随着人工智能从感知智能向认知智能发展 , 语言理解和知识挖掘研究不断深入 , 事实和常识知识愈发重要 。 智能问答、对话、推理、推荐等应用均需要丰富的知识作为基础支撑 , 而命名实体识别作为文本中重要的知识获取手段 , 已成为一项重要研究课题 。
【阶段性|思必驰在中文命名实体识别任务中取得阶段性进展】命名实体识别(Named Entity Recognition , NER)任务的目标是识别出文本中预定义类别的实体 。 作为NLP领域的重要基础工具 , 其有效推动了NLP技术从实验阶段走向实用化 。
近期 , 思必驰语言与知识团队对中文细粒度命名实体识别任务进行探索 , 并取得阶段性进展:在CLUE数据集Fine-Grain NER评测任务[1]中 , 思必驰语言与知识团队目前暂列第一 。 该评测数据集基于清华大学开源的文本分类数据集THUCTC[2] , 选出部分进行细粒度命名实体标注 。 原数据来源于Sina News RSS[3] 。 这项测评是中文自然语言处理领域的大规模赛事 , 有众多知名企业同台竞技 。
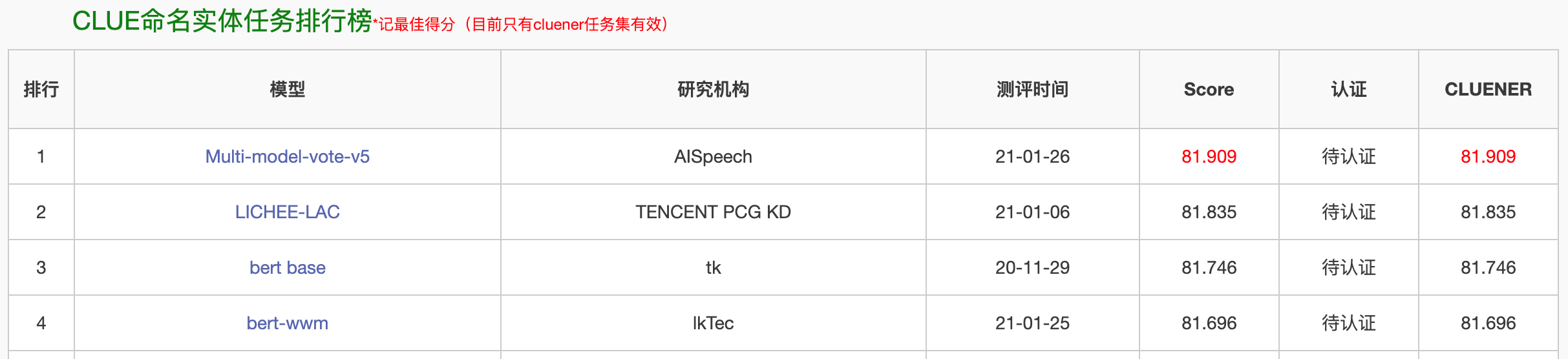
文章图片
中文命名实体评测中的出色表现也证明了思必驰在知识挖掘方向的实力 。 该技术也将应用到智慧医疗综合应用中 , 包括从大量医疗文献、病历文本和医患对话数据中构建医疗知识图谱 , 并基于知识图谱辅助语义理解和知识推理 , 实现医疗知识问答和医疗辅助决策 。 如智能导诊、智能预问诊、智能诊后随访 。
语言智能常被称为人工智能皇冠上的一颗明珠 。 在未来 , 思必驰语言与知识团队将继续深耕语言理解领域 , 打造出精准、通用且能够实现自定义的命名实体识别系统 , 推动命名实体识别在NLP各领域的落地和应用 。
推荐阅读

- IT|风阻系数不到0.20 史上“最节能”奔驰1月4日发布
- 最新消息|被网友怒批后 奔驰官微悄然下架“眯眯眼”广告
- 硬件|换装奔驰S级同款斜面中控屏 全新GLC内饰谍照曝光
- IT|知情人士:恒驰汽车量产下线仪式可能要到明年初
- IT|中保研最新汽车零整比数据:31万的奔驰C拆零件能卖260万
- 视点·观察|三只松鼠刚下热搜 奔驰新广告模特“眯眯眼”又引争议
- 电子商务|苏宁董事长张近东:债务问题已取得阶段性企稳
- 代理商|思必驰会议魔方M1加速落地政企,助推办公效率开启新速度
- IT|大干三个月 恒大首款汽车恒驰5终下线:曾被工信部除名
- 影驰|影驰 RTX 3060 mini 显卡上市:16.8cm 长,售价 4299 元