为什么一个产品的上线可以如此之快?傅徐军解释说 , 「闪记是钉钉和阿里巴巴达摩院合作开发的新产品 , 我们看到的多国语言翻译以及语音转文字能力都是来源于达摩院强大的技术支持 。 」
以闪记用到的语音识别为例 。 我们刚才提到 , 钉钉闪记的语音转文字结果是「立即」可出的 , 这区别于一些需要等待的语音转写产品 。 后者利用的往往是离线系统 , 在准确率方面比较有优势 , 但缺点也很明显 , 就是延迟较高 。 因此 , 近年来 , 延迟较低的在线系统受到越来越多的关注 , 但准确率始终不及离线系统 。 为了综合二者的优势 , 在降低延迟的同时提高准确率 , 阿里达摩院与钉钉技术团队采用了新一代流式和离线端到端一体化模型方案(UNIVERSAL ASR) , 它可以同时支持闪记的实时转写和录制音频转写 , 识别率媲美纯离线端到端模型 , 但延迟大大降低 。
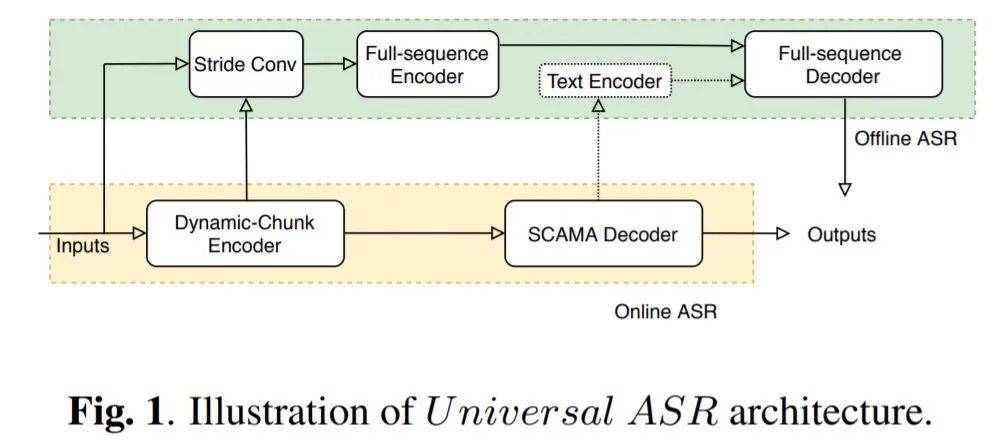
文章图片
UNIVERSAL ASR 架构概览 。 图源:https://arxiv.org/pdf/2010.14099.pdf
此外 , 闪记还首次上线了新一代端到端热词定制技术 , 在端到端模型中加入了为额外文本进行建模的 Contextual LSTM 模块 , 使得模型具备了对特定文本进行纠偏增强的能力 。 与传统热词技术相比 , 该技术的热词丢失率下降了 60% , 显著提升了定制场景的热词识别效果 , 且可设置热词数达到上千个 。
再比如说声纹识别 , 技术人员针对会议场景的多角色分离任务 , 提出了多项核心算法创新技术 。
首先 , 他们将只基于频域信息的传统声纹模型扩展到了频域和时空信息的三维说话人识别模型 。 通过有效建模空间信号信息 + 声纹神经网络 , 系统在多人会议中的性能大幅度提升 , 尤其是对说话人的起始时间的追踪、定位等能力 。
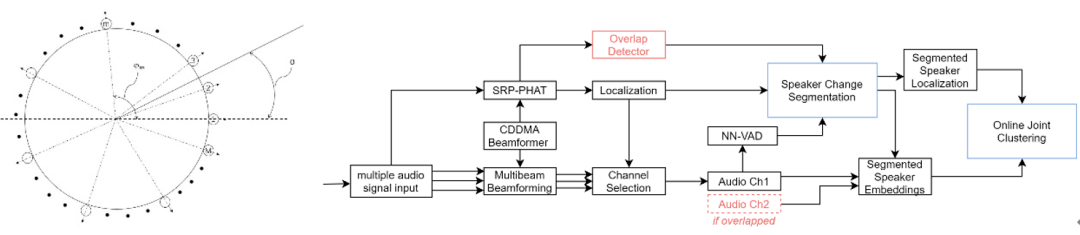
文章图片
图源:https://arxiv.org/pdf/2107.09321.pdf
其次 , 针对长期困扰说话人识别研究者的短时文本无关任务 , 研究人员也做出了显著的优化 。 他们提出了一种基于 contrastive loss 的孪生网络结构 Phonetically-aware Coupled Network (PacNet) , 有效地同时建模声学信息和内容信息 , 可以有效减少短语音时文本内容对声纹识别带来的干扰 , 从而大幅度提升一场会议中短片段识别的准确率 。
第三 , 针对强噪环境(如多人同时说话、电脑音频背景噪声等)下的说话人识别技术 , 技术人员提出了一种新的算法——CAM(针对声纹识别的 Context-Aware Masking) 。 该算法受到照相机聚焦技术的启发 , 可以在嘈杂的环境中「虚化」过滤掉背景噪声 , 突出需要识别的目标说话人的声音 , 从而在强噪环境下大幅度提升了识别的准确率 。
推荐阅读





- 用户|扫地机器人行业未来怎么走?石头科技给出了答案
- 模型|2022前展望大模型的未来,周志华、唐杰、杨红霞这些大咖怎么看?
- 智慧|过马路需取道地铁站怎么办?深圳开发过街码,进出闸机不扣费
- 新机|2021年末骁龙8系新机频发,想要一款性能体验好的旗舰该怎么选?
- http|抖音原来还能刷自定义评论!我知道网红怎么来的啦
- 诺克比|爱德华·威尔逊写小说:把“蚂蚁社会”作为人类的一个隐喻
- 韦贝尔|爱德华·威尔逊写小说:把“蚂蚁社会”作为人类的一个隐喻
- 合成氨|氢能源产业成为吕梁市转型发展的一把利刃
- 电子商务|美参议员直言比特币解决不了不平等:仍然被富人把持
- 市场|2022年,抖音到底该怎么涨粉?