大小|patch成为了ALL You Need?挑战ViT、MLP-Mixer的简单模型来了
【大小|patch成为了ALL You Need?挑战ViT、MLP-Mixer的简单模型来了】机器之心报道
机器之心编辑部
ViT(Vision Transformer)等视觉模型的强大性能 , 是来自于 Transformer , 还是被忽略的 patch?有研究者提出了简单 ConvMixer 模型进行证明 , 直接将 patch 作为输入 , 实验表明 , ConvMixer 性能优于 ResNet 等经典视觉模型 , 并且在类似的参数计数和数据集大小方面也优于 ViT、MLP-Mixer 及其一些变体 。近年来 , 深度学习系统中的卷积神经网络在处理计算机视觉任务中 , 一直占据主要地位 。 但最近 , 基于 Transformer 模型的架构 , 例如 ViT(Vision Transformer)架构(Dosovitskiy 等人 , 2020 年) , 在许多任务中都表现出了引人注目的性能 , 它们通常优于经典卷积网络 , 尤其是在大型数据集上表现更佳 。
我们可以假设 , Transformer 成为视觉领域的主导架构只是时间问题 , 就像它们在 NLP 领域中一样 。 然而 , 为了将 Transformer 应用于图像领域 , 信息的表示方法必须改变:因为如果在每像素级别上应用 Transformer 中的自注意力层 , 它的计算成本将与每张图像的像素数成二次方扩展 , 所以折衷的方法是首先将图像分成多个 patch , 再将这些 patch 线性嵌入, 最后将 transformer 直接应用于此 patch 集合 。
我们不禁会问:像 ViT 这种架构强大的性能是来自 Transformer, 还是至少部分是由于使用 patch 作为输入表示实现的?
在本文中 , 研究者为后者提供了一些证据:具体而言 , 该研究提出了 ConvMixer , 这是一个极其简单的模型 , 在思想上与 ViT 和更基本的 MLP-Mixer 相似 , 这些模型直接将 patch 作为输入进行操作 , 分离空间和通道维度的混合 , 并在整个网络中保持相同的大小和分辨率 。 然而 , 相比之下 , 该研究提出的 ConvMixer 仅使用标准卷积来实现混合步骤 。 尽管它很简单 , 但研究表明 , 除了优于 ResNet 等经典视觉模型之外 , ConvMixer 在类似的参数计数和数据集大小方面也优于 ViT、MLP-Mixer 及其一些变体 。

文章图片
- 论文地址:https://openreview.net/pdf?id=TVHS5Y4dNvM
- Github 地址:https://github.com/tmp-iclr/convmixer
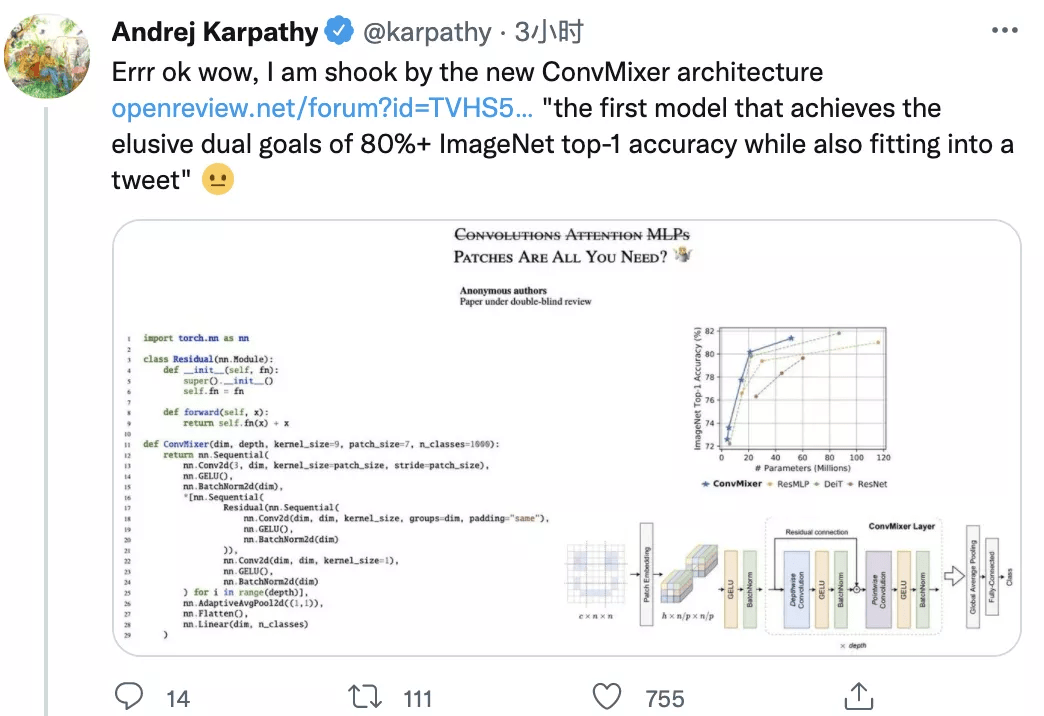
文章图片
有网友认为:「这项研究具有很重要的理论意义 , 因为它挑战了 ViT 有效性的原因 。 」

文章图片
推荐阅读







- 快报|“他,是能成就导师的学生”
- 地面|全程回顾神舟十三号航天员乘组圆满完成第二次出舱任务
- 最新消息|中围石油回应被看成中国石油:手续合法 我们看不错
- 人物|马斯克谈特斯拉人形机器人:有性格 明年底或完成原型
- 测试|图森未来完成全球首次无人驾驶重卡在公开道路的全无人化测试
- AMD|AMD 350亿美元收购赛灵思交易完成时间推迟 预计明年一季度完成
- 网络化|工信部:2025年建成500个以上智能制造示范工厂
- Apple|苹果高管解读AirPods 3代技术细节 暗示蓝牙带宽可能成为瓶颈
- 智能化|龙净环保:智能型物料气力输送系统的研究及应用成果通过鉴定
- 识别|天津滨海机场RFID行李全流程跟踪系统完成建设 行李标签识别成功率可提升至99%