大小|patch成为了ALL You Need?挑战ViT、MLP-Mixer的简单模型来了( 三 )
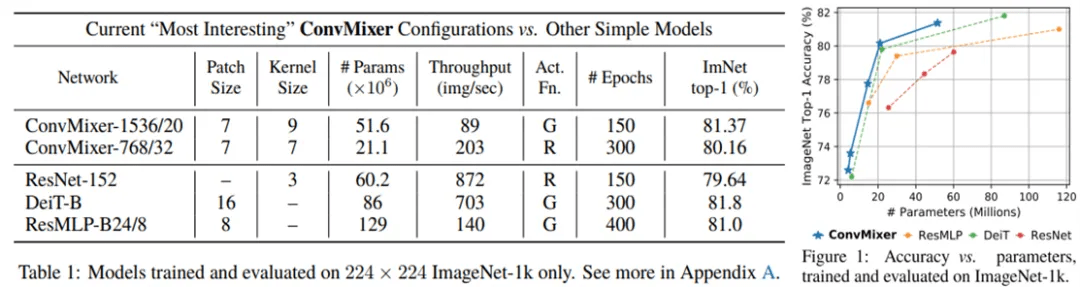
结果如下表 1 所示 。 参数量为 52M 的 ConvMixer-1536/20 在 ImageNet 上实现了 81.4% 的 top-1 准确率 , 参数量为 21M 的 ConvMixer-768/32 实现了 80.2% 的 top-1 准确率 。 更宽的 ConvMixers 在训练 epoch 更少时出现收敛 , 但需要内存和计算 。 当卷积核更大时表现也很好:当卷积核大小从 K = 9 降至 K = 3 时 , ConvMixer-1536/20 的准确率大约降了 1% 。 当 patch 更小时 , ConvMixers 的表现明显更好 。 因此 , 研究者认为 , 更大的 patch 需要更深的 ConvMixers 。 他们使用 ReLU 训练了一个模型 , 以证明 GELU 是不必要的 。
ConvMixers 模型和训练设置与 DeiT 非常相似 。 在最近的各向同性模型中 , 研究者认为 DeiT 和 ResMLP 是最公平的竞品模型 , 并且使用相同的过程训练了 ResNet(它的原始结果已经过时了) 。 从表 1 和下图 1 可以看到 , ConvMixer 在给定的参数预算下实现了具有竞争力的结果:ConvMixer-1536/20 在使用明显更少参数的情况下 , 优于 ResNet-152 和 ResMLP-B24 , 并能够与 DeiT-B 竞争 。 不仅如此 , ConvMixer-768/32 仅使用 ResNet-152 的 1/3 参数 , 就实现了与之相似的准确率 。
文章图片
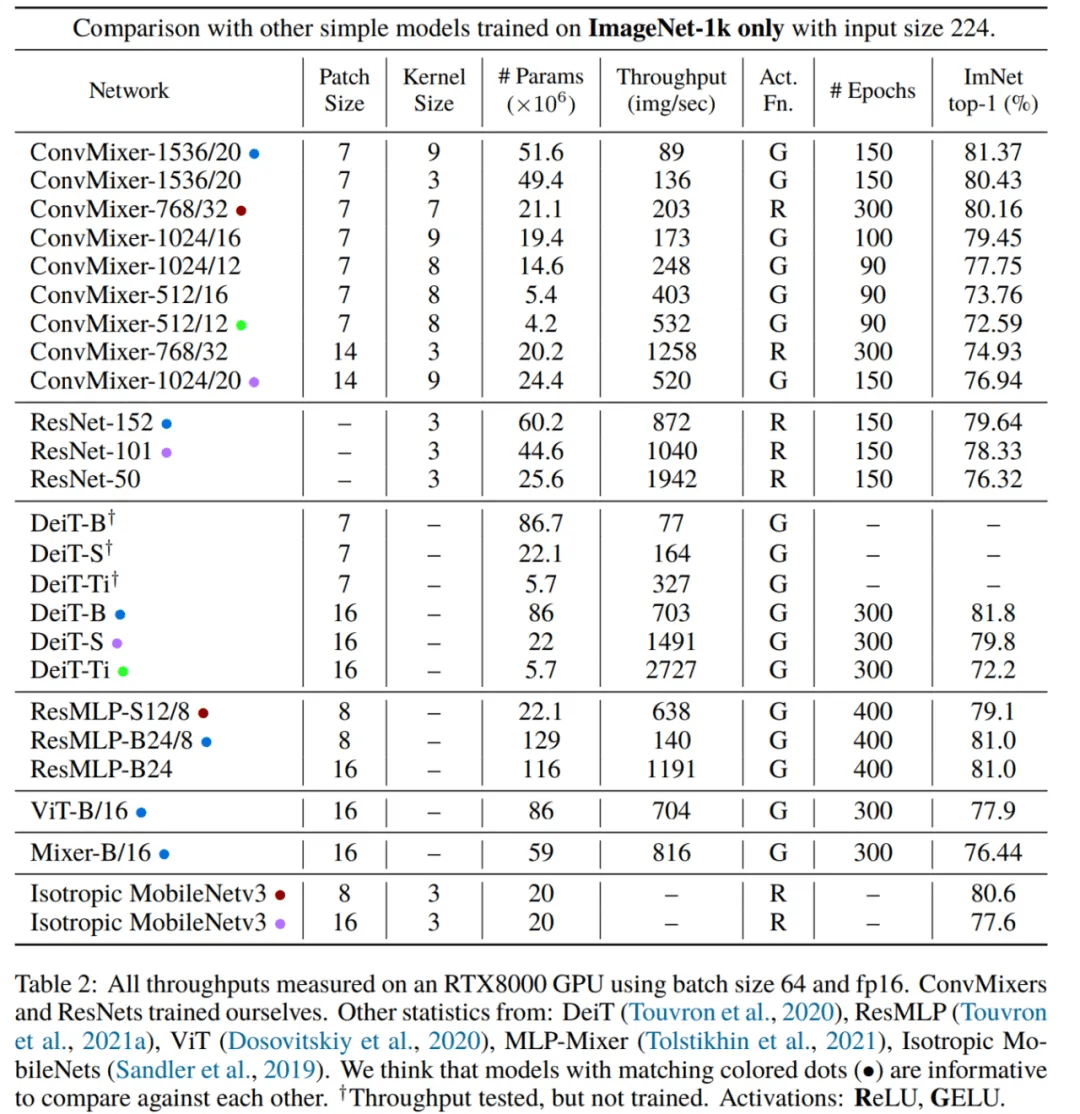
但是 , ConvMixers 的推理速度较竞品模型慢得多 , 这可能因为它们的 patch 更小 。 超参数调整和优化可以缩小这一差距 , 具体参见下表 2:
文章图片
推荐阅读







- 快报|“他,是能成就导师的学生”
- 地面|全程回顾神舟十三号航天员乘组圆满完成第二次出舱任务
- 最新消息|中围石油回应被看成中国石油:手续合法 我们看不错
- 人物|马斯克谈特斯拉人形机器人:有性格 明年底或完成原型
- 测试|图森未来完成全球首次无人驾驶重卡在公开道路的全无人化测试
- AMD|AMD 350亿美元收购赛灵思交易完成时间推迟 预计明年一季度完成
- 网络化|工信部:2025年建成500个以上智能制造示范工厂
- Apple|苹果高管解读AirPods 3代技术细节 暗示蓝牙带宽可能成为瓶颈
- 智能化|龙净环保:智能型物料气力输送系统的研究及应用成果通过鉴定
- 识别|天津滨海机场RFID行李全流程跟踪系统完成建设 行李标签识别成功率可提升至99%