
文章图片
相比主流 GPU 产品 , MLU370-X4 的性能优势 。
从功耗与加速卡配置来看 , 寒武纪推出的加速卡对标的正是 AI 算力的标杆英伟达:思元 370-X4 加速卡在 70-75W 功率上性能大幅领先于 T4 , 在 150W 功率上又实现了与最新一代安培架构、基于 GA102 核心的 A10 持平或小幅领先 , 功耗效率则高出 2 倍还多 。
这意味着在推理任务上 , 同等尺寸的思元 370 加速卡可以 2 倍性价比替代 T4 , 相比 A10 甚至 A30 也可以节省超过 1/4 的总拥有成本(TCO) 。
在英伟达该级别芯片生产接近停滞的当前 , 寒武纪的芯片显得极具竞争力 。
文章图片
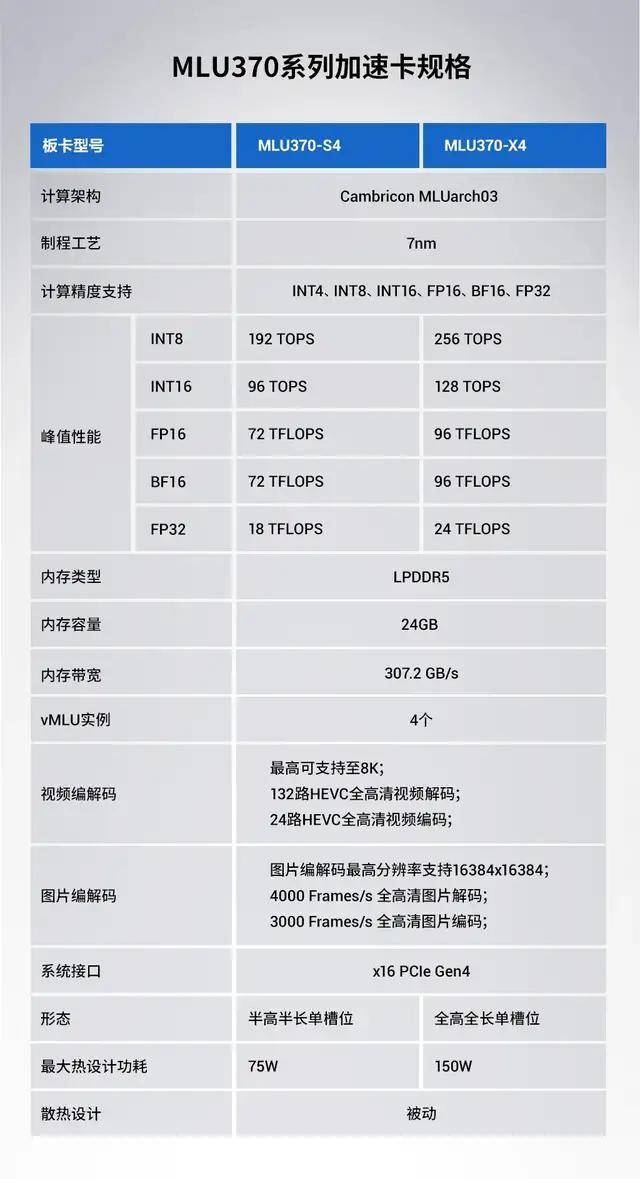
MLU370-S4、MLU370-X4 两种加速卡的规格 。
为什么在计算机视觉和自然语言处理任务中 , 寒武纪能够做到超越同级数据中心的 GPU?在性能的背后 , 是寒武纪全方位的技术革新 。
「chiplet」技术 , 未来芯片的发展方向
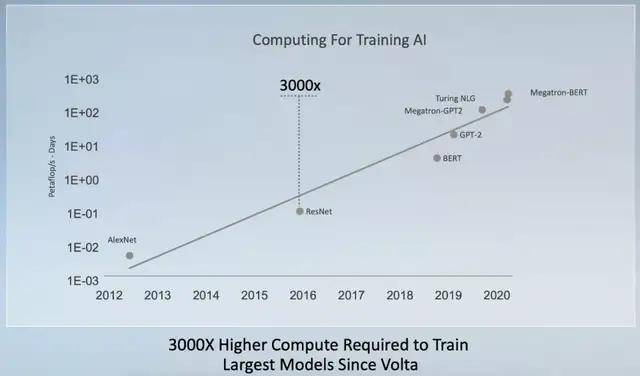
根据英伟达的统计 , 自 2012 年到现在的大规模深度学习模型参数量呈现指数增长 。 相比之下 , 即使通过增加功耗等方法 , AI 芯片的算力还是只能延续每两年翻倍的速度 。
为了提供更高的运算效能 , 人们寻找的方法包括增加处理器核心数量 , 提升缓存容量及 I/O 数量等等 。 这些情况使得 IC 设计者即便使用最先进制程 , 也很难把芯片尺寸变得更小 。
文章图片
自 2017 年底英伟达发布 Tesla V100 之后 , 训练最大模型的算力需求增长了 3000 倍 。
从英伟达 T4 到 A10 的迭代我们可以看出 , 制程从 12nm 进步到 8nm , 功耗翻倍 , 性能提升则是 2.2-2.5 倍 。 另一方面 , 先进制程、低良品率造成的成本问题也让芯片厂商不堪重负 , 使用 chiplet 的方式打造新一代芯片或许是未来的重要发展方向 。
思元 370 是寒武纪首次采用 chiplet 技术打造的芯片 , 在一颗芯片中封装 2 颗 AI 计算芯粒(被称为 MLU-Die) , 每个 MLU-Die 具备独立的 AI 计算单元、内存、IO 以及 MLU-Fabric 控制和接口 , 相互之间通过 MLU-Fabric 保证两个 MLU-Die 间的高速通讯 。
此前 , AMD 在 CPU 上就通过使用 7 纳米制程和 chiplet 构建芯片的方式实现了对于英特尔的「逆袭」 。 最近一段时间 , 英特尔也提出即将使用 chiplet 构建芯片的计划 。 在一块芯片上置入多个 die 虽然可以提高晶圆的利用效率 , 但会面临很多技术方面的问题 , 芯粒间的信息传递速度是其中最大的挑战 。
尤其在深度学习的推理和训练任务中 , 模型和数据在芯片内部是强并行的 , 所以芯粒间信息传递速度的问题还会更加凸显 。 对此 , 寒武纪称 MLU-Fabric 能够以低功耗、低延时、超高带宽的技术来解决传递速度的问题 , 帮助用户实现应用无感知的体验 , 单从这点来看 , 寒武纪 MLU-Fabric 芯粒间的互联技术已经超越了 AMD 的处理器 。
推荐阅读







- 技术|“2”类医械有重大进展:神经介入产品井喷、基因测序弯道超车
- Samsung|三星预告1月11日发布Exynos 2200芯片组 RDNA 2 GPU加持
- 手机|一加10 Pro宣传视频曝光:将于1月11日14点发布
- 选型|数据架构选型必读:2021上半年数据库产品技术解析
- 技术|使用云原生应用和开源技术的创新攻略
- 语境|B站2021个人年度报告发布:你共计看了多少个视频
- 功能|Linux 微信官方版 2.1.1 正式发布
- 技术|聚光科技旗下临床质谱仪获批医疗器械注册证
- Apple|苹果高管解读AirPods 3代技术细节 暗示蓝牙带宽可能成为瓶颈
- 硬件|闪极140W多口充电器发布:首发399元 支持PD3.1