Siamese|一个框架统一Siamese自监督学习,清华、商汤提出简洁、有效梯度形式,
机器之心专栏
清华大学、商汤科技
来自清华大学、商汤科技等机构的研究者们提出一种简洁而有效的梯度形式——UniGrad , 不需要复杂的 memory bank 或者 predictor 网络设计 , 也能给出 SOTA 的性能表现 。当下 , 自监督学习在无需人工标注的情况下展示出强大的视觉特征提取能力 , 在多个下游视觉任务上都取得了超过监督学习的性能 , 这种学习范式也因此被人们广泛关注 。
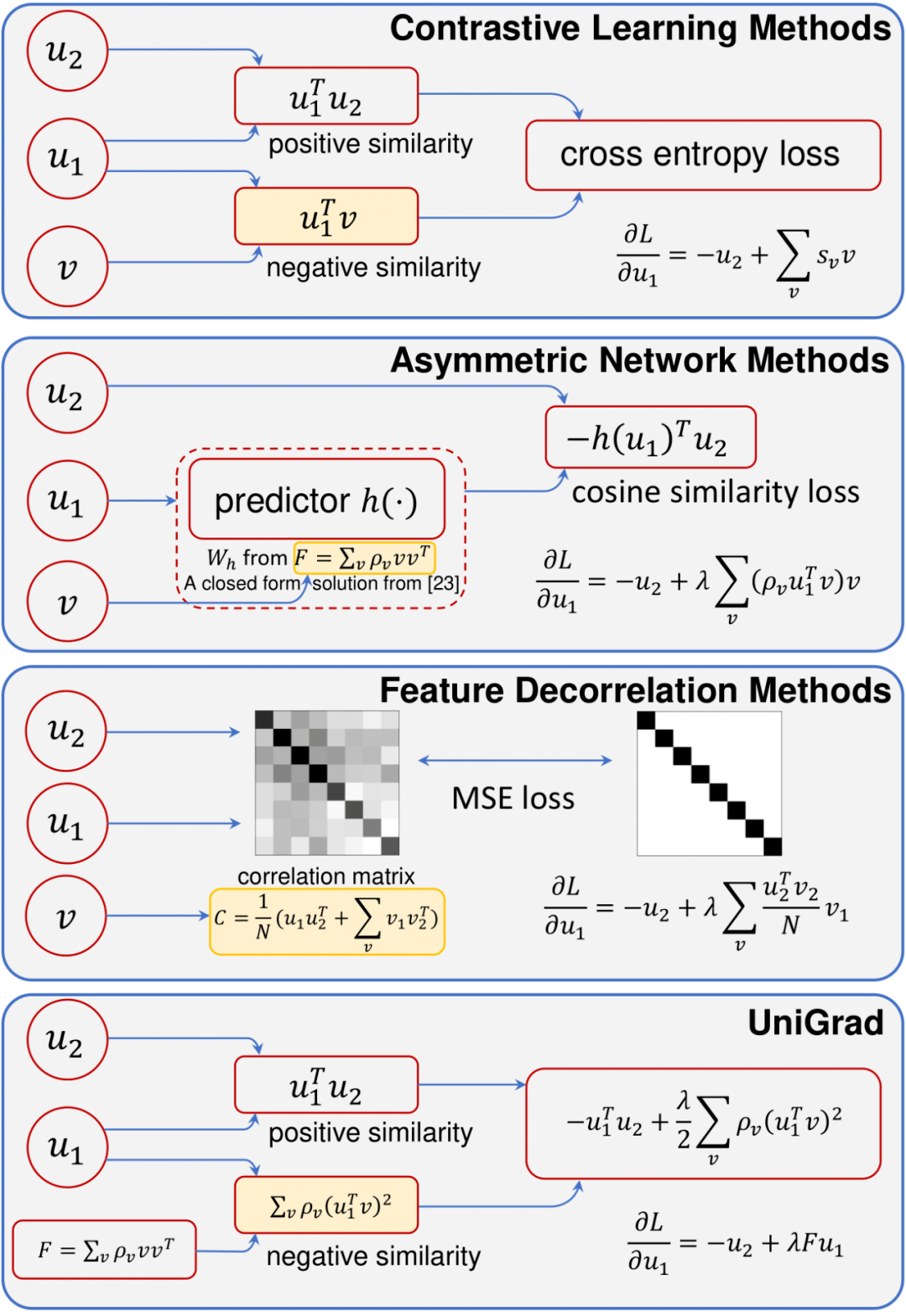
在这股热潮中 , 各式各样的自监督学习方法不断涌现 , 虽然它们大多都采取了孪生网络的架构 , 但是解决问题的角度却差异巨大 , 这些方法大致可以分为三类:以 MoCo、SimCLR 为代表的对比学习方法 , 以 BYOL、SimSiam 为代表的非对称网络方法 , 和以 Barlow Twins、VICReg 为代表的特征解耦方法 。 这些方法在对待如何学习特征表示这个问题上思路迥异 , 同时由于实际实现时采用了不同的网络结构和训练设置 , 研究者们也无法公平地对比它们的性能 。
因此 , 人们自然会产生一些问题:这些方法之间是否存在一些联系?它们背后的工作机理又有什么关系?更进一步的 , 具体是什么因素会导致不同方法之间的性能差异?
为此 , 来自清华大学、商汤科技等机构的研究者们提出一个统一的框架来解释这些方法 。 相较于直接去比较它们的损失函数 , 他们从梯度分析的角度出发 , 发现这些方法都具有非常相似的梯度结构 , 这个梯度由三部分组成:正梯度、负梯度和一个平衡系数 。 其中 , 正负梯度的作用和对比学习中的正负样本非常相似 , 这表明之前提到的三类方法的工作机理其实大同小异 。 更进一步 , 由于梯度的具体形式存在差异 , 研究者通过详细的对比实验分析了它们带来的影响 。 结果表明 , 梯度的具体形式对性能的影响非常小 , 而关键因素在于 momentum encoder 的使用 。

文章图片
论文链接:https://arxiv.org/pdf/2112.05141.pdf
在这个统一框架的基础上 , 研究者们提出了一种简洁而有效的梯度形式——UniGrad 。 UniGrad 不需要复杂的 memory bank 或者 predictor 网络设计 , 也能给出 SOTA 的性能表现 。 在多个下游任务中 , UniGrad 都取得了不错的迁移性能 , 而且可以非常简单地加入其它增强技巧来进一步提升性能 。
文章图片
图 1 三类自监督方法与 UniGrad 的对比
统一框架
本节将分析不同方法的梯度形式 , 首先给出三类方法各自的梯度形式 , 然后归纳其中的共性结构 。 从梯度的角度读者也可以更好地理解不同类型的方法是如何工作的 。 为了方便表述 , 作者用u表示当前样本特征 ,v表示其它样本特征 , 添加下标,
推荐阅读







- 市场资讯|“真·网红”马斯克:一个特斯拉哨子30万,大红内裤遭秒光
- 市场|刘作虎:一加达成了一个小目标
- 创事记|NFT距离元宇宙只差一个周杰伦
- 创事记|从主播开始谈一个购物需求
- 网络|白荣芳:荣耀为始 芳华绽放
- 教育|学科停船后的第一个寒假,“脑机接口”能否成为科技素质教育的后起之秀?
- 财年|小米、苹果怕不怕?索尼也要造车,还带来了一个大消息
- 新闻|一个人的生活品质,可以通过平时收藏的公众号显现出来
- 创事记|大厂难以沉下去的乡镇夫妻店,诞生了一个IPO
- IT|达拉斯希望成为福特下一个自动驾驶汽车工厂的所在地