近期 , 自然语言处理(NLP)国际顶级学术会议ACL-IJCNLP 2021公布了论文录用结果 。 百度共有14篇论文被大会收录 , 内容覆盖跨模态预训练、语言理解、人机对话、机器翻译、知识图谱等多个方向 。
文章图片
ACL是自然语言处理领域影响力最大的国际学术组织 , 自创办以来吸引着全世界众多国家和地区的专家学者踊跃参与 。 据官网数据显示 , 本届大会共收到3350篇有效论文投稿 , 主会论文和Findings论文录用率分别为21.3%和14.9% , 含金量极高 。 百度在多个重要方向论文入选 , 展现了在自然语言处理领域的领先技术实力 。
以下为ACL-IJCNLP 2021百度被收录的相关论文介绍:
1、UNIMO:基于跨模态对比学习的统一模态理解与生成方法
UNIMO: Towards Unified-Modal Understanding and Generation viaCross-Modal Contrastive Learning
论文链接:https://arxiv.org/abs/2012.15409
GitHub链接:https://github.com/PaddlePaddle/Research/tree/master/NLP/UNIMO
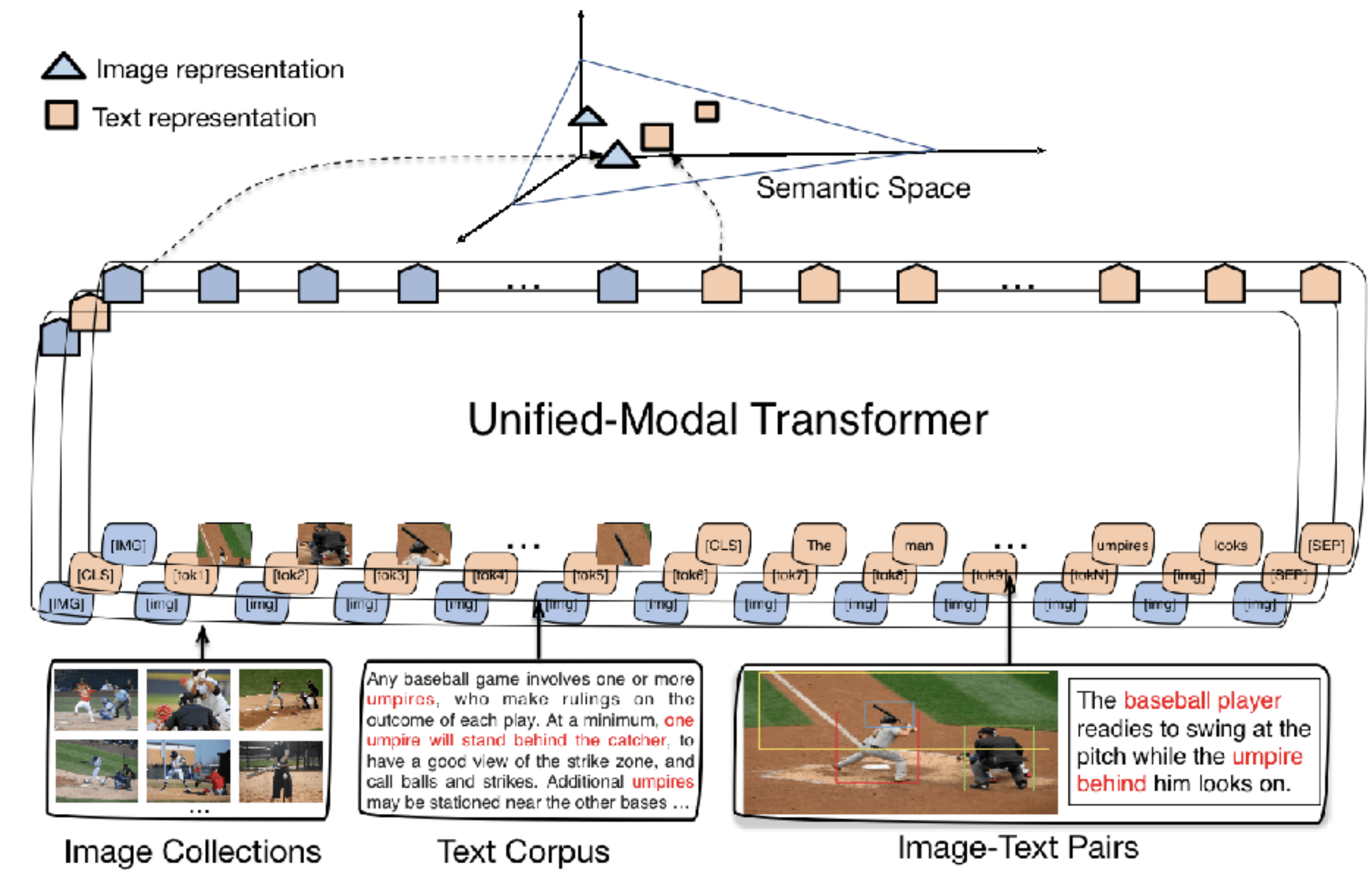
近年来 , 预训练技术在计算机视觉和自然语言处理领域均受到广泛关注 。 在视觉领域 , 基于图像数据的单模预训练有效提升了视觉特征的提取能力 。 在自然语言处理领域 , 基于自监督的预训练语言模型则利用大规模的单模文本数据 , 显著提升了模型的语言表示能力 。 为了处理多模场景的任务 , 多模预训练模型基于多模图文对数据进行预训练 , 从而有效支持下游的多模任务 。 然而 , 受限于图文对数据量 , 多模预训练模型通用性欠佳 。
基于深度学习的AI系统能否像人一样同时学习各类异构模态数据 , 包括文本、图像等单模数据 , 以及图文对等多模数据呢?如果能够实现 , 无疑将进一步拓展深度学习对大规模数据利用的边界 , 从而进一步提升AI系统的感知与认知能力以及AI算法的通用性 。 针对这一问题 , 本文提出统一模态学习UNIMO , 同时利用大规模单模文本、单模图像以及多模图文对数据进行联合学习 , 通过跨模态对比学习方法 , 有效地对语言知识与视觉知识进行统一表示和相互增强 , 从而具备同时处理多种单模态和多模态下游任务的能力 。
UNIMO在语言理解与生成、多模理解与生成等四类场景共十多个任务上超越主流的文本预训练模型和多模预训练模型 , 首次验证了通过非平行的文本与图像单模数据 , 能够让语言知识与视觉知识相互增强 。 UNIMO也同时登顶了视觉问答VQA和文本推理aNLI权威榜单 。
文章图片
2、ERNIE-Doc:回顾式建模长文本预训练技术
ERNIE-Doc: ARetrospective Long-Document Modeling Transformer
论文链接:https://arxiv.org/abs/2012.15688
GitHub链接:https://github.com/PaddlePaddle/ERNIE/tree/repro/ernie-doc
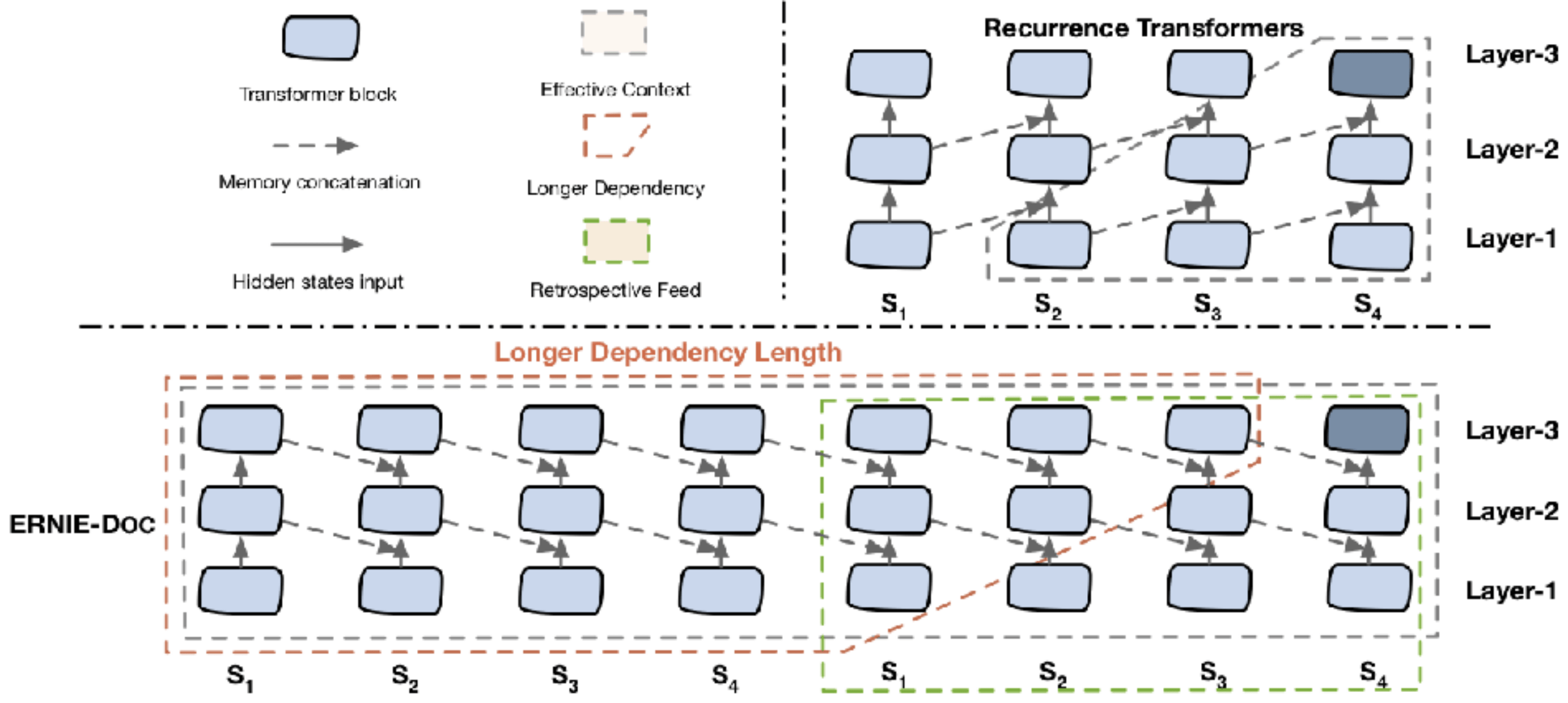
Transformer 是预训练模型所依赖的主流网络结构 , 但由于其计算量和空间消耗随建模长度呈平方级增加 , 导致模型难以建模篇章、书籍等长文本内容 。 受到人类先粗读后精读的阅读方式启发 , 本文提出了回顾式建模技术ERNIE-Doc , 突破了Transformer在文本长度上的建模瓶颈 , 实现了任意长文本的双向建模 。
通过将长文本重复输入模型两次 , ERNIE-Doc在粗读阶段学习并存储全篇章语义信息 , 在精读阶段针对每一个文本片段显式地融合全篇章语义信息 , 从而实现双向建模 , 避免了上下文碎片化的问题 。 此外 , 传统长文本模型(Transformer-XL等)中Recurrence Memory结构的循环方式限制了模型的有效建模长度 。 ERNIE-Doc将其改进为同层循环 , 使模型保留了更上层的语义信息 , 具备了超长文本的建模能力 。 最后 , 通过让模型学习篇章级文本段落间的顺序关系 , ERNIE-Doc更好地了建模篇章整体信息 。
ERNIE-Doc显著提升了长文本的建模能力 , 在包括阅读理解、信息抽取、篇章分类、语言模型等不同类型的13个权威中英文长文本任务上取得了SOTA效果 。
文章图片
3、BASS:基于统一语义图增强的生成式文本摘要
BASS: Boosting Abstractive Summarization with Unified Semantic Graph
论文链接:https://arxiv.org/pdf/2105.12041.pdf
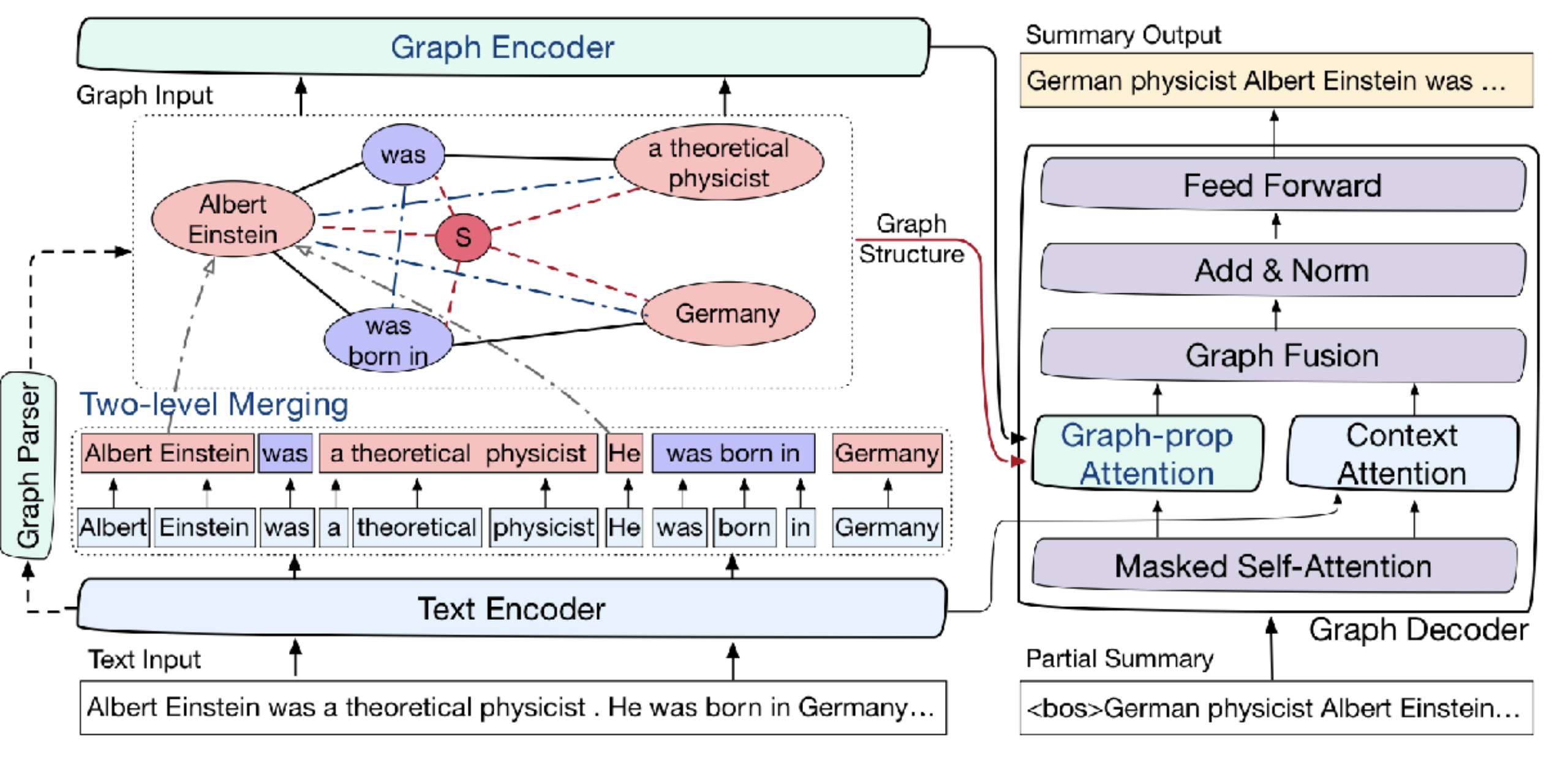
序列到序列 (Seq2Seq)一直以来是生成式摘要中最为流行的架构 , 并在近期的研究中取得了不断的进步 。 但是由于Seq2Seq结构中缺乏对文档结构的理解 , 长文本摘要和多文档摘要等较为复杂的摘要任务仍然给予Seq2Seq模型较大的挑战 。 针对这一问题 , 本文提出了BASS模型 , 一种基于统一语义图的生成式摘要框架 。 短语级别的统一语义图聚合了分散在文本集合不同位置的共指短语 , 且短语之间的结构蕴含了丰富的语义关系 , 从而显式地表示了输入文本集合的语言结构 。 BASS模型利用图神经网络显式地建模了统一语义图结构 , 并同时融合了非结构化的文本序列信息 。 在统一语义图的指导下 , BASS模型可以更高效地筛选文中的重要信息并组织生成信息丰富、语义连贯的摘要 。 BASS同时在编码和解码过程中提出了针对图结构建模的增强机制 , 以更好地挖掘统一语义图中的语义结构信息 。 在多文档数据集WikiSum和长文档数据集BIGPATENT上的实验表明 , 本文提出的方法可以有效地提升摘要生成的质量 。
文章图片
4、DuReader_robust:评估真实应用场景下机器阅读理解鲁棒性与泛化性的中文数据集
DuReader_robust: A Chinese Dataset Towards Evaluating Robustness and Generalization of Machine Reading Comprehension in Real-World Applications
论文链接:https://arxiv.org/abs/2004.11142
GitHub链接:https://github.com/baidu/DuReader
机器阅读理解(MRC)是自然语言处理领域中的重要研究课题 。 本文提出了一个全新的中文机器阅读理解数据集DuReader_robust , 数据集中的全部样例均为真实应用场景下的自然文本 , 旨在从过敏感(Over-sensitivity)、过稳定(Over-stability)与泛化能力(Generalization)三个方面评估现有MRC模型在实际应用场景中的鲁棒性与泛化性(如下图示例) 。 此外 , 本文也基于DuReader_robust进行了大量实验 , 希望通过这些实验对未来的MRC研究有所启发 。 最后 , 我们已经将DuReader_robust数据集开源以丰富中文MRC的语料资源 。
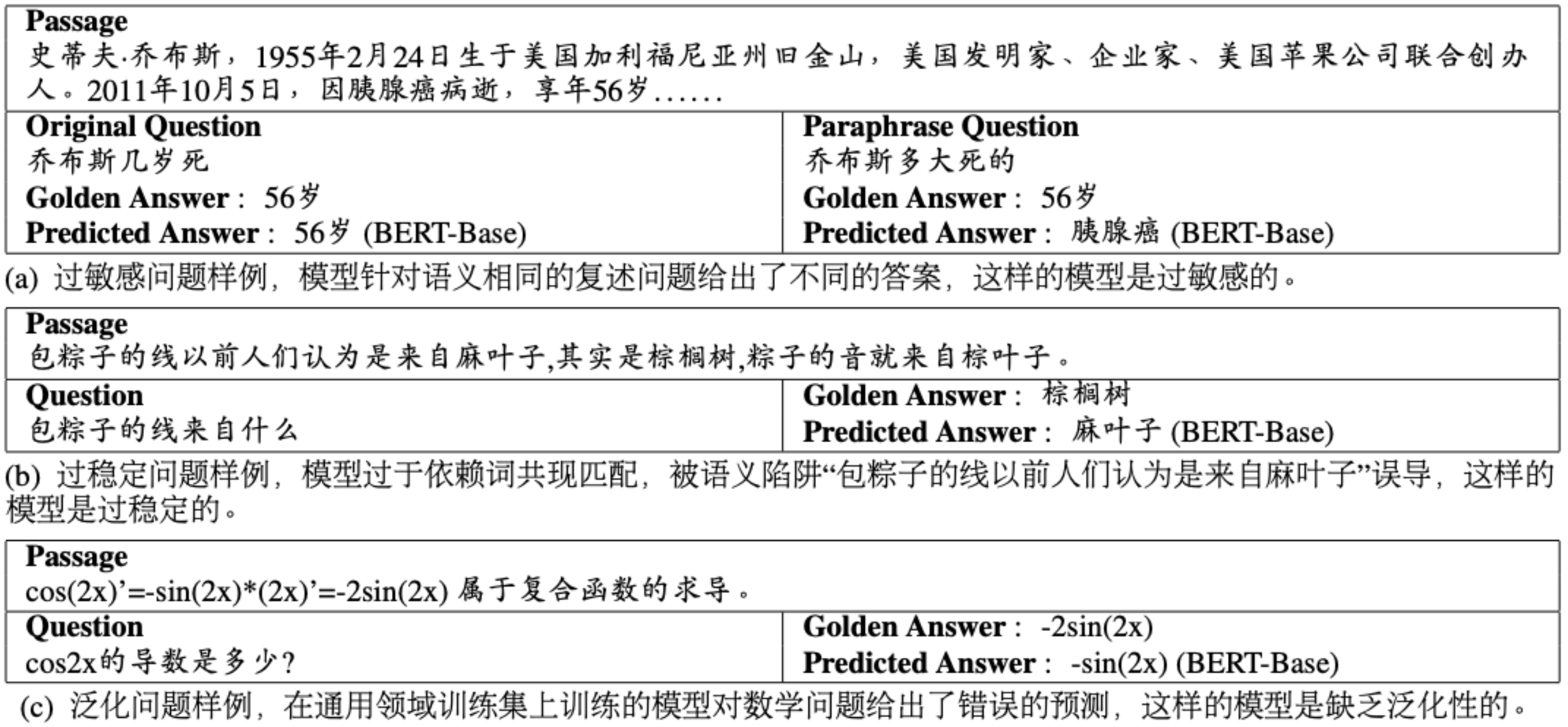
文章图片
5、开放域对话结构发现
Discovering Dialog Structure Graph for Coherent Dialog Generation
论文链接:https://arxiv.org/abs/2012.15543
从真实人-人对话中学习离散的对话结构图 , 有助于人们理解对话规律 , 同时也可以为生成通顺对话提供背景知识 。 然而 , 当前在开放域对话下 , 这一问题缺乏研究 。 在本文中 , 我们从聊天语料库中无监督地学习离散对话结构 , 然后利用该结构来促进连贯的对话生成 。 为此 , 我们提出了一个无监督模型(DVAE-GNN) , 来发现多层次的离散对话状态(包括对话和句子层)以及学习不同对话状态之间的转移关系 。 其中 , 对话状态以及状态之间的转移关系组成了最终的对话结构图 。 进一步的 , 我们在两个基准语料库上进行实验 , 结果表明DVAE-GNN能够发现有意义的对话结构图 , 且使用对话结构作为背景知识可以显著提高开放域对话的多轮连贯性 。
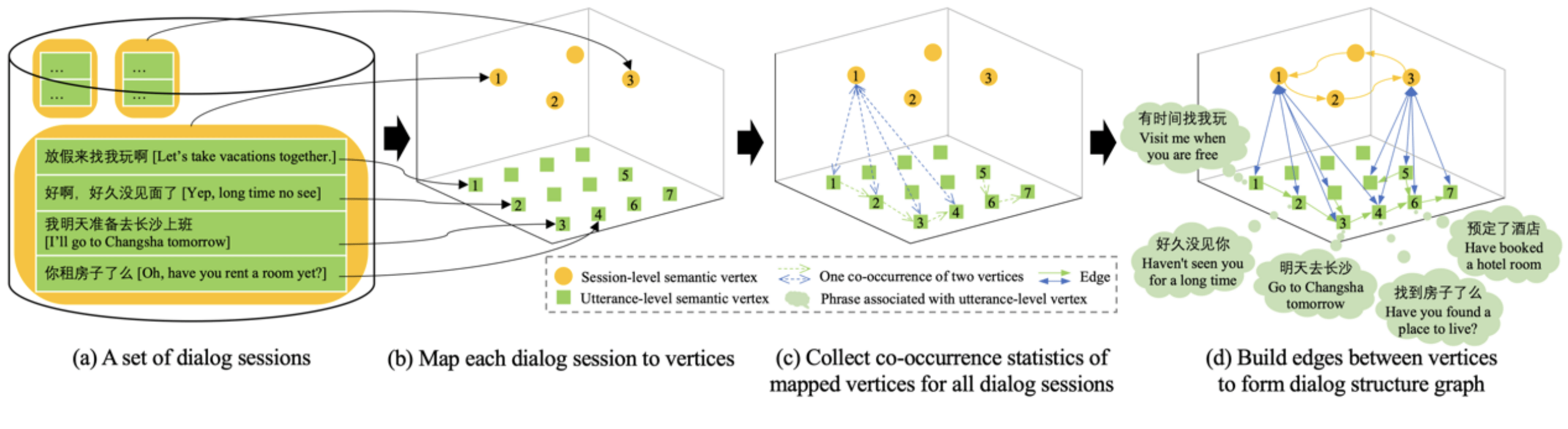
文章图片
6、PLATO-2: 基于课程学习的开放域对话机器人
PLATO-2: Towards Building an Open-Domain Chatbot via Curriculum Learning
论文链接:https://arxiv.org/abs/2006.16779
GitHub链接:
https://github.com/PaddlePaddle/Knover/tree/develop/projects/PLATO-2
近期一些端到端的对话生成模型 , 通过更大的模型规模、更多的训练语料 , 获得了更加优秀的对话生成能力 。 PLATO-2 承袭了 PLATO 隐变量进行回复多样化生成的特性 , 模型参数规模上升到了 16 亿 。 考虑到精细化的引入隐变量的网络训练 , 计算消耗很大 , PLATO-2 采取了课程学习的方法 , 逐步优化参数 , 加快训练效率 。 第一阶段 , 基于简化的“一对一”映射 , 训练得到基础的回复生成模型;第二阶段包含生成-评估两个模型 , 针对开放域对话的“一对多”问题 , 通过引入离散隐变量进行建模 , 训练得到更高质量的回复生成模型 , 同时训练评估模型 , 从多个候选中选择出最合适的回复 。 PLATO-2 包含中英文版本 , 实验评估上全面超越了 Google Meena、Facebook Blender、微软小冰等模型 , 取得了新的 SOTA 效果 。 PLATO-2 框架具有很强的通用能力 , 在预训练各个阶段所获得的模型可广泛支持多种类型的对话系统 。 PLATO-2 参与了对话领域顶级赛事 DSTC9 并取得了5项冠军 , 这些赛道全面涵盖了开放域闲聊、知识对话、任务型对话等关键问题 , 充分展示了 PLATO-2 在对话领域强大的通用能力 。
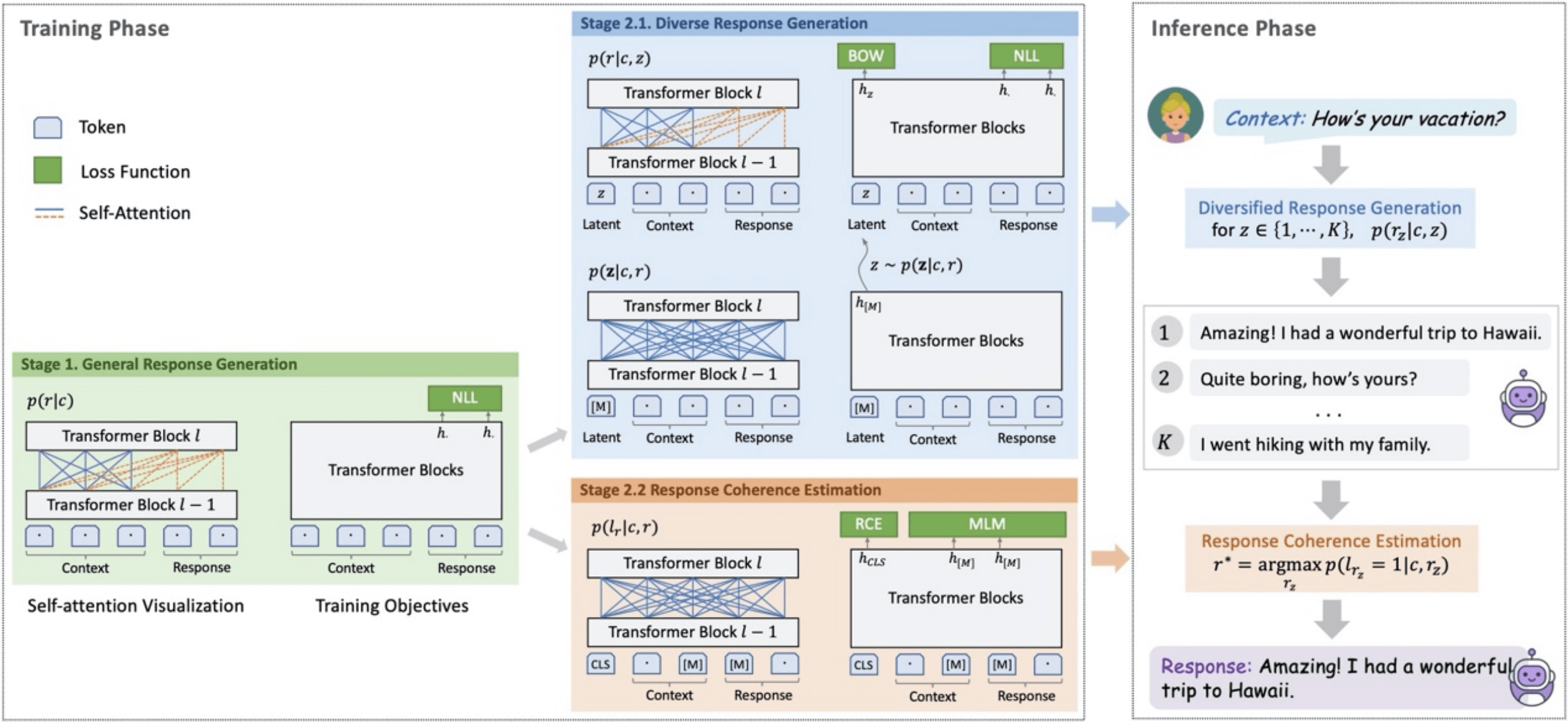
文章图片
7、CluSTeR:认知启发的时序知识图谱两阶段推理模型
Search from History and Reason for Future: Two-stage Reasoning on Temporal Knowledge Graphs
基于时序知识图谱的未来事件推理任务试图根据过去发生的事件来预测未来事件 , 可以为下游任务如消费意图挖掘、社会行为分析、金融分析、辅助决策和快速事件反应等提供技术支持 , 从而具有很强的研究价值 。 本文受到认知中决策双系统理论的启发 , 将未来事件推理分解成由直觉系统主导的线索搜索阶段和理性系统主导的时序推理阶段 。 在线索搜索阶段 , 模型使用基于随机束搜索的强化学习方法快速搜索历史 , 归纳导致事件发生的线索 , 得到直觉上的候选答案 。 在时序推理阶段 , 模型深入到第一阶段得到的线索中 , 按照线索发生时间重组线索并使用基于多关系图神经网络的序列模型进行时序演绎 , 从而得到精准答案 。 本文在三个实体推理数据集上取得了最好的效果 , 其中MRR最多提升7.1% 。 同时 , 模型推理过程中发现的显式线索也为模型推理结果提供了依据和可解释性 。
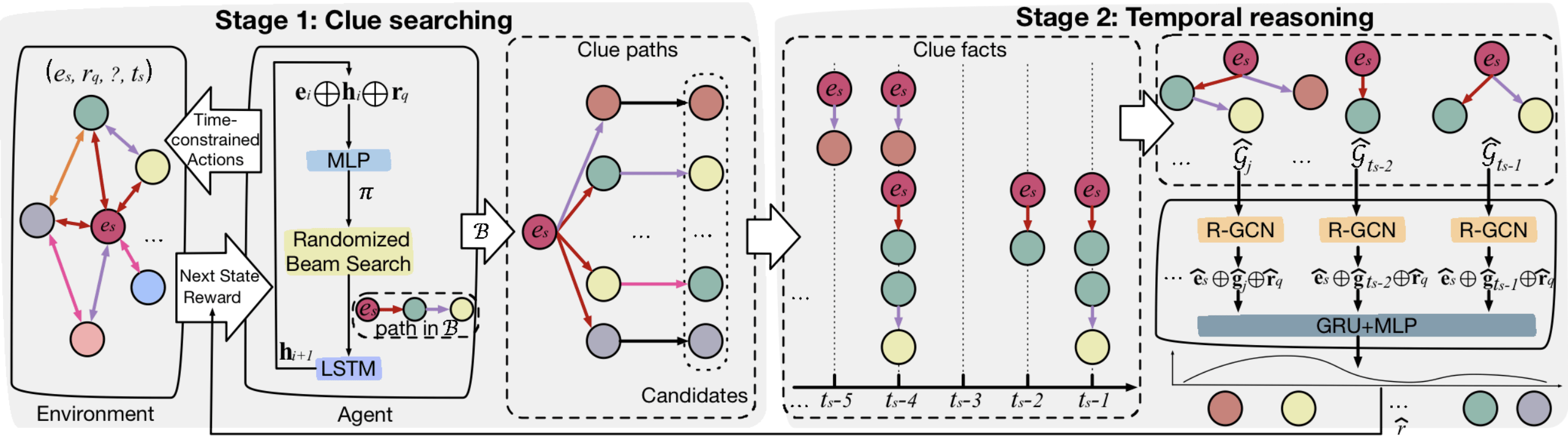
文章图片
8、基于图表示的多元关系链接预测
Link Prediction on N-ary Relational Facts: A Graph-based Approach
论文链接:https://arxiv.org/abs/2105.08476
知识图谱上的链接预测是典型的知识推理任务 , 近年来受到了学术界和工业界的广泛关注 。 现有的链接预测算法大多针对知识图谱中的二元关系而设计 , 无法处理其中普遍存在的多元关系 。 为此 , 本文创新性地提出了一种基于异构图表示的多元关系学习算法(GRAN) , 能够针对知识图谱中的多元关系进行有效的链接预测 。 GRAN首先将多元关系陈述表示为异构图 , 同时利用拓扑结构感知的自注意力机制对异构图进行建模 , 实现多元关系的学习与推理 。 实验表明 , GRAN能够保留多元关系陈述的完整语义 , 同时有效建模其元素间的丰富交互以增强模型的推理能力 , 在众多多元关系链接预测标准数据集上全面大幅超越现有方法 。
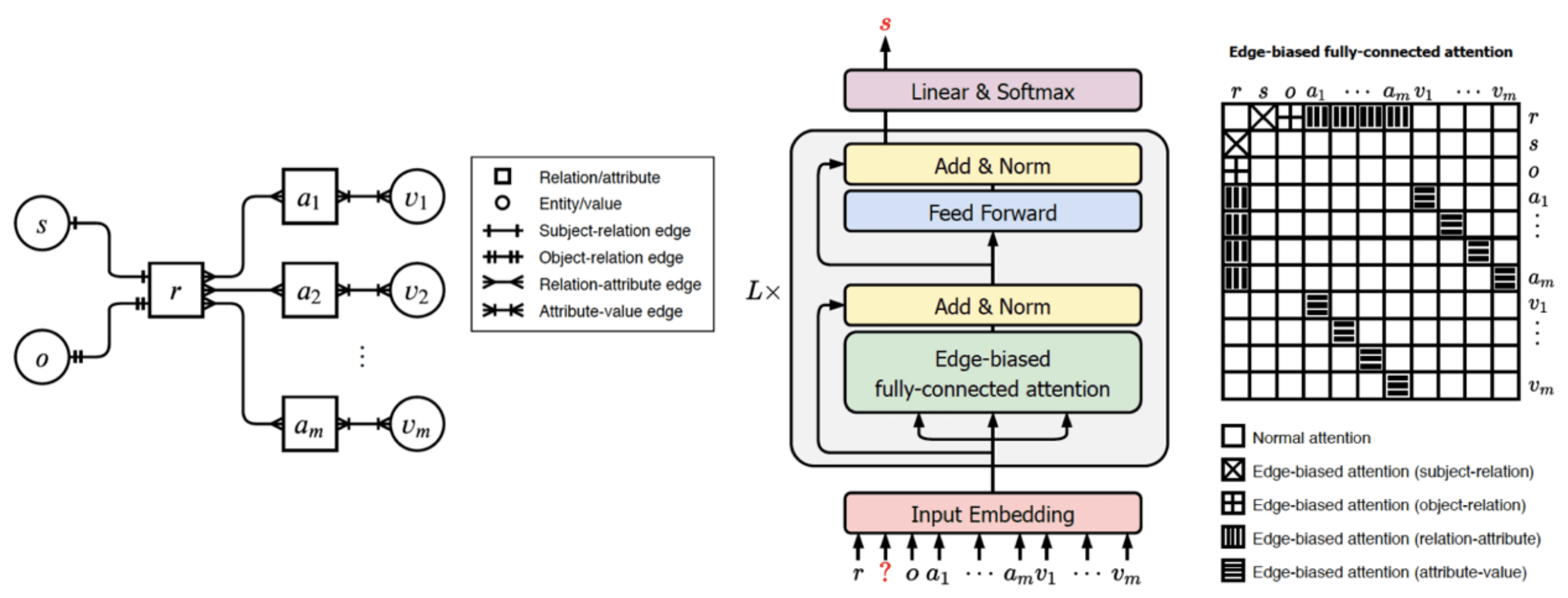
文章图片
9、MLM-phonetics: 基于语音语义的预训练纠错模型
Correcting Chinese Spelling Errors with Phonetic Pre-training
在日常工作中经常会出现拼写错误 , 而错误传递会导致下游任务(如检索、翻译、理解等)的效果下降 , 因此文本拼写纠错非常重要 。 对于中文来说 , 常用的输入方式有拼音输入、语音输入等 , 使得拼写错误大多来自于对近音字的混淆 。 因此我们提出了MLM-phonetics , 一个基于语音和语义的预训练语言模型 。 不同于传统预训练中的掩码语言模型(Masked Language Model), MLM-phonetics的预训练目标加入了从近音字及其拼音中恢复出正确字的任务 , 这使预训练模型具备了纠错能力 。 基于MLM-phonetics , 我们提出了一个端到端的中文纠错模型 , 它包含一个检测模块和一个纠错模块 。 给定一段文本 , 检测模块首先检查该文本中的错字 , 然后以每个字的错误概率为权重融合原始字符与其拼音的编码 , 之后纠错模块基于新的编码进行纠错 。 两个模块共享以MLM-phonetics初始化的编码器 , 并在端到端的模型中被同时优化 。 我们的模型在SIGHAN中文纠错测试集上达到SOTA , 这项技术可应用于文本写作纠错、语音识别结果纠错、翻译译前纠错等场景 。
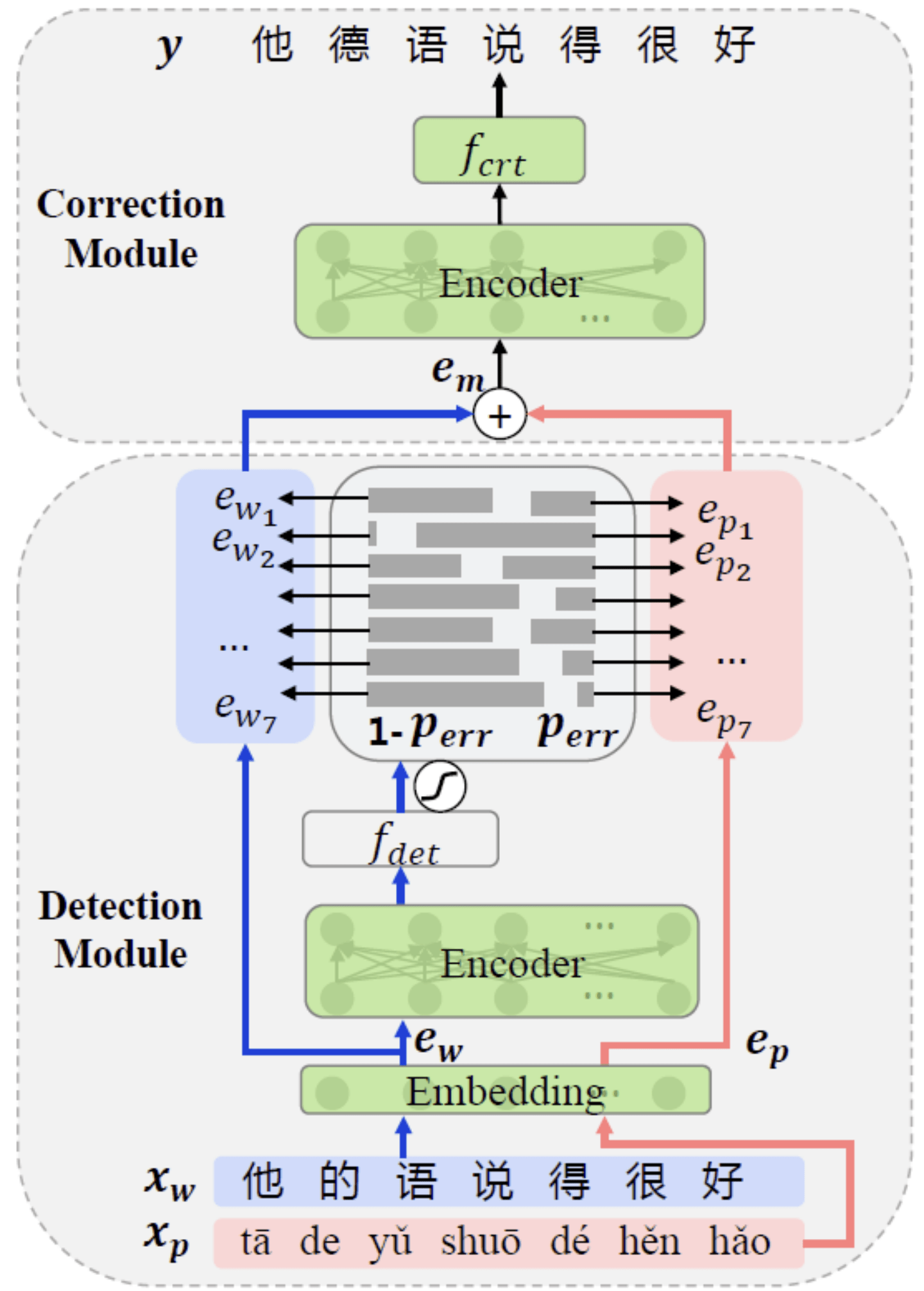
文章图片
10、PAIR: 基于以段落为中心的相似度关系提升稠密段落检索
PAIR: Leveraging Passage-Centric Similarity Relation for Improving Dense Passage Retrieval
近年来 , 稠密段落检索(dense passage retrieval)已经成为多个自然语言处理和信息检索任务中召回相关信息的主流方法 , 对偶式检索模型是其中采用最为广泛的模型结构 。 以前的相关工作 , 主要考虑了以查询(query)为中心的相似度关系 , 即查询和段落之间的相似度(下图a) , 而忽略了段落之间的相似度 。 本文提出了一种同时以查询为中心和以段落为中心的相似度关系度量方法(下图b) , 即通过引入段落正负例之间的相似度关系 , 来更好地学习查询和段落的语义表示 。 我们在MSMARCO和Natural Questions两个公开数据集上进行了实验 , 证明了方法的有效性 , 并验证了模型学习到了以段落为中心的相似度关系 。
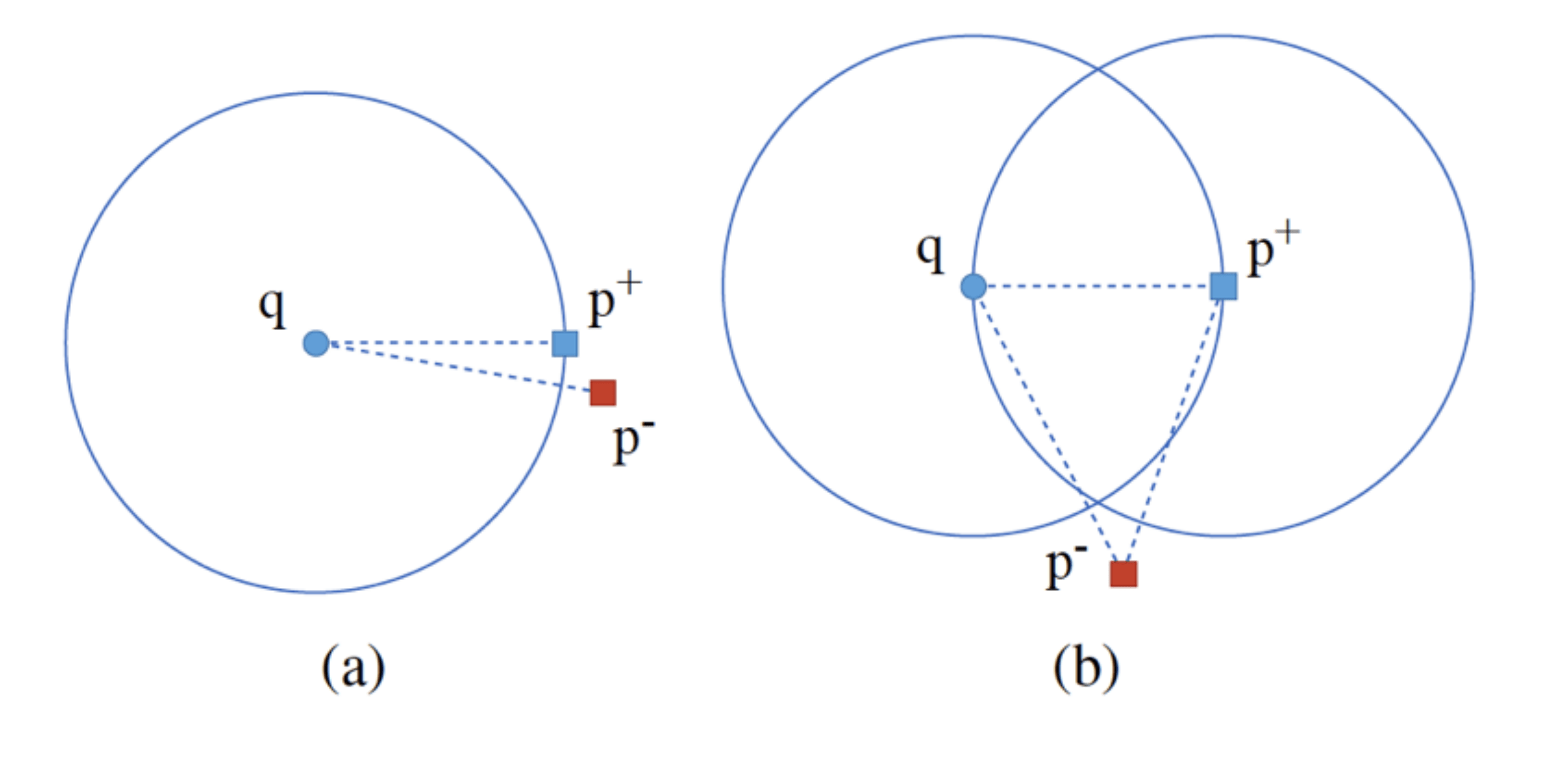
文章图片
相似度关系示意图:
(a)以查询为中心的相似度关系;
(b)同时以查询为中心的相似度关系和以段落为中心的相似度关系 。
11、基于同步流式语音识别辅助的直接端到端语音同传
Direct Simultaneous Speech-to-Text Translation Assisted by Synchronized Streaming ASR
同声传译(simultaneous speech to text translation)在平时生活中有着广泛的应用场景 。 目前 , 传统的级联式解决方案利用流式语音识别模型(streaming ASR)和文本机器同传模型(Simultaneous MT)将源语言的语音信号翻译至目标语言的文字 。 这种级联式的方法会传递因语音识别而导致的错误 , 同时会引入额外的语音识别和翻译模块间的时延 。 最近一些端到端的方法尝试直接将源语音翻译成目标文本 , 但是在语音同传场景下 , 普通的语音翻译模型无法像文本同传一样准确掌握源句中的词数以及词的边界 , 而无法准确的执行解码策略 。 我们提出了一种同时具有级联和端到端方法优点的新解决方案 。 我们分别使用两个同步的解码器用以执行流式语音识别和语音翻译(speech translation) , 并且这两个解码器共享同一个语音编码器 。 流式语音识别可以精准的判断词数和词边界 , 从而实时指导语音翻译的解码策略 。 语音翻译解码器仅从语音信号中直接获得翻译信息 , 从而降低了误差传播和翻译时延 。 我们通过多任务学习对模型进行训练 。 在MuST-C数据集上进行的En-to-De和En-to-Es实验表明 , 我们提出的方法在相同的时延下取得了更好的翻译质量 。
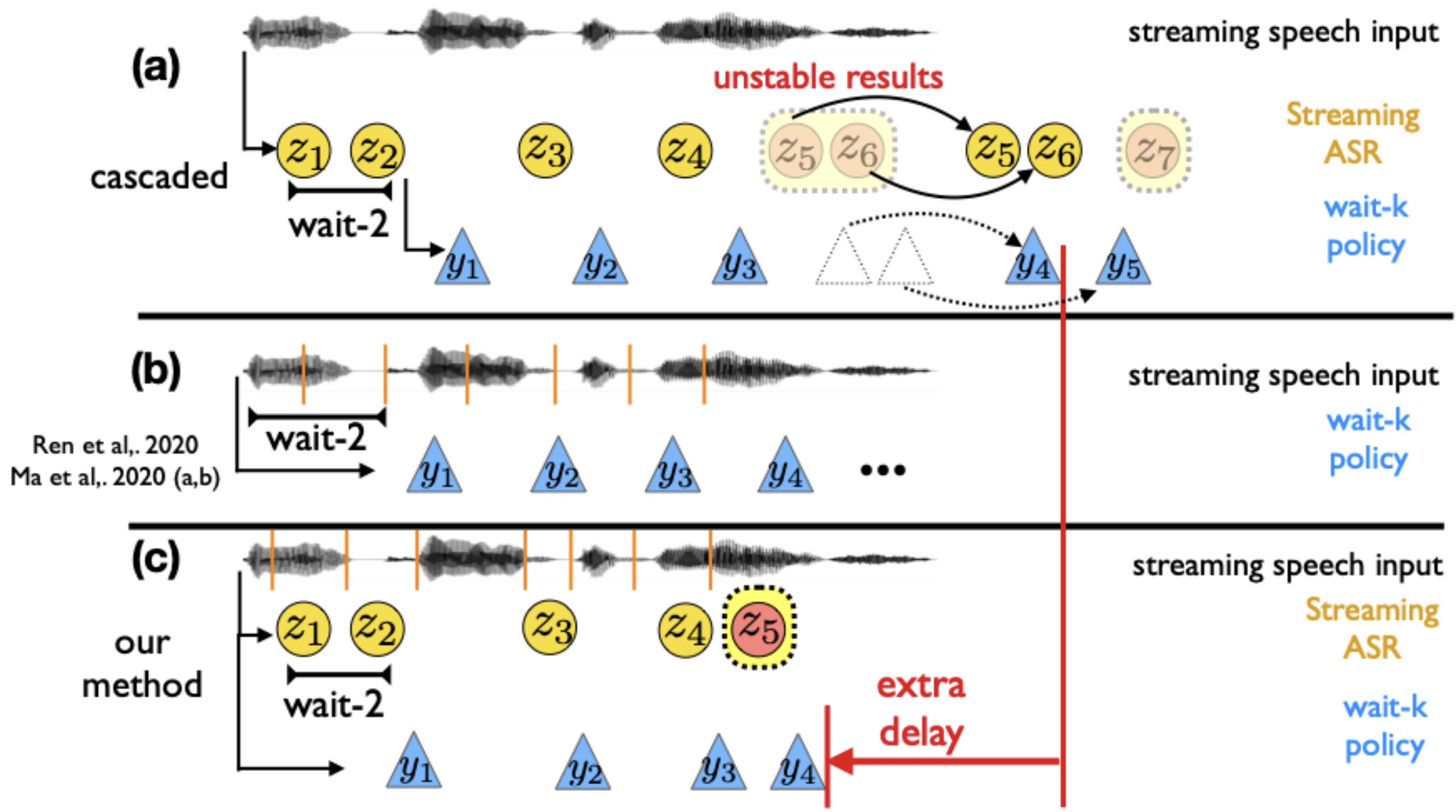
文章图片
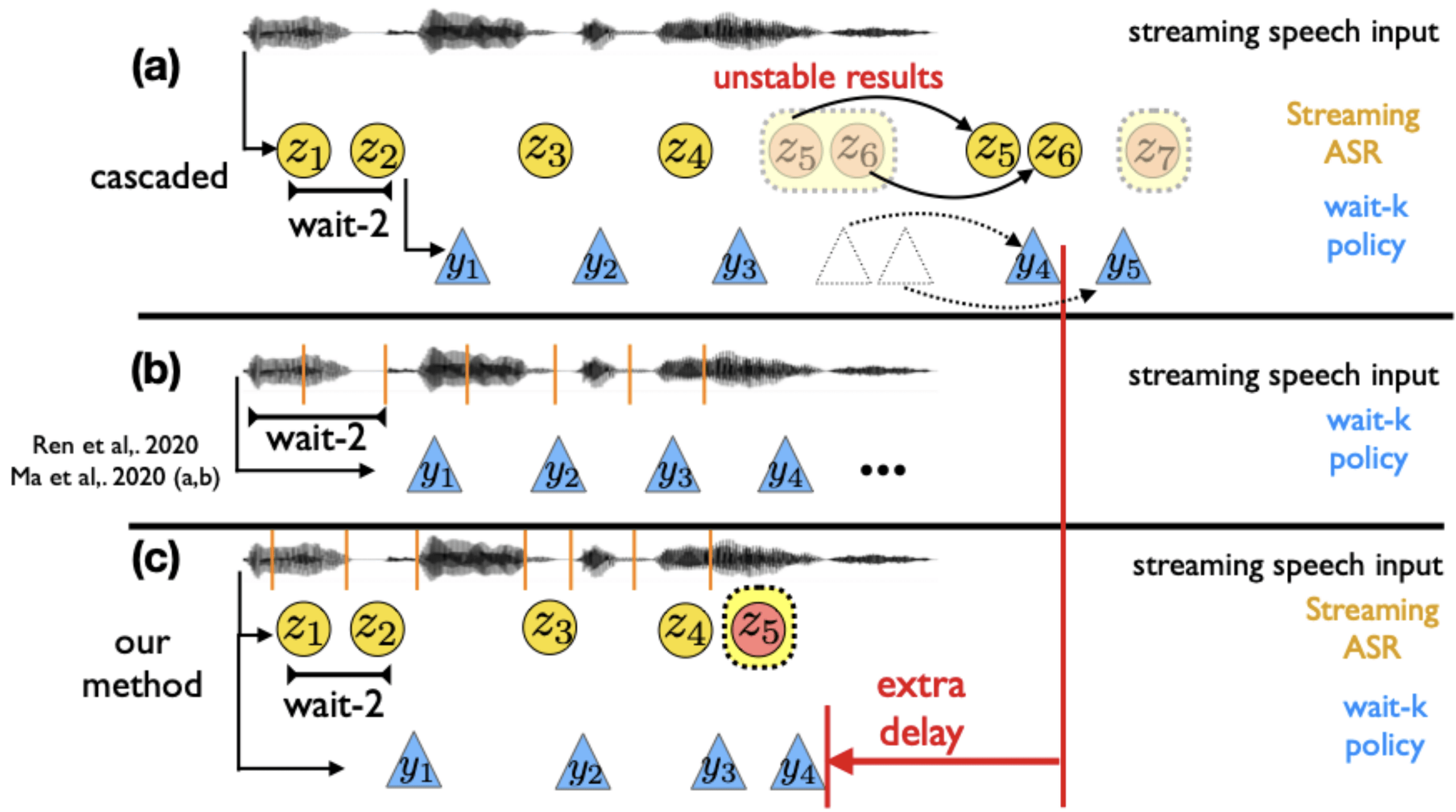
文章图片
12、可学习知识引导的事件因果关系识别数据增强方法
LearnDA: Learnable Knowledge-Guided Data Augmentation for Event Causality Identification
事件因果关系识别(EventCausalityIdentification, ECI)旨在识别文本中事件之间的因果关系 , 可以为许多自然语言处理任务提供重要线索 , 如逻辑推理、问答系统等 。 ECI任务通常被建模为一个分类问题 , 即识别一个句子中两个事件之间是否存在因果关系 。
目前大多数ECI方法采用监督学习的范式 。 虽然这些方法取得了很好的性能 , 但通常需要大规模的标注训练数据 。 然而 , 现有的事件因果关系识别数据集相对较少 。 小规模的标注数据集阻碍了高性能事件因果关系识别模型的训练 , 无法提供充足的训练数据支撑模型准确理解文本中的事件关系语义 。
本文探索了一个知识融合的数据增强方法 , 利用大量抽取的因果相关事件生成新训练数据 , 解决ECI任务训练数据缺失问题 。 该方法包含两个框架 , 知识增强的事件因果关系数据自动标注框架和知识引导的事件因果关系数据生成框架 。 其中 , 知识引导的事件因果关系数据生成框架(Learnable Data Augmentation framework, LearnDA) , 利用对偶学习机制 , 将事件因果关系识别器和数据生成器对偶约束 , 从识别过程中学习如何生成任务相关的新数据 , 从生成过程中学习如何更准确地理解因果语义 , 生成高质量表达事件因果语义的新训练数据 。
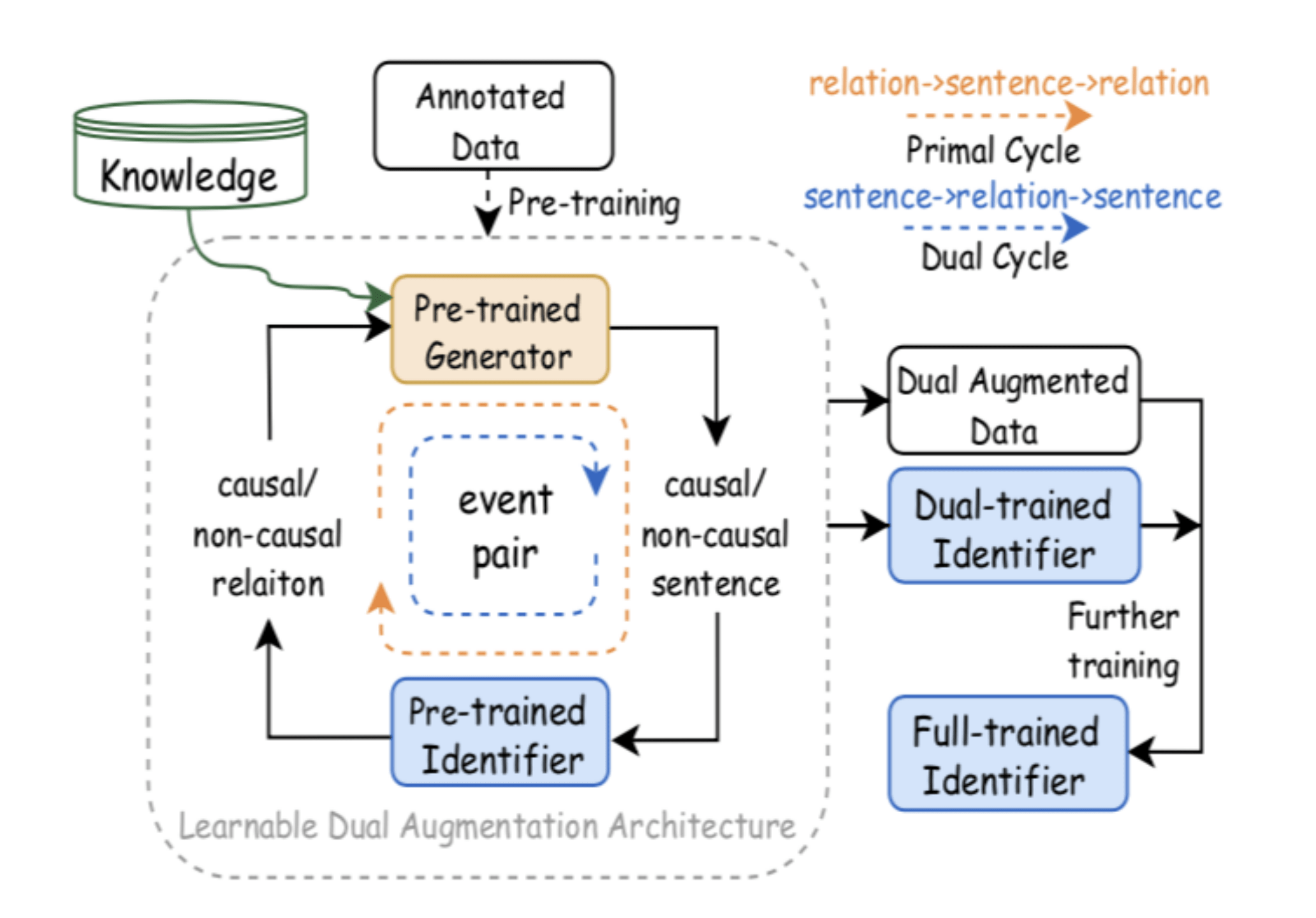
文章图片
13、基于隐含结构推理网络的事件因果关系识别
Knowledge-Enriched Event Causality Identification via Latent Structure Induction Networks
传统的事件关系抽取方法仅利用文本语义推断事件关系 , 忽略了背景知识 。 很多情况下仅仅利用文本语义很难判断出事件之间的关系 。 如何在复杂的真实应用场景中 , 同时利用文本和知识联合推断事件关系 , 是迫切亟待需要解决的问题 。
知识图谱中除了包含事件的描述性知识 , 还包含事件之间的关联知识 , 这类知识对预测事件因果关系非常有帮助 。 本文采用基于隐含结构归纳网络和事件关联知识的事件因果关系抽取 。 首先 , 从知识图谱中获得事件之间的关联知识 , 在知识图谱中 , 事件之间的关联知识一般由一条多跳路径组成 , 由于路径上有很多与因果无关的知识 , 并且由于知识图谱的不完备性 , 很多有用的知识没有标注出来 , 因此直接使用多跳路径进行因果推理并不是最优的 。 为了降低因果无关知识的影响以及捕获潜在的有用的知识 , 我们提出一个隐含结构归纳网络 , 能够基于事件之间的关联知识自动地学出一个最优的推理结构 。 基于归纳出的推理结构 , 我们执行因果关系推理 , 从而预测出事件的因果关系 。
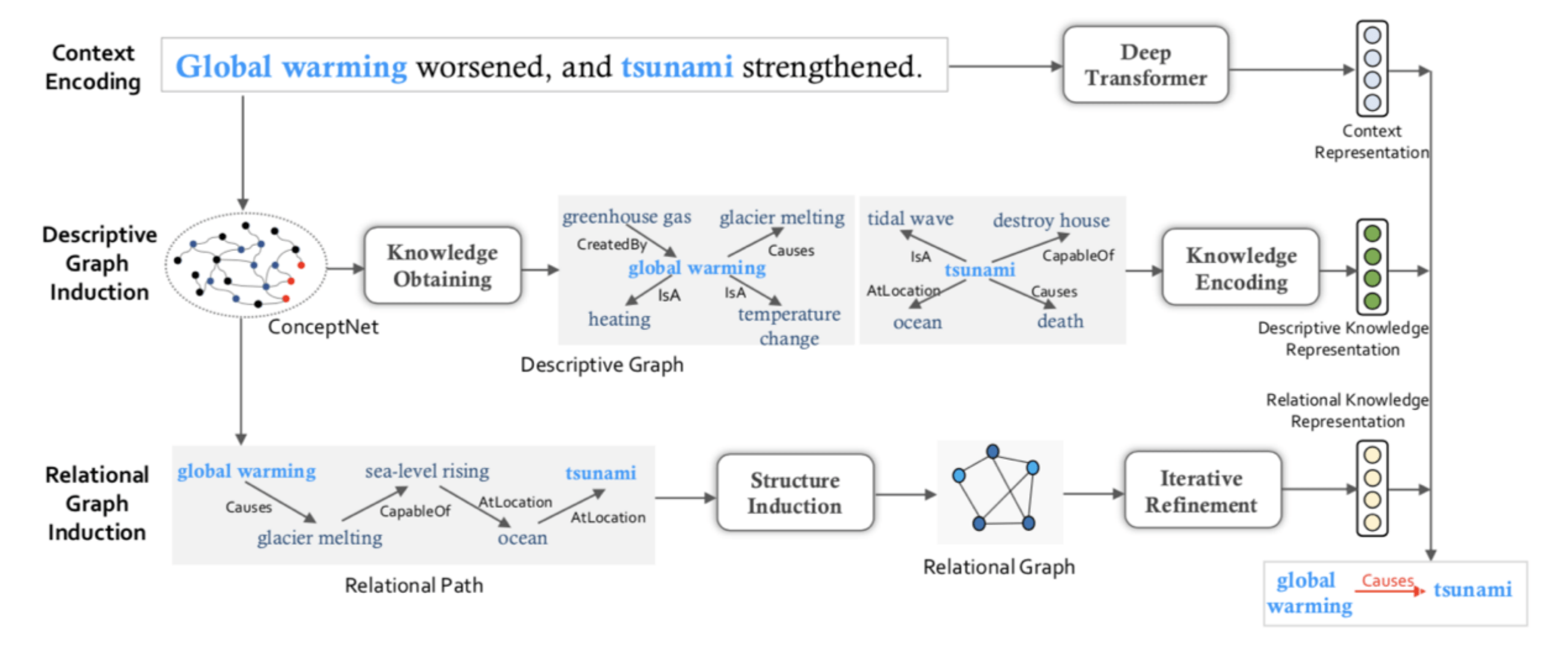
文章图片
14、基于外部因果陈述自监督表示学习的事件因果关系识别
Improving Event Causality Identification via Self-Supervised Representation Learning on External Causal Statement
利用外部大量的因果陈述 , 提升模型对因果关系语义的理解能力 , 这些因果陈述可以提供充足的上下文相关因果模式 , 有助于理解文本中事件的因果关系 。 然而 , 与ECI任务的标注数据不同 , 外部因果陈述中没有标注事件 , 模型很难直接从中学习上下文相关的因果模式帮助识别事件因果关系 。 为了解决这个问题 , 我们设计了一个基于自监督表示学习的事件因果关系识别模型 (Self-Supervised Representation Learning on External Causal Statement, CauSeRL) , 从外部因果陈述中学习强化的因果表示 。 具体来说 , 从外部因果陈述中迭代抽样两个实例 , 分别以其中一个因果陈述为目标 , 学习它们之间的共性 。 直觉上 , 通过自监督学习到的不同因果陈述间的共性反映了文本中上下文相关的因果模式 , 有助于在未见的实例中识别事件的因果关系 。
在基准数据集上的实验结果表明 , 该方法可以有效增强事件因果关系的表示、提升事件因果关系识别的性能 , 证明了我们的方法对于ECI任务的有效性 。
【GitHub|NLP领域国际顶会ACL 2021收录结果公布 百度14篇论文上榜】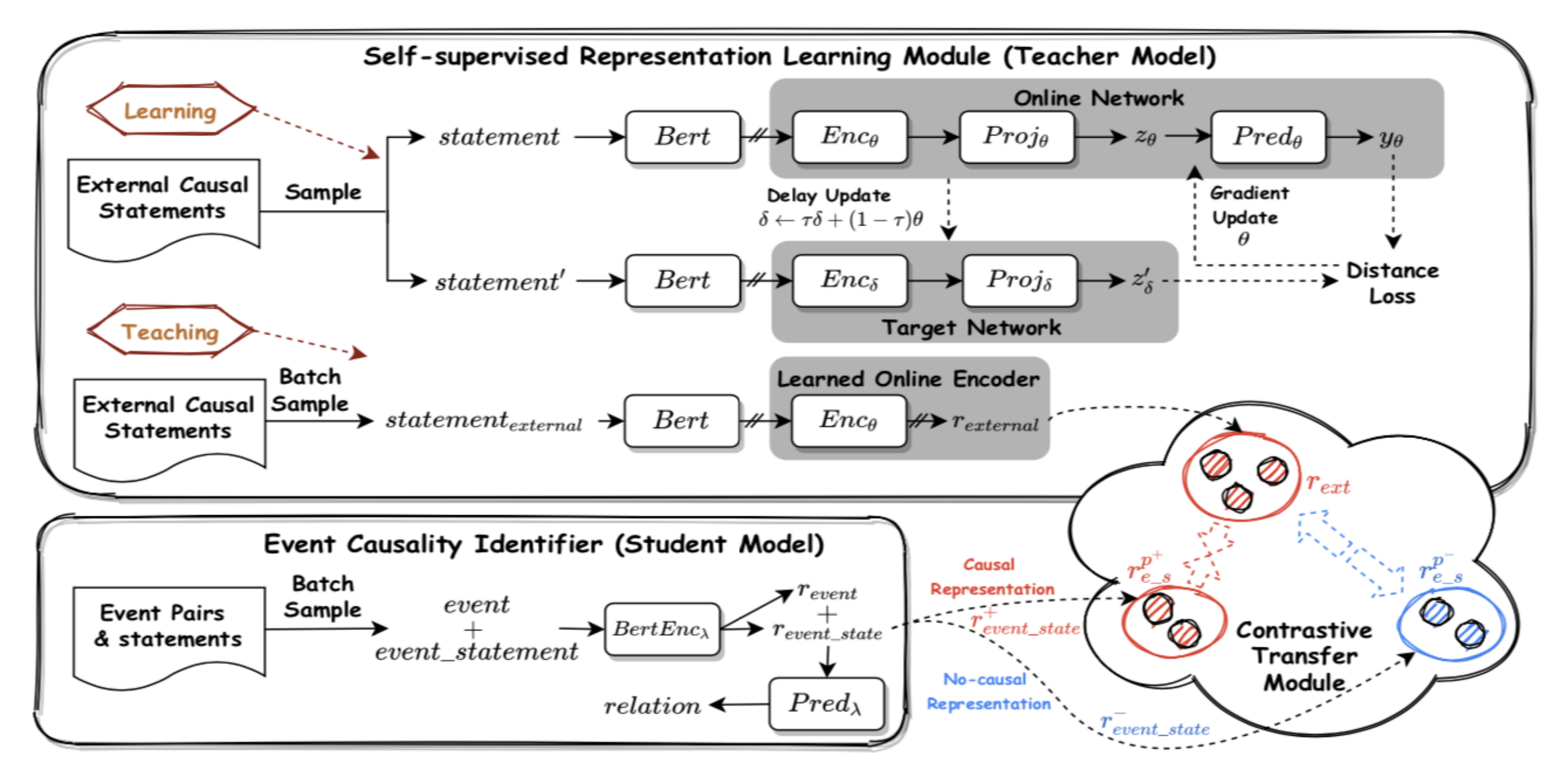
文章图片
推荐阅读







- 文章|美媒文章:古人类领域2021年六大新突破
- 器件|6G、量子计算、元宇宙…上海市“十四五”聚焦这些前沿领域
- 领域|上海市电子信息产业“十四五”规划:以集成电路为核心先导
- 前瞻|6G、量子计算、元宇宙……上海市“十四五”聚焦这些前沿新兴领域
- 产品|数梦工场通过CMMI V2.0 L5评估,再获全球软件领域最高级别认证加冕
- 电磁场|首届全国颠覆性技术创新大赛领域赛(青岛)举办
- 国际主流|“妈祖”填补我国海洋环流数值预报领域空白
- 量子|百度量子平台2.0重磅发布!推动构建量子计算领域繁荣生态
- GitHub|小米 12 / Pro / X 系列内核源码已公开,基于 Android 12
- 探测|国内电力气象领域首个“院士工作站”落户上海