学术界 Benchmark 结果
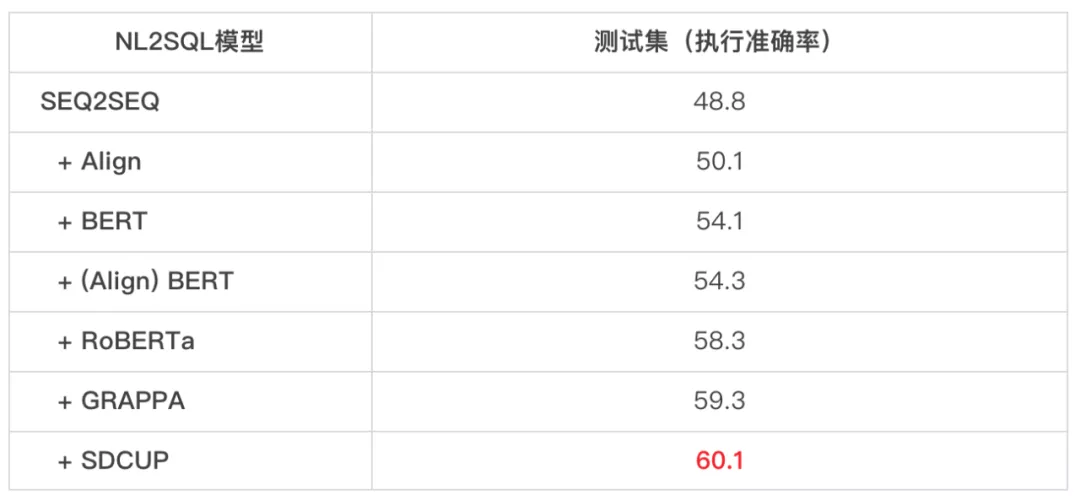
在耶鲁大学的 WikiSQL 数据集和微软构建的 SQuALL 数据集上 , SDCUP 模型也取得了 SOTA 的效果 , 并且相比学术界已有的表格预训练模型有较显著提升 。

文章图片
SDCUP 在耶鲁大学 WikiSQL 数据集上取得业界最优效果
文章图片
SDCUP 在微软 SQuALL 数据集上取得业界最优效果 。
中文数据集结果
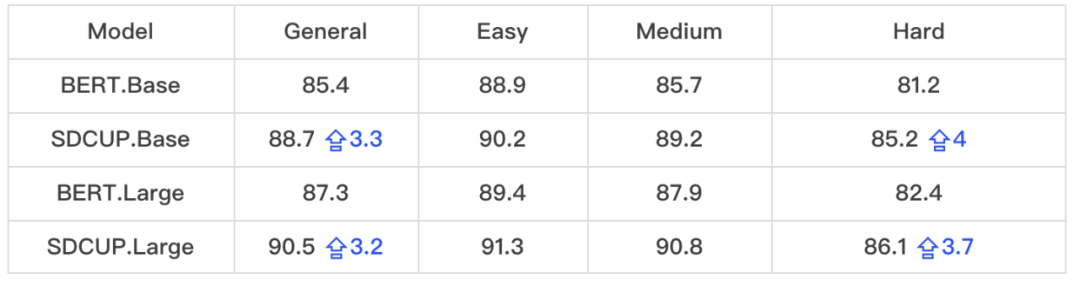
在 TaBLUE 数据集上 , SDCUP 的 base 和 large 模型相比同参数规模的 BERT 模型分别提升 3.3 和 2.9 个百分点 , 并且随着数据难度的增大提升幅度也逐渐增大 , 体现出 SDCUP 模型对于复杂 NL2SQL 数据具有更好的建模能力 。
文章图片
总结
本文详细介绍了中文首个表格预训练模型——SDCUP 背后的数据构建和模型训练等技术细节 , 以及相关表格问答技术的产品化和业务落地情况 。 如何建模自然语言和结构数据之间的语义关联是自然语言处理领域备受关注的课题 , 本文所提出的 Schema Dependency 系列方法可以视为该领域下新的探索方向 。
除了在中英文 NL2SQL 任务中取得 SOTA 效果之外 , 团队也在探索如下方向:
- 超大规模预训练表格理解模型;
- 超大规模预训练表格生成模型;
- 端到端开箱即用的问答系统 。
[1] Yu T, Zhang R, Polozov A, et al. SCoRe: Pre-Training for Context Representation in Conversational Semantic Parsing[C]//International Conference on Learning Representations. 2020.
[2] Hui B, Geng R, Ren Q, et al. Dynamic Hybrid Relation Exploration Network for Cross-Domain Context-Dependent Semantic Parsing[C]//Proceedings of the AAAI Conference on Artificial Intelligence. 2021, 35(14): 13116-13124.
[3] Shi P, Ng P, Wang Z, et al. Learning Contextual Representations for Semantic Parsing with Generation-Augmented Pre-Training[C]//Proceedings of the AAAI Conference on Artificial Intelligence. 2021, 35(15): 13806-13814.
推荐阅读






- 研究院|传统行业搭上数字化快车,施工现场变“智造工厂”
- 机器|戴森达人学院 | 戴森HP09空气净化暖风扇测评报告
- 美容|升级扩业 中家医·家庭医生医疗美容医院引爆广州
- 问答|紧追B站加码知识类内容,抖音上线“学习频道”
- 文化|【“用数赋智”系列宣讲】苏州工艺美术职业技术学院探索传统工艺的跨界创新
- IT|南非研究显示两剂强生新冠疫苗可大幅降低Omicron导致的住院
- 团队|深信院41项科研项目亮相高交会 11个项目获优秀产品奖
- 索尼|索尼推出两款无线低音炮、环绕音箱,适配家庭影院
- 生命科学学院|科技馆内感受科技魅力
- 互联网|首儿所互联网医院办公区启用 为患者提供就医便利