机器之心专栏
作者:耿瑞莹、惠彬原等
达摩院Conversational AI团队
12 月 2 日 , 达摩院深度语言模型体系 AliceMind 发布中文社区首个表格预训练模型 SDCUP , 该模型在全球权威表格数据集 WikiSQL 和 SQuALL 上取得了业界最优效果 , 相关模型和训练代码已经开源于阿里巴巴深度语言模型体系 AliceMind 中 。

文章图片
此外 , 在达摩院构建的表格问答中文数据集 TaBLUE 上 , SDCUP 比同参数规模 BERT 模型效果提升约 3 个百分点 。 达摩院资深算法专家李永彬介绍 , SDCUP 模型是达摩院表格对话技术系列研发的一部分 , 后续将持续对外开源 。
目前 , 预训练表格模型 SDCUP 和相关 NL2SQL 技术已经应用在了阿里云智能客服(云小蜜)的 TableQA 产品中 。 并且 , 为满足不同场景下的训练和交付需求 , 表格管理、数据配置、模型训练和效果干预等功能已全部完成产品化 , 基本做到知识梳理低成本、问答构建高速度、模型训练无标注 , 满足各个场景的交付运维需求 。
接下来看 SDCUP 模型的技术详解 。
表格问答技术
由于数据结构清晰、易于维护 , 表格 / SQL 数据库是各行各业应用最普遍的结构化数据 , 也是智能对话系统和搜索引擎等的重要答案来源 。 传统表格查询需要专业技术人员撰写查询语句(如 SQL 语句)来完成 , 因门槛高 , 阻碍了表格查询的大规模应用 。 表格问答技术通过将自然语言直接转换为 SQL 查询 , 允许用户使用自然语言与表格数据库直接交互 , 具有很高的应用价值 。
什么是表格问答(TableQA)呢?我们通过一个例子来引入 , 如下图班级学生信息的 Table , 用户可能会问:“告诉我 3 班最高的男生有多高?” 要想解决这个问题 , 需要先把自然语言转换成一个 SQL 语句 , 然后用 SQL 语句去查询表格 。 所以整个 TableQA 的核心问题就是解析自然语言:把 TEXT 文本转变为 SQL 语句(NL2SQL) 。
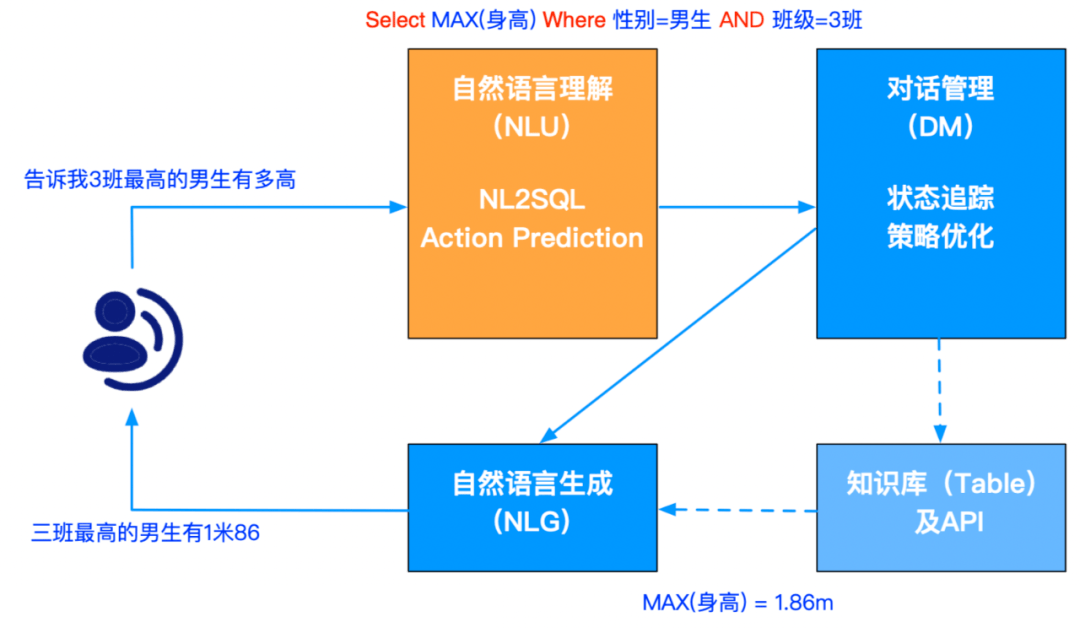
文章图片
由于表格内容复杂多样 , 涉及各行各业的专业知识 , 样本标注难度大 , 模型迁移能力差 , 这项任务一直是自然语言处理领域的难题 。
表格预训练模型国内外工作
近年来预训练语言模型(BERT、GPT、T5)迅速发展 , 促进了 NLP 领域各种任务上的进步 , 例如阅读理解、命名实体识别等任务 。 但目前的预训练模型基本上在通用文本上进行训练 , 在一些需要对结构化表格数据进行建模的任务上(如 Text-to-SQL 和 Table-to-Text) , 需要同时对结构化数据进行表示 , 如直接采用现有 BERT 等模型 , 就面临着编码文本与预训练文本形式不一致的问题 。
推荐阅读







- 研究院|传统行业搭上数字化快车,施工现场变“智造工厂”
- 机器|戴森达人学院 | 戴森HP09空气净化暖风扇测评报告
- 美容|升级扩业 中家医·家庭医生医疗美容医院引爆广州
- 问答|紧追B站加码知识类内容,抖音上线“学习频道”
- 文化|【“用数赋智”系列宣讲】苏州工艺美术职业技术学院探索传统工艺的跨界创新
- IT|南非研究显示两剂强生新冠疫苗可大幅降低Omicron导致的住院
- 团队|深信院41项科研项目亮相高交会 11个项目获优秀产品奖
- 索尼|索尼推出两款无线低音炮、环绕音箱,适配家庭影院
- 生命科学学院|科技馆内感受科技魅力
- 互联网|首儿所互联网医院办公区启用 为患者提供就医便利