作者:孙培泽
本文介绍一下我们最近的工作:OneNet: Towards End-to-End One-Stage Object Detection 。 现有的one-stage detectors的label assign , 都只用到了位置信息 (location) , 如box IoU (e.g.,YOLO, RetinaNet), point distance (e.g.,FCOS, CenterNet) 。 但是目标检测是分类 (classification) 和定位 (location) 的联合任务 , 只考虑位置信息的label assign和网络的优化目标存在着非常大的misalignment , 导致冗余的高分检测框 , 从而需要NMS后处理 。
本文提出了 OneNet , 首次实现了 end-to-end dense detector without NMS 。OneNet的样本匹配策略是Minimum Cost Assign: cost定义为样本与gt的分类距离 (classification cost) 和位置距离 (location cost) 之和; 正样本是所有样本中和gt的cost最小的样本 , 其他都是负样本 。 我们发现 , classification cost是去除NMS的关键;没有classification cost会导致冗余的高分检测框 , 从而需要NMS后处理 。 OneNet在标准的COCO benchmark上达到了37.7 AP / 50 FPS , 35.0 AP / 80 FPS 。

文章图片
https://arxiv.org/abs/2012.05780
代码链接:
https://github.com/PeizeSun/OneNet
一、简 介
现有的end-to-end的目标检测模型都是two-stage或者multiple-stage (如: DETR , Deformable DETR , Sparse R-CNN) 。 这些模型的检测性能很好 , 但是由于各种复杂layer的存在而不容易部署 , 但one-stage在工业应用中有着更大的潜力 。 我们提出了OneNet: end-to-end one-stage object detector 。
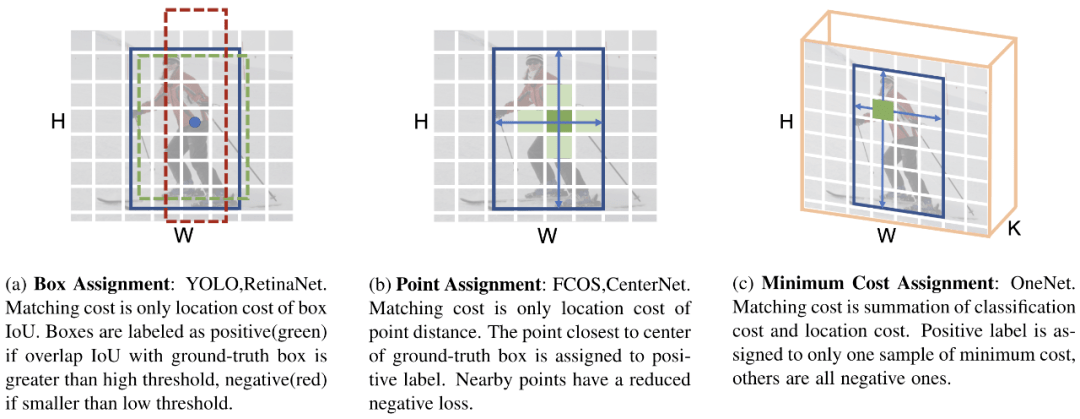
文章图片
图1 不同的样本匹配策略
OneNet的优势是:
- 整个网络是全卷积的 , 没有各种非常规的layer (比如GN , RoI-Align , Dynamic Conv) 。
- 无需Non-Maximum Suppression (NMS) 后处理或者self-attention模块 。
- 样本匹配策略是简单的Minimum Cost , 无需启发式规则或者复杂的最优二分匹配 。
我们发现 , classification cost是实现end-to-end的关键 。 而回顾之前的dense detector样本匹配策略 , 都是只有 location cost , 如box IoU (e.g.,YOLO, RetinaNet) , point distance (e.g.,FCOS, CenterNet) 。 只有location cost的样本匹配策略会导致冗余的高分检测框 (图4) , 从而需要NMS后处理去除这些冗余框 。
二、OneNet
输入图片 (H×W×3) , backbone产生feature map (H/4×W/4×C) , head预测分类 (H/4×W/4×K) 和回归 (H/4×W/4×4) , 最后的输出直接取top-k高分框 。
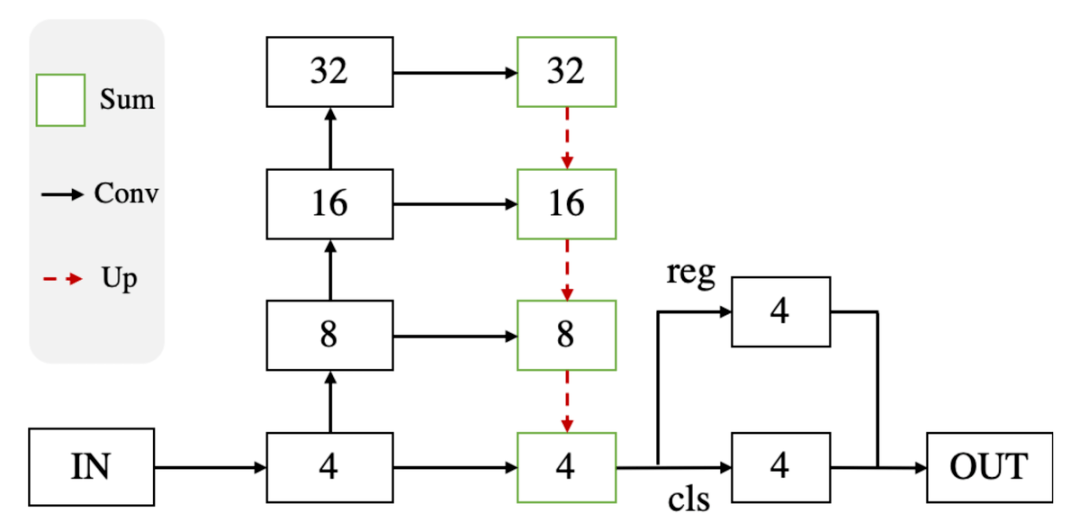
文章图片
图2 OneNet pipeline
Backbone: Backbone是先bottom-up再top-down的结构 。 其中 , bottom-up结构是resnet , top-down结构是FPN 。 我们实现了两种FPN , 一种是上采样中引入deformable conv , 为了追求较高检测精度;一种是普通conv , 方便工业部署 。
Head: Head是两个并行的conv , 分类conv预测类别 , 回归conv预测到物体框的4个边界的距离 。
Output: 直接取top-k高分框 , 没有NMS , 也没有类似CenterNet中max-pooling的操作 。
样本匹配策略:OneNet的样本匹配策略是一种基于minimum cost的异常简单的方法 , 没有启发式规则 , 也没有最优二分匹配 。 cost定义为样本与gt的classification cost和location cost之和 , 具体定义是:
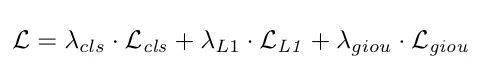
文章图片
其中 , 是分类focal loss , 和是预测框和gt框归一化后的l1 loss和giou loss 。 λ是系数 。
对每个gt , 正样本是和gt的cost最小的样本 , 其他都是负样本 。 伪代码如下:
# C is cost matrix, shape of (nr_sample, nr_gt)
C =cost_class +cost_l1 +cost_giou
# Minimum cost, src_ind is index of positive sample
_, src_ind =torch .min(C, dim =0)
tgt_ind =torch .arange(nr_gt)
三、实 验
图3给出了只考虑location cost和综合考虑location cost+classification cost的正样本 。 只考虑location cost时 , 正样本是离物体框中心最近的样本点 。 这样的正样本有利于定位 , 但是对分类并不友好 , 如:第一个case的人体姿态导致正样本点落在人体边缘 , 这并不是较优的选择 。
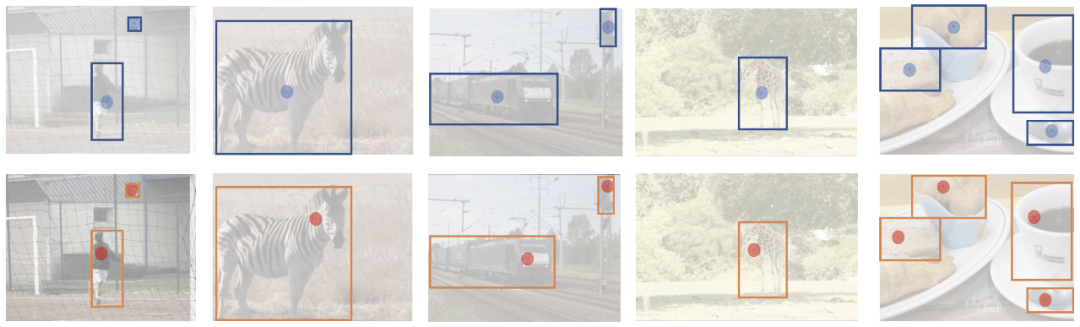
文章图片
图3 only location cost (1st row) 和 location cost + classification cost (2nd row) 的正样本 。 实际正样本是一个点 , 图中被高亮圈突出 , 以便更好的可视化 。
综合考虑location cost+classification cost的正样本 , 一般落在物体的更具辨别性的区域 , 如:人体内部 , 斑马头部 。 这样的正样本有利于分类 , 同时对定位也较为友好(毕竟正样本点依然在物体框内部) 。
表1中的4个实验都是one-to-one的样本匹配策略 。 其中第一个实验的location cost是指feature map中point的位置到物体gt center的位置的距离 (可以理解为CenterNet只有高斯极值点为1 , 其他都是0) 。
从表1可以看出 , classification cost是去掉NMS的关键 。 而回想绝大多数的样本匹配策略 , 如 , box IoU、point distance , 都是只考虑了location cost 。 第三个实验如此拉胯的原因可能是因为predicted box是变化的 , 会导致正负样本来回横跳 , 训练低效 。

文章图片
表1 Effect of label assignment
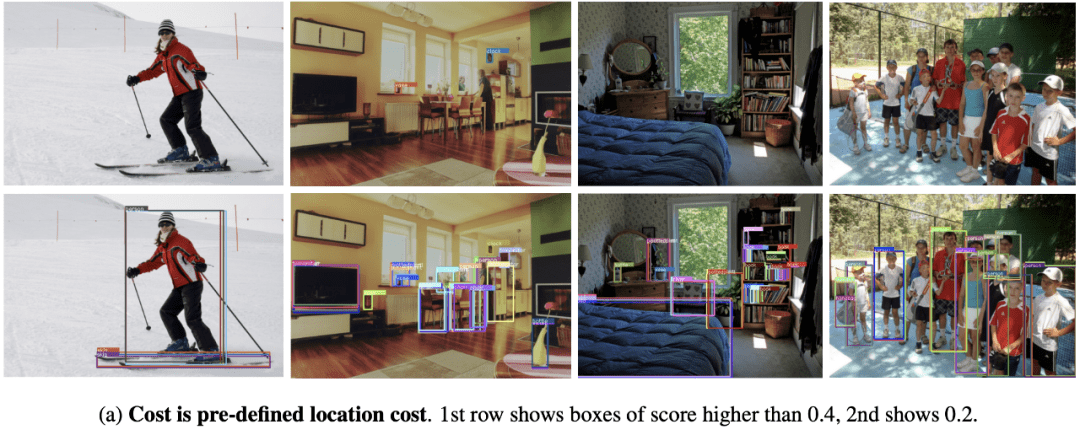
图4给出了表1中的4个实验的可视化图 , 可以看到 , 没有classification cost的模型会预测出冗余的高分检测框 , 需要NMS后处理来去除这些冗余框 。 而引入classification cost的模型消除了冗余框 。
文章图片

文章图片

文章图片

文章图片
图4 表1中的4个对比实验的可视化图
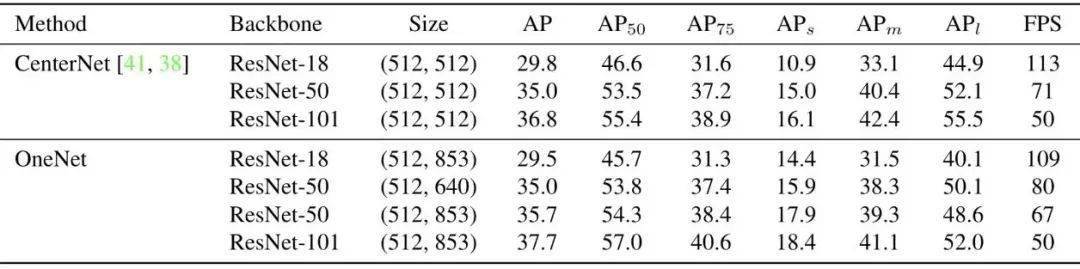
表2 给出了OneNet和CenterNet的比较 。 OneNet在检测精度和推理速度都展现出comparable的性能 。 这证明OneNet有效去除了NMS , 成功实现了end-to-end 。
文章图片
表2 OneNet和CenterNet的比较
四、讨 论
一年前 , 在anchor-free和label assignment的那波研究中 , 我们曾经考虑过one-to-one的样本匹配策略 , 表1第一行的实验也做过了 , 性能也是只有AP 20+(加上NMS 30+) 。 当时我们总结的原因是:某一位置如果分类是1 , 那么这一位置的周围位置很难突变成0 。
最近DETR出现了 , 在样本匹配中同时考虑location cost和classification cost , 成功做出了end-to-end two-stage (multiple-stage) 。 这给人启发end-to-end one-stage是不是也需要引入classification cost 。 表1第一行的实验简单地加上classification cost (即表1第二行实验) 竟然神奇地work了!甚至optimal bipartite matching也不需要 , 直接全图找最小cost的样本就行 。 可能optimal bipartite matching也可以做 , 但是在dense detector中太慢了 。
我们也进一步验证了classification cost是否对sparse detectors的end-to-end也至关重要 。 从表3可以看出 , classification cost也是sparse detectors实现end-to-end的关键 。

文章图片
表3 Effect of label assignment on sparse detectors
我们的工作提出了很多较为本质的问题: 为什么引入classification cost能够使得相邻的feature map points的分类发生突变?样本之间的交互 (例如max-pooling, self-attention) 对于e2e是否必须?这些问题都值得后续深入研究 。
五、彩 蛋
【阶段|港大提出OneNet: 一阶段端到端的目标检测网络】设计OneNet的初衷是推广end-to-end detectors的工业应用 。 我们会在接下来的时间实现OneNet的部署代码 , 加入git repo中 , 欢迎大家届时关注和使用 。
推荐阅读







- Siamese|一个框架统一Siamese自监督学习,清华、商汤提出简洁、有效梯度形式,
- IT|世卫组织:2022年或将成为新冠疫情危急阶段的终结
- 警告!|冒充老干妈员工诈骗腾讯被判12年 两被告提出上诉
- the|美国日增新冠确诊病例超44万 专家:美疫情已转向新阶段
- 最新消息|张庭公司涉嫌传销被查?市监部门:涉案金额大,已进审计阶段
- 防范|申报阶段就造假,如何防范学术不端前移?
- 登月|日本提出2025年后“搭美国便车”登月
- IT|贾跃亭造车进入最终阶段 FF 91量产版焊装生产线设备已在路上
- 电子商务|苏宁董事长张近东:债务问题已取得阶段性企稳
- 频段|我学者提出拍赫兹通信新框架 助力未来6G发展