件在web中实现的背景虚化和背景替换
Web端机器学习
谷歌会议的新特性基于 MediaPipe开发, 这是一套为实时媒体数据流提供个性化机器学习解决方案的多平台框架 , 它同时也被用于移动端的实时人脸、手部、身体姿态检测等项目中 。
移动端设备软件的核心在于实现高性能运行 , MediaPipe中的Web Pipeline使用了WebAssemble技术框架来提升性能 。 WebAssembly是一套专为浏览器设计的底层二级制代码 , 可以大幅提升计算密集型任务的速度 。 在运行时 , 浏览器将WebAssembly指令转换为机器码 , 这会比传统的Java运算快很多 。 此外 , Chrome84也为WebAssembly引入了单指令多数据 , 从而进一步提升了两倍的性能 。
在会议视频的背景处理任务中 , 研究人员首先对每一视频帧进行前景分割 , 利用机器学习模型得到低分辨率的mask , 而后优化mask的精度 , 并使其与原图边缘对齐 。 最后 , mask被WebGL2用于渲染被替换或虚化后的视频背景 。 整套流程如下图所示:

文章图片
WebML流程图: 所有计算密集型任务都通过C++ (OpenGL) 实现 , 并通过WebAssemble在浏览器中执行 。
【压力|?仅用浏览器就能视频会议?更换、虚化背景毫无压力!】在目前的版本中 , 模型在CPUs运行 , 以便在低功耗情况下适应更多的设备类型 。 为了实现实时处理 , 研究人员利用XNNPACK加速了机器学习模型的推理速度 , XNNPACK库是为WebAssembly SIMD (单指令多数据) 设计的加速推理引擎 。 在XNNPACK和SIMD的加速下 , 浏览器中的分割模型可以达到实时的水平 。
前景背景分割模型
移动端的模型需要非常轻量级、低功耗的微小参数量模型 。 但对于在浏览器中运行的模型来说 , 输入图像的分辨率会极大地影响每一帧所需的浮点运算和运行时间 , 因此输入的图像尺寸要尽可能小 , 后续的处理才能快 。 这样一来 , 输入的图像首先会被压缩到较小的尺寸 , 而后送入模型进行处理 。
整体的分割模型是一个对称的编码器-解码器架构 , 其中每个模块都使用了逐通道的注意力模块和全局池化 , 使得CPU计算更友好 。
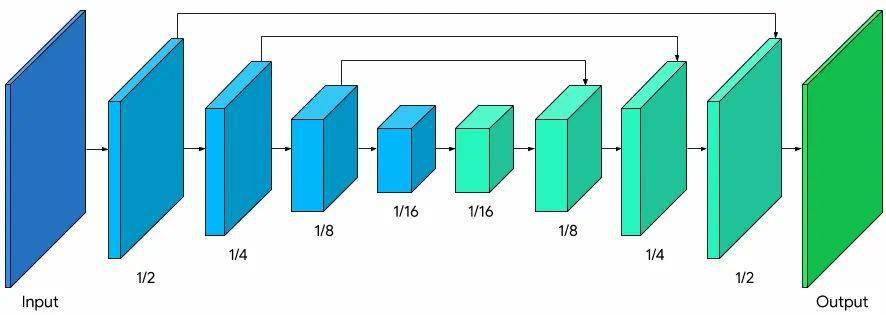
文章图片
基于MobileNetV3-small的对称的编码器-解码器架构
模型使用了MobileNetV3-small作为编码器架构 。 这种架构是使用NAS得到的低资源下高性能网络架构 , 同时还通过TFLite导出了Float16量化的模型 , 从而将模型继续缩小了一半 。 如此一来 , 在没有明显精度损失的情况下 , 用仅仅193K参数、400KB大小的模型来完成任务 。
最终输出渲染
当分割完成后 , 这项技术使用了OpenGL着色器对视频进行效果渲染 。 其中的难点在于:要保证在高速渲染的同时不引入人工痕迹 。 为了克服这项难点 , 研究人员在视频优化阶段还引入了双边滤波器来平滑低分辨的mask 。

文章图片
左图利用联合双边滤波器平滑了语义mask , 中图用可分离滤波器移除了光晕效应 , 右图在背景替换后将光照重新渲染于画面 。
模糊着色器通过语义分割mask的值来自适应地调节每个像素的背景虚化强度 , 与光学中的离焦模糊 (circle-of-confusion, CoC) 类似 。 像素使用CoC加权 , 可以避免前景、背景混杂在一起 。 这里使用了可分离滤波器实现了加权模糊 , 代替了较为通用的高斯金字塔 , 可以去除人物周围的光晕效应 。 模糊效果仅仅在低分辨上进行 , 而后与输入图像的前景在高分辨尺寸上进行融合 。

文章图片
背景虚化示例
针对背景替换 , 研究人员采用了包括LightWrapping在内的混合技术 , 将分割出的人物与个性化的背景进行融合 。 LightWrapping技术可以柔滑边缘 , 使融合结果更具沉浸感 , 同时在前景背景差别较大时减小光晕效应 。

文章图片
背景替换示例
性能测评
为了优化不同设备上的性能 , 研究人员提供了不同版本的模型输出尺寸 , 根据硬件的分辨率自动选择合适的大小 。 下表显示了在两种机器上端到端测评的性能:MacBook Pro 2018 (2.2 GHz 6核 Intel Core i7) , 和Acer Chromebook 11 (基于 Intel Celeron N3060)。 同样是针对720p输入 , MacBook Pro可以在较高质量的模型下实现120FPS , 端到端模型下实现70FPS;Chromebook可以在低分辨模型上实现62FPS , 在端到端模型则为33FPS 。 这样的结果都能满足日常需求了 。

文章图片
模型推理速度和端到端流程性能在高低端笔记本上的不同测评结果 。
针对模型质量的测评 , 研究人员采用了IOU和边缘F测量 , 两种超轻量级的分辨率模型都实现了较好的效果 。

文章图片
基于IOU和边缘F分数的模型测评精度
如果想要获得更多的细节和测评标准 , 可以参考研究人员发布的模型测评卡 , 其中包含了17个地区不同肤色和性别用户的测评结果 。
https://mediapipe.page.link/meet-mc
推荐阅读







- 安全|Redline Stealer恶意软件:窃取浏览器中存储的用户凭证
- Microsoft|微软丰富Edge浏览器功能 引入游戏面板
- Google|浏览器界的“千禧虫”:Google已着手测试Chrome 100解决方案
- 浏览器|新 iPhone 或移除 SIM 卡槽 / 扎克伯格被评为「年度恶人」 / Edge 浏览器支持 RSS 订阅
- Microsoft|微软Edge浏览器重启Followable标签:可关注网站动态
- 浏览器|经典功能回归,微软 Edge 浏览器将支持 RSS 订阅
- IT|圣诞全球逾3000航班取消“缺人”压力下纽约缩短隔离时间
- 浏览器|不替换ieframe.dll,两种强制打开Win11的IE11浏览器办法
- 网络应用|Vivaldi推出车载版浏览器 Polestar 2率先搭载
- 开始退役|Win10开始弹窗:IE正在退出,请切换到Edge浏览器