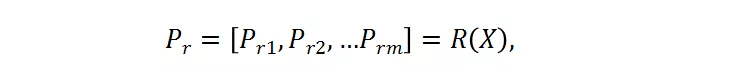
文章图片
其中 , X 是输入的样本 , 被送入分辨率预测器 。 P_r 是预测器的输出 , 其代表了每个候选的概率 。 候选分辨率中对应的最高概率的那个分辨率将被选为送入大分类器的图片的分辨率 。 这里采用了 Gumbel-Softmax 来实现这种选择过程 , 将其转变成是可微分的:
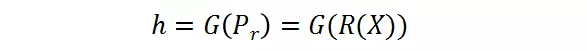
文章图片
分辨率感知的批正则化(BN)
BN 常用于使得深度模型收敛得更快更稳定 。 然而不同分辨率下的激活统计值 (activation statistics) 包含了均值和方差 , 这使得它们不兼容 。 实验表明 , 使用不同的分辨率下的共享的 BN 会导致更低的准确率 。 考虑到 BN 层只包含了可忽略不计的参数 , 研究者提出分辨率感知的批正则化 , 即对于不同的分辨率 , 使用他们对应的 BN 层 。
训练优化
分类网络与分辨率预测器同时进行训练优化 。 损失函数包含了交叉熵损失函数和研究者提出的 FLOPs 损失函数 。 FLOPs 损失函数用于限制计算量 。
给定一个预训练好的分类网络
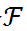
文章图片
。 输入 X 并输出概率
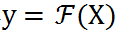
文章图片
以用于图像分类 。 对于输入 X , 研究者首先将其 resize 成 m 个候选分辨率 X_r1, X_r2,... , X_rm , 然后使用分辨率预测器对每张图片产生分辨率概率矢量 P_rR^m 。 然后软分辨率概率 P_r 被转变成硬的独热选择 h ?{0,1}^m , 使用 Gumbel-Softmax 。 h 代表了每个样本的分辨率选择 。 在实践中 , 他们首先获得了对于每个分辨率的最终的预测 y_rj=F(X_rj) , 然后将其通过 h 加起来:
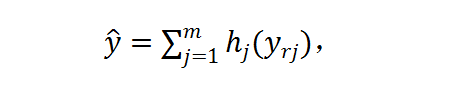
文章图片
交叉熵损失函数
文章图片
将在预测 ^y 和标签 y 之间执行:
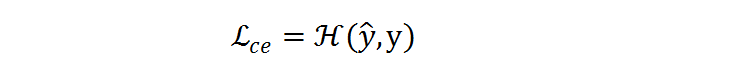
文章图片
梯度被反向传播到分类网络和分辨率预测器以同时优化 。
如果只使用交叉熵损失函数 , 分辨率预测器将会收敛到一个次优点 , 并倾向于选择最大的分辨率 , 因为最大的分辨率往往对应着更低的分类损失 。 为了减少计算量 , 研究者提出了一个 FLOPs constraint regularization 去指导分类预测器的学习:
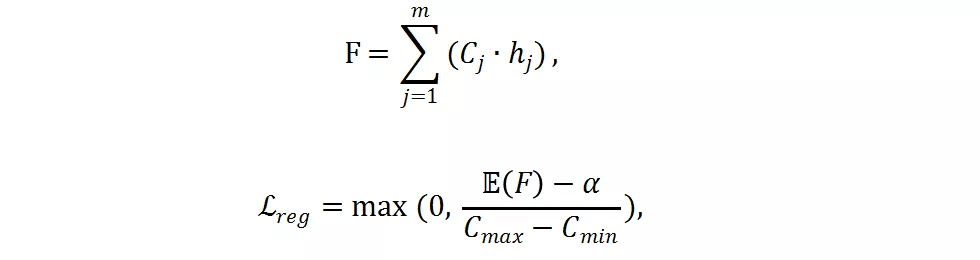
文章图片
推荐阅读



- 年轻人|人生缺少的不是运气,而是少了这些高质量订阅号
- 网络|天津联通全力助推天津市入选全国首批千兆城市
- 网络化|工信部:2025年建成500个以上智能制造示范工厂
- 视点·观察|张庭夫妇公司被查 该怎样精准鉴别网络传销?
- 数字化|70%规模以上制造业企业到2025年将实现数字化、网络化
- 人物|俄罗斯网络博主为吸引流量 闹市炸毁汽车 结果够“刑”
- 协同|网文论︱网络文学与AI写作:人机协同演化时代的文学之灵
- 周鸿祎|网络安全行业应提升数字安全认知
- 安全风险|网络安全行业应提升数字安全认知
- 海康威视|智能家居战场又添一员,海康威视分拆萤石网络上市,半年营收20亿 | IPO见闻