机器之心报道
机器之心编辑部
最近一段时间 , 隐私计算成为了众多科技公司的研究方向 , 它或许将成为数据市场化的重要基础设施 。众所周知 , 数据的价值是在经济活动中信息交互所产生的——数据越流通 , 应用的场景越丰富 , 其价值会得到不断放大及提升 。 不过在数据流通过程中 , 我们必须时刻考虑数据安全与隐私保护问题 。
不久之前 , 蚂蚁集团智能引擎与数据中台技术部负责人、IEEE Fellow 周靖人博士在世界人工智能大会 WAIC 2021「隐私计算学术交流会」上发表了题为《开放智能—数据流通下的数据安全和数据隐私》的演讲 。
靖人从数据特性入手 , 对独特数据背景下如何做到数据安全、隐私保护 , 并发挥大数据应用的价值进行了讨论 , 同时也首次引入了「开放智能」概念 , 对于蚂蚁集团面向隐私计算的技术架构进行了一番介绍 。

文章图片
在活动中 , 蚂蚁集团的技术专家为我们展示了业内对于数据安全和隐私保护的最新思考 。
数据特性与算法伦理
首先为什么需要数据流通 , 因为数据产生的场景与应用场景不尽相同——你可能会因为买了一杯咖啡而产生了数据 , 但这些行为数据 , 包括购物习惯、生活习惯等会被应用在其他的场景中 。 数据只有在更多的场景中实现应用 , 其价值才能得到不断扩展 。
在数据流通的过程中 , 我们免不了会思考两个深层次的问题:数据权属和算法伦理 。
我们可以把数据分成两类 , 一类是个人的基础数据 , 比如性别 , 年龄等 , 这些数据归属于个人是没有太多异议的 , 另一类是行为数据 , 这类数据的产生涉及到多个数据主体:消费者是一个行为主体 , 同时商品、服务也是行为主体 , 还有一方涉及到平台 , 后者通过观察消费者和商品之间的一系列关系 , 再基于平台自身的知识 , 把相互的行为数据记录下来 。
可以看到 , 行为数据的产生涉及多个主体 , 我们很难把行为数据分割成服务信息或个体信息 , 同时行为数据的产生还涉及到平台的知识产权和劳动成果 。 在数据流通的过程中 , 我们需要合理分配和保护所有主体和数据参与者的权益 。
站在消费者角度 , 我们思考如何保护自己的隐私 , 并通过数据分享为自己带来更多的方便 。 同时在平台角度 , 基于大数据的算法需要大量技术投入 , 在数据流通的过程中 , 我们也希望能够保护平台方的知识产权和劳动成果 , 当然也需要平台依法接受监管 。
还有一个非常具有挑战性的问题 , 我们称之为算法伦理:应用数据后对算法产生的影响 。 这个范畴包括了可解释性、公平性、以及一系列的隐私保护 。
如今大量的应用使用了基于人工智能的算法 , 我们需要思考如何把社会学、经济学的思考映射到数学模型和算法方面 。
例如我们会发现:可解释性和隐私在某种程度上存在矛盾 。 AI 模型的可解释性需求往往是把一些模型的决策点一定程度上暴露出来 。 但随着模型决策点和边界条件的可视化 , 人们的隐私信息也在某种程度上面临着暴露 。 很多时候 , 从模型的推断结果可以反推一些人的基本属性——所以如何权衡这个问题 , 也是当下我们需要研究的重要课题 。
不过 , 可解释性和算法公平性又存在相互促进的关系 。 随着算法从一个黑盒变成白盒 , 慢慢引入可解释能力 , 我们将逐步消除 AI 算法中的潜在歧视 。
数据开放流通的三个层次
讨论完数据权属和算法伦理之后 , 我们来看看如何在数据流通中去解决上述问题 。
数据的流通可以简单归纳为三个层次:
- 第一层:仅涉及到个人数据的生产和融合 , 仅仅是一个个体或平台 , 或平台通过观察的方式积累个人行为数据 。 今天人们在电商平台 , 或聚合新闻平台、短视频应用等 , 都属于这样的场景 。
- 第二层:机构之间数据的互相交流 , 比较典型的例子是银行通过用户信息的流通不断提升风控能力 , 避免系统性风险 。
- 第三层:数据流通的生态 , 在理想情况下应该存在多个数据的提供方 , 以及多个数据的消费者 , 这中间有一系列的机制来保证数据隐私与安全 , 同时也能提供更好的数据服务 。
首先是个人数据生成和融合 。 这类场景会涉及到数据采集、模型训练 , 技术人员需要思考如何从数据挖掘核心信息 , 产生个性化模型 , 模型推理的结果会影响决策 。 这是一个比较长的链路 , 需在整个过程中关注如何保护个人隐私 。 保护往往需要从产品设计就开始考虑 , 并贯穿在产品的全生命周期中去 。 采集过程需以最小集采集为原则 , 而不是随意的、无明确范畴采集 , 这方面要引入差分隐私、数据脱敏等技术 。 在建立模型后 , 还需进行验证 , 确保模型可信——这方面有差分隐私可解释性的技术 。
当前的互联网正在进入云端协同的新阶段 , 消费者的行为通过手机或电脑在端上发生 , 模型很多在云上进行大规模机器学习训练产生 , 这样的体系被我们称为云端协同 。
在这个过程中 , 我们若想做到隐私保护 , 需要在端上实现理解用户的行为的同时 , 去做初步的数据筛选、数据清洗等等工作 。 清洗后的数据再到云端融合其他数据 , 产生新的模型计算 。 整个过程当中 , 云端系统并没有存储用户的行为 , 这种模式的真正应用能够为消费者提供更好的权益 。
最典型的形式是联邦学习 , 它可以说是一个分布式学习框架 , 在数据采集后采用不出域的原则 , 也就是我们今天可以把很多原型计算放到端侧设备上 , 通过协同方式去创建联合学习模型的方式 。 在这个过程中我们也可以通过差分隐私、可信执行环境等技术去加强数据保护的能力 。
机构之间的数据开放互通 , 通过各机构之间信任关系、网络状态、数据量以及模型复杂度等方式 , 可分为下面几个类别:
- 最直接的是集中式模式 , 也就是数据各个机构、参与方能够把数据汇总到集中式环节里进行模型训练 , 进行整个认知智能的探索 。 或使用一个特定的小集群来提供高效的数据融合 , 后者的好处是效率高 , 数据融合在一个主体 , 就可进行非常复杂的计算 , 它面临的挑战是如何搭建起可信环境 。 所以在实践中 , 我们经常会采用中心化模式 。
- 去中心化模式中 , 所有的模型训练是分布式执行:数据提供方也是计算参与方 。 通过多方的协同来进行联合训练、联合学习 。 技术就会涉及到多方安全计算、同态加密等 。 在计算过程中做加密虽然带来了安全性保障 , 对性能也提出了很大挑战 。 该模式可做到安全可证 , 但同时会为性能付出代价 。
- 集中式模式和去中心化模式之间还有一种中间状态 , 即联合计算模式 。 这个模式里 , 每方都会参与到模型计算 , 同时再引入中心化模块概念 , 其可以协调计算、模型训练 。 这里具有代表性的是联邦学习 , 拆分学习等 , 都属于联合计算学习框架 。 在这个框架中 , 我们需要通过差分隐私来保护各个模块与中心化模块之间的通信 。 以信息论为基础 , 我们可以度量任何信息交互所可能带来的个人隐私风险 , 也就是说个人隐私在联邦学习环境中计算所带来的一系列风险是可度量的 。
开放智能技术
如何把上面讨论的内容形成体系化的技术框架 , 去解决数据流通过程中遇到的各种问题 , 保证在各种复杂场景中数据的安全及隐私保护呢?
这里引入一个新名词:开放智能 , 指的是用于解决数据开放流通过程中所面临的一系列问题的前沿技术的统称 。 这个领域非常复杂 , 技术也非常具有挑战性——在开放智能中 , 我们会面临多个数据主体 , 包括个人、企业 , 甚至政府 , 每一类主体的意愿、诉求都各不相同 。 个人层面想做到隐私保护 , 企业诉求是希望保护自己的知识产权和劳动成果 。 政府首先关注社会利益 。 同时还会涉及到如何激励开放的意愿 , 同时避免数据歧视、算法垄断等 。
我们可把开放智能的技术分为五部分:
- 首先是是底层的数据技术 , 主要用于解决数据授权的问题 。
- 其次是计算技术 , 包括可信计算、可度量计算、可证计算 , 用于解决计算过程中的隐私保护问题 。
- 第三层为算法层 , 解决合规合法、算法伦理、鲁棒性等算法可信赖的问题 。
- 在此之上还有市场构建 , 需要思考如何通过激励机制、定价等 , 促进形成良好生态 , 解决数据流通过程中的效率问题 。
- 最后是可验证技术 , 当模型训练好之后 , 我们需要确保模型实现的的确是我们需要它做的事情 。
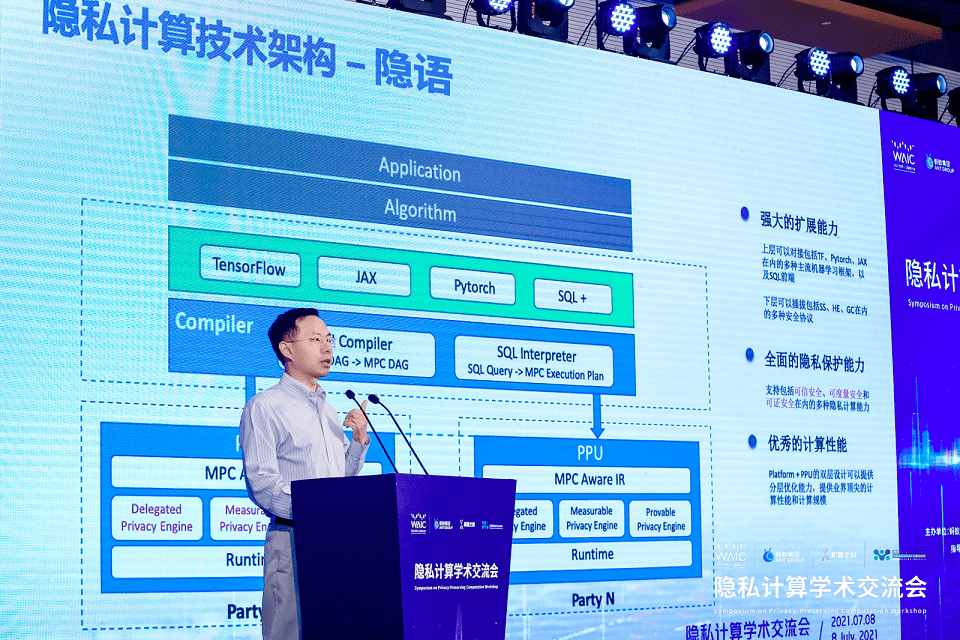
该框架有两个层次 , 上面一层是编译器 , 通过新的编译器技术 , 我们可以将整个执行图自动编译成密态计算图 , 并对其进行一系列的优化 。 下面一层是分布在不同参与方的 PPU(Privacy Preserving Unit) , 每一个 PPU 提供可信可证可度量的基础计算能力 。 由编译器生成的密态计算图会被分发到 PPU 上进行计算 , 最终产出用户需要的计算结果 。
文章图片
蚂蚁集团的隐私计算技术架构——隐语 , 具有以下几个特点:
- 可扩展性 , 支持当前主流的机器学习的框架 , 上层可对接包括 TensorFlow、Pytorch、JAX 在内的多种主流机器学习框架 , 以及 SQL 前端;下层可以链接包括 SS、HE、GC 在内的多种安全协议 。
- 隐私保护能力:支持包括可信安全、可度量安全和可证安全在内的多种隐私计算能力 。
- 计算效率:目前隐私计算最大的问题在于性能瓶颈 , 蚂蚁集团对框架做了多方面的优化 , 包括 Platform + PPU 的双层设计可以提供分层优化能力 , 可以提供业界顶尖的计算性能和计算规模 。
这样一套隐私计算体系目前已经获得了应用 , 一个的典型的场景是在个人信贷上 。
人们在银行办理贷款时 , 银行为了降低风险 , 往往会参考用户之前在银行系统中进行过的各类操作 , 包括购买的基金、金融产品 , 日常消费流水等 。 系统完整的分析结果会帮助我们提供更好的数据的服务 , 但这个过程需要全链路、健全机制的保障 , 需要在用户授权的情况下进行分析 。
为实现上述效果 , 就会涉及到多方安全计算 。 在联合计算之后还需进行验证 , 以确保每个数据参与方真正完成了它所需要做的计算 。 当训练好 AI 模型后 , 因为不能是黑盒状态 , 需要实现可解释 , 还要面向消费者进行告知:为什么今天可以贷这么多款 。 系统也不能因为客户的性别、年龄就对用户区别对待 , 在这一环节也需确保算法是公平的 。 最后 , 还有非常重要的监管环节 , 要有存证、审计的能力 。
开放智能是一个包含多领域知识的技术体系 , 涉及到了数据鉴权、隐私计算、可信赖 AI、市场机制等 。 这是一个崭新的领域 , 还有很多技术有待研究和创新 。 随着人们的不断参与 , 未来我们还将看到越来越多的新进展 。
推荐阅读







- Google|谷歌暂缓2021年12月更新推送 调查Pixel 6遇到的掉线断连问题
- 精度|将建模速率提升10倍,消费级3D扫描仪Magic Swift在2021高交会大显“身手”
- 四平|智慧城市“奥斯卡”揭晓!祝贺柯桥客户荣获2021世界智慧城市治理大奖
- 系列|2021中国航天发射圆满收官!年发射55次居世界第一
- 项目|常德市二中2021青少年科技创新大赛再获佳绩
- 选型|数据架构选型必读:2021上半年数据库产品技术解析
- 殊荣|蝉联殊荣!数梦工场荣获DAMA2021数据治理三项大奖
- 公司|外媒:2021,人类太空事业的重大年份
- 语境|B站2021个人年度报告发布:你共计看了多少个视频
- 最新消息|IT系统出错 英国银行给7.5万人多发11亿工资