平台|StarRocks VS ClickHouse,携程大住宿智能数据平台的应用( 四 )
·明细模型:表中存在主键重复的数据行 , 和摄入数据行一一对应 , 用户可以召回所摄入的全部历史数据 。
·聚合模型:表中不存在主键重复的数据行 , 摄入的主键重复的数据行合并为一行 , 这些数据行的指标列通过聚合函数合并 , 用户可以召回所摄入的全部历史数据的累积结果 , 但无法召回全部历史数据 。
·更新模型:聚合模型的特殊情形 , 主键满足唯一性约束 , 最近摄入的数据行 , 替换掉其他主键重复的数据行 。 相当于在聚合模型中 , 为数据表的指标列指定的聚合函数为REPLACE , REPLACE函数返回一组数据中的最新数据 。
·StarRocks系统提供了5种不同的导入方式 , 以支持不同的数据源(如HDFS、Kafka、本地文件等) , 或者按不同的方式(异步或同步)导入数据 。
·Broker Load:Broker Load通过Broker进程访问并读取外部数据源 , 然后采用MySQL协议向StarRocks创建导入作业 。 适用于源数据在Broker进程可访问的存储系统(如HDFS)中 。
·Spark Load:Spark Load通过Spark资源实现对导入数据的预处理 , 提高StarRocks大数据量的导入性能并且节省StarRocks集群的计算资源 。
·Stream Load:Stream Load是一种同步执行的导入方式 , 通过HTTP协议发送请求将本地文件或数据流导入到StarRocks中 , 并等待系统返回导入的结果状态 , 从而判断导入是否成功 。
·Routine Load:Routine Load提供了一种自动从指定数据源进行数据导入的功能 。 用户通过MySQL协议提交例行导入作业 , 生成一个常驻线程 , 不间断的从数据源(如Kafka)中读取数据并导入到StarRocks中 。
·Insert Into:类似MySQL中的Insert语句 , 可以通过INSERT INTO tbl SELEC...或INSERT INTO tbl VALUES(...)等语句插入数据 。
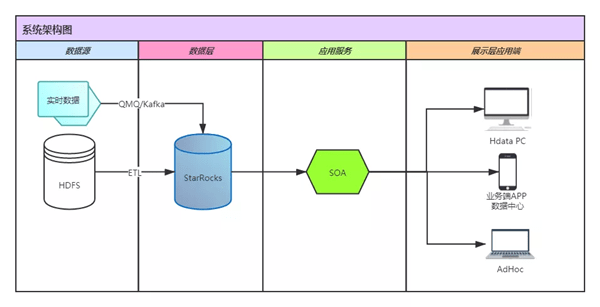
·HData中的数据主要分为实时数据和离线T+1数据 。
实时数据主要通过Routine load的方式导入 , 以使用更新模型为主
离线T+1数据主要使用Zeus平台 , 通过Stream load的方式导入 , 以使用明细模型为主
文章图片
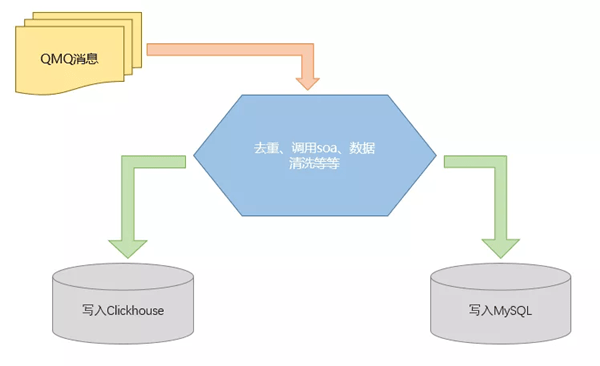
实时数据通过携程自研的消息队列系统QMQ实现 , 下图是原先的实时数据导入流程:
文章图片
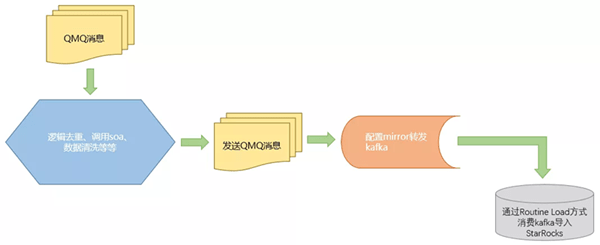
接入StarRocks后的实时数据导入流程:
文章图片
很快我们就遇到了一个难题:有一个场景是订阅订单状态变化的消息 , 下游我们以订单号作为主键 , 使用更新模型来将数据落地 。 对外我们提供订单状态为非取消的数据进行展示 。
在收到消息后 , 我们还需要调用外部接口来补全一些其他字段 , 最后再把数据落地 。 但如果收到一条消息就调用一次接口 , 这么做会对接口造成压力 , 所以我们采取了批处理的方式 。
推荐阅读







- IT|95306铁路货运电子商务平台升级上线 可24小时办理货运业务
- Intel|英特尔放出i9-12900K平台PCIe 5.0 SSD演示 突破13GB/s传输速率
- Intel|Intel在Alder Lake平台演示PM1743 PCIe Gen 5 SSD,带宽达14GB/s
- 科技创新平台|云南:打造世界一流食用菌科技创新平台
- 硬件|Intel 11代酷睿4核15瓦超迷你平台 仅有信用卡大小
- 平台|[原]蚂蚁集团SOFAStack:新一代分布式云PaaS平台,打造企业上云新体验
- 协作|微软发布了个“圈”,官方详解Microsoft Loop全新协作平台
- 审判|直接服务“三城一区”主平台,怀柔科学城知识产权巡回审判庭成立
- 相关|科大讯飞:虚拟人交互平台1.0在媒体等行业已形成标准产品和应用
- 平台|数梦工场助力北京市中小企业公共服务平台用数据驱动业务创新