【编前语】
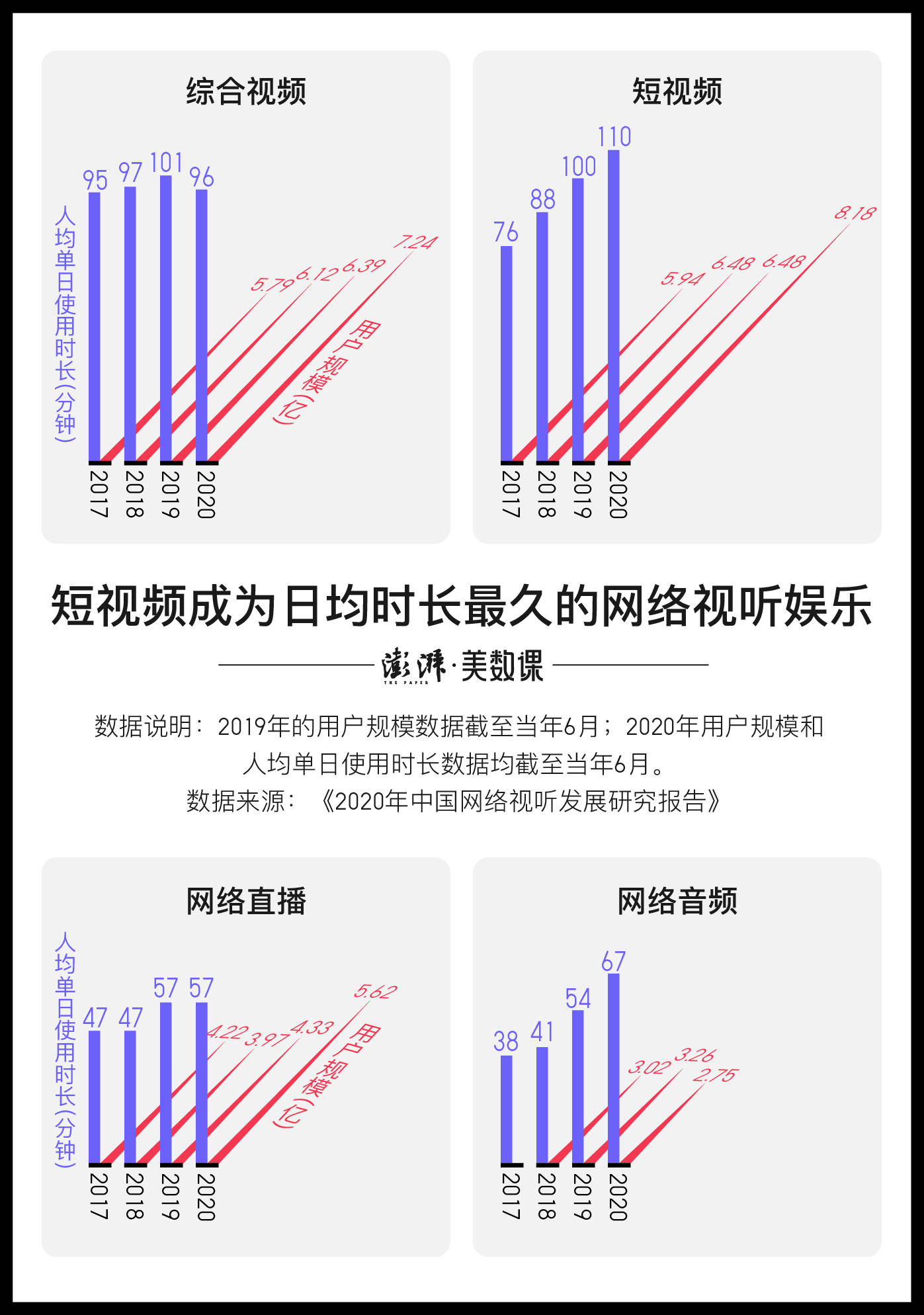
据今年人民网发布的《2020中国网络视听发展研究报告》统计 , 截至6月份 , 我国短视频用户规模达到8.18亿 , 人均单日时间达110分钟 , 近两成用户每天看短视频2小时以上 。 短视频产业的繁荣成为了新的资本焦点 , 但也不免让人产生新的忧虑 。 今年上映的纪录片《社交困境》就指出了类似的问题 , 随着推荐算法的不断强大 , 作为受众的我们越来越难放下眼前的手机 , 不断地重复着相同的滑动动作 , 眨眼间消耗掉大把的时间 。
澎湃新闻和互联网资深软件工程师Justin聊了聊 , 请他为我们普及一下推荐算法背后的机制 。 Justin认为 , 推荐算法的初衷是为了提高人们的阅读效率 , 但互联网公司为了能更多地吸引用户 , 把推荐算法变成了一种工具 , 解决了算力的同时 , 也加强了社交产品中原先就容易让人上瘾的特质 。 可惜的是 , 目前从社会层面上 , 这个问题很难得到抑制 。 作为用户的我们 , 要有意识地去观察自己的使用行为 , 不能让自己的时间被无意义地吞噬 。

文章图片
“人类在沉迷 , 机器在学习 。 ”来源:Instagram @ml.india
澎湃新闻:在没有推荐算法前 , 网站是怎么推荐内容的?
Justin:在以前 , 传统的做法是根据规则过滤内容 , 比如说根据热度推荐 , 某个视频在本站的热度很高 , 那我就给你推荐;如果不高 , 就不推荐 。 或者说 , 如果你曾经点赞过很多生活区的视频 , 那就给你推荐生活区的视频 , 其他的我就不管了 。 这些都是很单一的明确的判断标准 。
澎湃新闻:那推荐算法又是一个什么样的机制呢?
Justin:简单而言 , 推荐算法就是把一堆用人话讲出来的目标 , 转化成机器能够理解并运算的数字 。 在大数据统计的基础上 , 这个算法会提取用户和内容这两者的特征 , 经过一系列复杂的转换和计算后 , 给用户匹配到合适的内容 。
举个例子 , 我们把用户的年龄、性别、注册时间、历史点赞行为等数据特征化 , 作为模型的输入 。 这些数据的维度通常非常多 , 但如果我们简化为一个二维空间 , 就是一个个平面上的点 。 推荐算法就是要用一根不规则的曲线去不断地拟合这些点 , 去寻找最佳匹配 , 慢慢地也就成为了一个复杂的算法 。
澎湃新闻:你之前在播客《枫言枫语》中提到过 , 因为推荐算法的操作太简单了 , 所以算法工程师反而不太好控制 , 甚至会嘲笑自己是调参工程师 。 这个观点会不会和上面提到的推荐算法的复杂性产生冲突?
Justin:这可能是我之前在节目里表达得不够准确 。简单是指的应用层面 , 而复杂则是设计层面 。 也不是说应用层面的算法工程师能力不强 ,毕竟计算机科学工业已经发展了这么多年 , 肯定会出现许多精细化的领域分工 , 大家都是各有所长的 。
澎湃新闻:那“调参工程师”这个说法又是怎么来的呢?
Justin:对于应用的工程师来说 , 他们主要是把这个算法现有的模型拿到线上使用 , 也就是一个输入加一个输出 。 虽然没有我描述得这么简单 , 但总的来说 , 你可以理解为这个算法的中间是一个黑盒 , 就是一个fx函数 , 假设它里面是x加x的话 , 你输入一 , 就会得到二 , 对吧?也就是说 , 无论输入是怎样的 , 输出是肯定不会变的 。
而且因为中间这个部分是黑盒 , 你根本不知道它是怎么运作的 , 甚至连设计算法的那个人 , 他可能也不好拍板 , 说这里输入一个什么东西后 , 一定会得到一个什么效果 , 所以我才说这个算法不是特别好控制 。 就好比 , 大脑的最小组成单位是一个神经元 , 神经元会释放很多不同的神经递质 , 然后产生一些化学反应 。你能理解神经元是怎么运作的 , 你就能完全明白我们的意识是怎么产生的吗?不可以 , 这是两个不同的维度 。 尤其当推荐算法正式上线的时候 , 它将面对一个装有几亿甚至几十亿用户的庞大沙盘 , 最后这个群体会变成什么样子 , 我们是不可预知的 。
澎湃新闻:所以推荐算法工程师每天就是在控制参数吗?他们的工作内容是怎样的 , 可以举个例子吗?
Justin:举个例子 , 如果我们的目标很明确是要让某一类型内容(feed)的点赞率上升 , 那我们可以先捞一拨用户出来 , 作为实验组 , 然后再捞一批用户作为对照组 , 通过很科学的方式验证这个算法实验的操作是否正确 。
之后 , 我再对这些用户和内容特征做一个不同权重的设计 , 把这些特征输入我们的模型后 , 就可以通过调参得到不同的目标:比如推一个内容(feed) , 就是为了让你点赞 , 或者就是为了让你评论等等 。
实验之后 , 我发现之前调的那些东西是对的 , 那就说明我做对了 。 但至于我是怎么做对的 , 我也只是猜测 , 我不确定我写了这些东西之后 , 它到底能不能得到这样的结果 , 甚至可能会发生这样的小概率事件:我的实验结果是对的 , 但在全网铺开后 , 这个算法模型反而起到了反效果 。 这是因为推荐算法真正难的地方在于 , 很多时候你的目标是不可量化的 , 而我们只能通过其他多个可量化的指标去逼近这个不可量化的指标 。
文章图片
【内容|算法祛魅②|放不下手机的我们,也被困在了算法里】澎湃新闻:你之前还提到了一个观点:推荐算法的弊端在于 , 它没法保证推送给我喜欢内容的同时 , 还让我学到新东西 。 为什么出现这个问题呢?
Justin:这其实是机器解决人类问题所面对的一个非常大的难点 。机器的目标通常是非常明确的 , 而我们想学到的东西 , 常常是不可量化的 。
学习新知识 , 需要的是发散思维 , 需要不断地拓宽认知领域 , 但纯靠机器推荐的话 , 它的趋势肯定是收敛的 。 比如我在ins上点赞了一些美女和赛博朋克风格的照片 , 那它一定会继续给我推荐这两种照片 。 如果机器想帮助我拓宽认知边界 , 那它一定得想办法在里面塞更多的东西 , 而且不能是美女或赛博朋克 。 换言之 , 它只能猜测 。
因此 , 现在抖音、快手等内容平台会加入很多机器推荐之外的策略 。 比如通过和你背景相似的群体的喜好 , 去试探你喜欢的内容 , 如果你点击了喜欢 , 那你的历史数据就会被慢慢改变了 。 还有人工干预 , 比如新出了一个综艺 , 热度不够的话 , 机器肯定是无法预知的 , 就需要人工把这个内容推向全网 。
文章图片
澎湃新闻:那可以说 , 推荐算法是导致人们不断沉迷手机的罪魁祸首吗?
Justin:不一定 。 手机成瘾本身的根源并不在于推荐算法 ,推荐算法仅仅是一种新型的技术手段 , 它极大地解决了算力问题 , 助长了原先就存在于社交产品中的那些特质 。 毕竟 , 每天起床去健身房的人是少数 , 每天坚持阅读的人也是少数, 绝大多数人可能更喜欢被投喂信息的方式 。
在推荐算法没出来前 , 人们也需要花很多时间去阅读内容 。 大概在2010年前后 , 推特已经有上亿用户 , 每名用户关注的人数也超过了百位 , 如果一百个人每天发三条推特 , 按照传统的时间排序 , 用户如果想看到高质量的内容 , 就只能往上翻 , 翻完这300条推特 , 这个阅读效率是很低的 。 推荐算法的出现 , 能帮助读者快速地完成阅读 , 以免被淹没在90%的无意义聒噪中 。
我始终认为技术本身是中立的 , 它产生的时候就是单纯地为了解决一个技术难题 , 而不是为了让一些公司做A/B测试 。 至于它解决了难题后 , 未来会变成什么样 , 这并不是技术在发展的过程中它所会去考虑的 。
文章图片
(本文来自澎湃新闻 , 更多原创资讯请下载“澎湃新闻”APP)
推荐阅读







- 设备|雷军亲自演示 MIUI 13“小米妙享中心”:一拖流转媒体内容
- 问答|紧追B站加码知识类内容,抖音上线“学习频道”
- 词条|百度百科上线2500万词条,超750万用户参与共创科普知识内容
- 运营|Yiwealth面向百家金融机构免费提供百万元智能内容产品及服务,打造财富管理行业智慧运营新基建
- 字节跳动|抖音上线学习频道,为知识内容增加一级入口
- the|流媒体大战白热化:明年美8大媒体集团内容开支将达1150亿美元
- 人物|车顶维权女车主曝光庭审内容:特斯拉拿不出任何实锤证据
- 媒体播放器|内容付费来了 消息称抖音正测试短视频“赞赏”功能
- 安全|好购App未经许可读取用户手机剪贴板内容 法院认定侵害隐私权
- 体育|抖音发布体育内容报告 网友关注“健身、自律、锻炼”