机器之心专栏
作者:钱利华
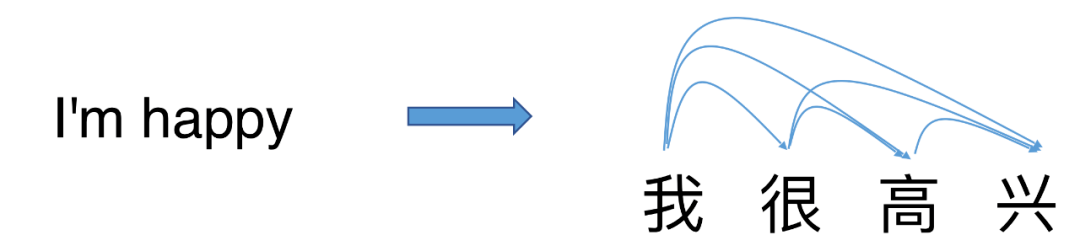
本文提出了一种为单步并行生成进行词之间依赖关系建模的方法 。 基于该方法的模型GLAT在不久前的国际机器翻译大赛(WMT2021)上击败一众自回归翻译系统 , 夺得了德语到英语方向机器翻译自动评估第一 。目前机器翻译中常用的神经网络模型(例如 Transformer, LSTM)基本上都是自回归模型(Autoregressive models) 。 自回归模型在输出句子时是逐词按顺序生成的 , 每一个输出的词都依赖于之前的输出词 。
文章图片
虽然自回归模型被广泛应用并取得了不错的效果 , 但是自回归模型要求每一步输出都需要按顺序等待前面位置的输出 。 因此 , 按顺序生成的方式会阻碍自回归模型充分利用并行计算 , 当输出文本较长或者模型比较复杂的时候导致机器翻译的速度很慢 。
因此 , 为了充分利用并行计算资源来加速生成 , 学术界提出了非自回归(Non-autoregressive)的机器翻译模型[1] 。 非自回归模型去除了每一个输出依赖于前面部分输出的限制 , 假定不同位置之间的输出是条件独立的(即每一个输出的具体值与其他位置的输出具体取值无关) , 使得模型可以并行输出文本 。 得益于并行输出的方式 , 非自回归模型可以更充分地利用并行计算来加快生成的速度 。

文章图片
虽然在生成速度上存在优势 , 但是之前的非自回归模型的翻译质量和自回归模型还存在显著差距 。 翻译质量差距的存在主要是因为如果并行输出语句 , 任何词在输出之间都无法确定语句中其它的词 , 难以有效利用词之间的依赖关系组成连贯的语句 。 为了在并行生成中建模并利用词之间的依赖关系 , 一些工作提出进行多轮并行输出来迭代修改语句[2,3,4] 。 虽然多轮迭代提升了输出语句的质量 , 但同时也减慢了生成的速度 。
那么是否有可能只进行一次并行的输出就得到质量不错的语句呢?
这里为大家介绍一篇 ACL2021 的研究非自回归机器翻译的工作《Glancing Transformer for Non-autoregressive neural machine translation》[5] ,作者来自字节跳动人工智能实验室 , 上海交通大学和南京大学 。
该工作提出了一种为单步并行生成方式进行词之间依赖关系建模的方法 。 在不久前的国际机器翻译大赛(WMT2021)上 ,GLAT 击败一众自回归翻译系统 , 夺得了德语到英语方向机器翻译自动评估第一 。

文章图片
- 论文地址:https://arxiv.org/abs/2008.07905
- 代码地址:https://github.com/FLC777/GLAT
自回归模型中最为常用的训练方式是最大似然估计(MLE) , 不少非自回归模型也直接使用 MLE 进行训练 。 但是非自回归模型的输出方式是并行的 , 输出语句中的任何部分在输出之前都无法获得输出语句中其余词的确切值 。 所以直接使用 MLE 训练并行输出的非自回归模型无法有效地建模输出语句中词之间的依赖关系 。 值得注意的是 , 词之间依赖关系的建模对输出通顺的语句至关重要 , 拥有良好生成质量的自回归模型和多轮迭代解码的模型均对这种依赖关系进行了有效的建模 。
直接训练完全并行生成来学习目标语句中词之间的依赖关系对模型并不友好 。 一种更为简单有效的依赖关系学习方式是根据部分输入词预测其余目标词 。 但是这种学习方式需要部分目标词作为输入 , 不符合非自回归模型并行生成的要求 。 作者观察到随着模型自身更好地学习到词之间的依赖关系 , 模型对于依赖关系的学习可以逐渐摆脱使用目标语句部分词作为输入的需求 。 基于以上观察 , Glancing Transformer(GLAT)利用了一种 glancing language model 的方法 , 通过渐进学习的方式进行词之间依赖关系的建模 。 在渐进学习的过程中 , 模型会先学习并行输出一些较为简单的语句片段 , 然后逐渐学习整句话的单步并行生成 。
文章图片
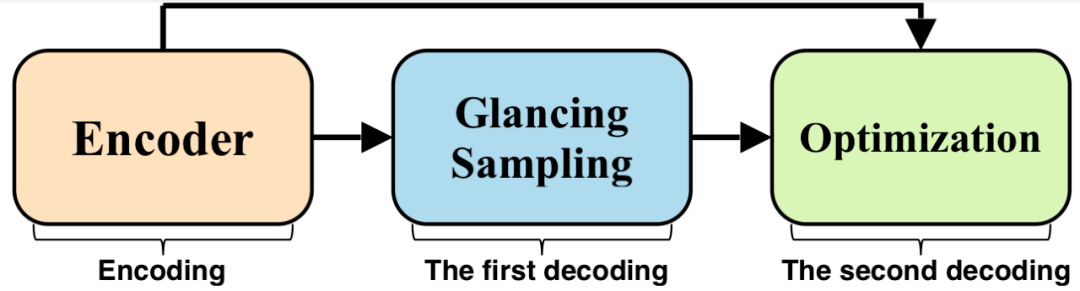
GLAT 在输出时和常规的非自回归模型保持一致 , 均只使用一次并行解码来输出语句 。 而在训练时 , GLAT 会进行两次解码:
(1)第一步解码 (Glancing Sampling) 主要根据模型的训练状况来估计模型需要看到的目标词的数量 , 然后采样相应数量的目标词并替换到解码器输入中 。
(2)第二步解码时 GLAT 会基于用目标词替换过后的解码器输入来让模型学习剩余词的输出 。 模型只在第二步解码时进行参数更新(Optimization) , 第一步解码仅输出语句 。
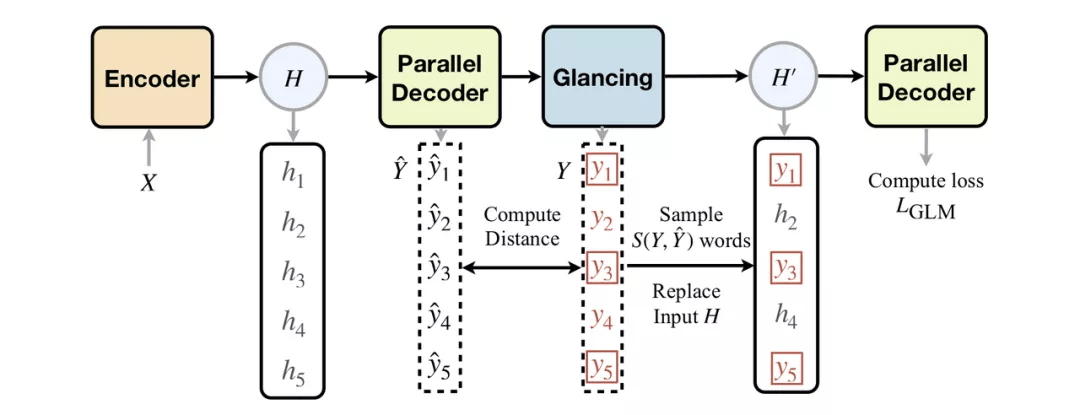
文章图片
具体地 , 在第一次解码的时候 , 和常规的非自回归模型一样 , 模型使用完全并行解码的方式输出语句 。 然后将第一次解码得到的输出和训练数据中的目标语句进行对比 。 如果输出和目标语句差距较大 , 说明模型在训练中难以拟合该训练样本 , 因此这时 GLAT 会选择提供更多目标词作为输入来帮助学习词之间依赖关系 。 反之 , 如果输出和目标语句比较接近 , 则模型自身已经较好地学习了如何并行生成该目标语句 , 所需要的目标词数量也相应减少 。
【输出|ACL 2021 | 字节跳动Glancing Transformer:惊鸿一瞥的并行生成模型】在第二步解码之前 , 模型的解码器可以得到部分目标词作为输入 , 这些词的数量由第一步的解码结果所决定 。 这时 , 模型在并行输出之前可以获得部分目标词的确切值 , 所以在学习输出剩余目标词的过程中就可以对目标语句中词之间的依赖关系进行建模 。
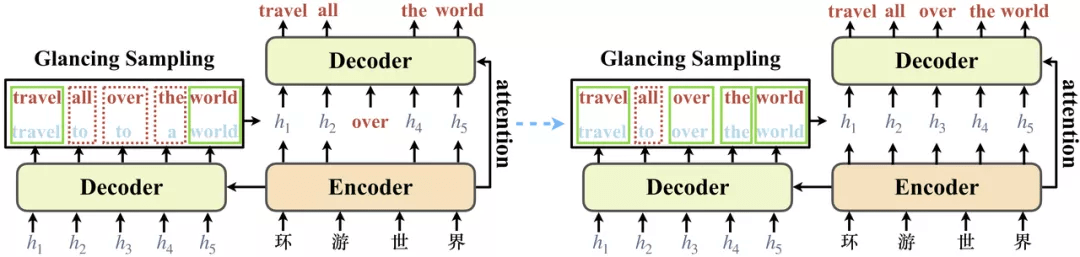
文章图片
上图给出了模型训练中的两个例子(注意模型只有一个 decoder , 在训练中进行了两次 decoding) 。 当模型还不能准确地生成目标语句时 , GLAT 会在目标语句中随机采样目标词作为解码器输入 。 例如上图左边的例子中 , 模型的翻译结果是 “travel to to a world” 。 GLAT 将该结果和目标语句“travel all over the world” 进行对比 , 发现当前结果较差 , 仅有两个词和目标语句相同 。 因此 GLAT 随机采样了词 “over” , 并把“over” 的词向量替换到相应位置的解码器输入中 。
随着训练的进行 , 模型对数据拟合程度更高 , 因此能够更准确地生成目标语句 。 与此同时 , 需要作为解码器输入的目标语句中的词的数量会越来越少 , 在训练后期逐渐接近学习完全并行生成的训练场景(例如上图右边的例子) 。 具体的方法细节和实现方式可以参考论文 。
效果分析
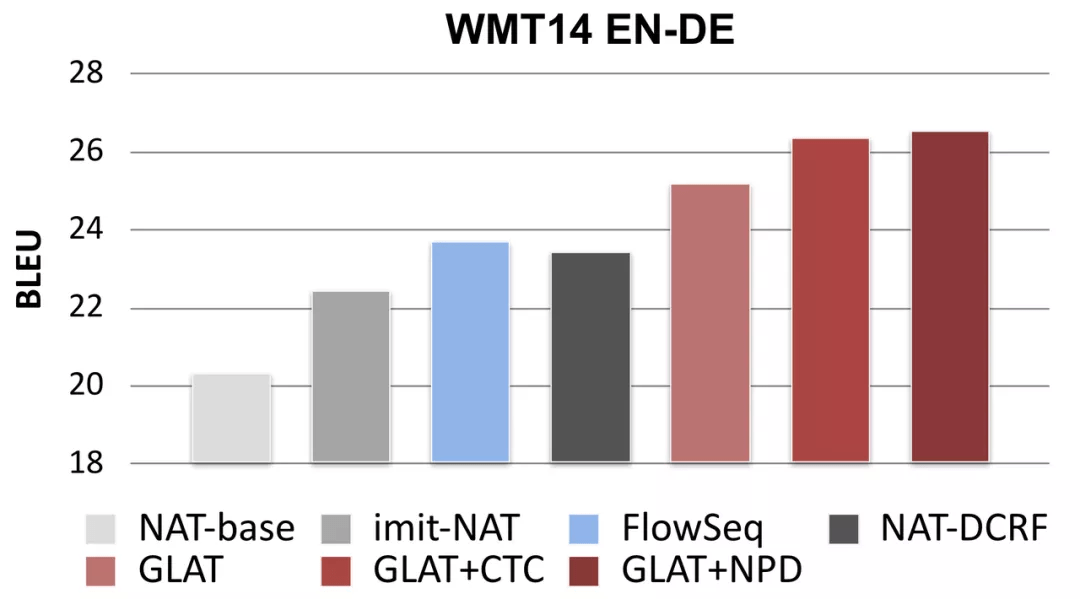
GLAT 在保持高效生成速度的同时显著提升了单步并行输出的翻译质量
文章图片
在多个翻译语向上 , GLAT 均取得了显著提升并超越了之前的单步并行生成模型 。 结合 reranking 和 CTC 等技术之后 , GLAT 可以只使用单步并行生成就达到接近自回归 Transformer 的翻译质量 。 由于 GLAT 只修改训练过程 , 在翻译时只进行单步并行生成 , 因此保持了高效的生成速度 。
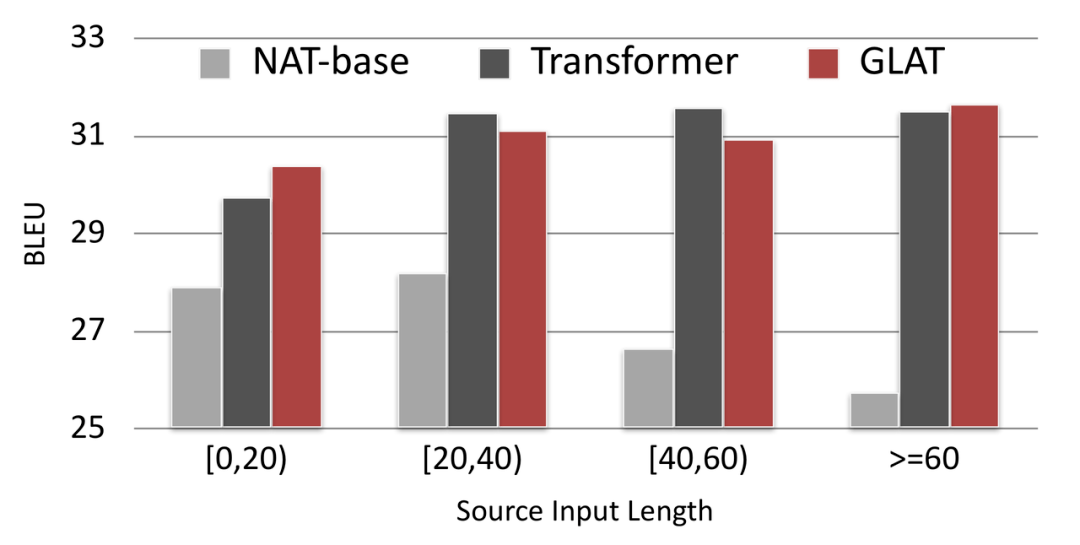
GLAT 提升了非自回归模型在长句上的翻译质量
文章图片
通过对比不同输入长度下的翻译质量 , 我们发现相比于常规的 NAT 模型(NAT-base) , GLAT 显著提升了在长句上的表现 。 除此之外 , 我们还发现在输入长度较短时 , GLAT 的效果甚至略优于自回归的 Transformer 模型(AT) 。
案例分析

文章图片
GLAT 和自回归的 Transformer 在翻译结果上各有优劣 。 通过案例分析 , 我们可以发现 Transformer 在翻译时可能会产生部分漏翻的情况 , 而 GLAT 在语序调整上不如 Transformer.
总结
该工作提出了 Glancing Language Model(GLM) , 一种为单步并行生成方式建模词之间依赖关系的方法 。 在多个数据集上的实验显示使用了 GLM 的模型——GLAT 可以大幅提升并行生成的质量 , 并且仅使用一次并行输出就可以达到接近自回归模型的效果 。 GLAT 已经在火山翻译的部分语向上线 。 此外 , 基于该技术的并行翻译模型在 WMT2021 比赛中的德英语向上取得了第一 。
[1] Jiatao Gu, James Bradbury, Caiming Xiong, Vic- tor O.K. Li, and Richard Socher. Non- autoregressive neural machine translation. ICLR 2018
[2] Jason Lee, Elman Mansimov, and Kyunghyun Cho. Deterministic non-autoregressive neural sequence modeling by iterative refinement. EMNLP 2018
[3] Marjan Ghazvininejad, Omer Levy, Yinhan Liu, and Luke Zettlemoyer. Mask-predict: Parallel de- coding of conditional masked language models. EMNLP-IJCNLP 2019
[4] Jiatao Gu, Changhan Wang, and Junbo Zhao. Levenshtein transformer. NeurIPS 2019
[5]Lihua Qian, Hao Zhou, Yu Bao, Mingxuan Wang, Lin Qiu, Weinan Zhang, Yong Yu, and Lei Li. Glancing transformer for non-autoregressive neural machine translation. arXiv preprint arXiv:2008.07905 (2020).
推荐阅读





- Google|谷歌暂缓2021年12月更新推送 调查Pixel 6遇到的掉线断连问题
- 精度|将建模速率提升10倍,消费级3D扫描仪Magic Swift在2021高交会大显“身手”
- 四平|智慧城市“奥斯卡”揭晓!祝贺柯桥客户荣获2021世界智慧城市治理大奖
- 系列|2021中国航天发射圆满收官!年发射55次居世界第一
- 项目|常德市二中2021青少年科技创新大赛再获佳绩
- 选型|数据架构选型必读:2021上半年数据库产品技术解析
- 殊荣|蝉联殊荣!数梦工场荣获DAMA2021数据治理三项大奖
- 公司|外媒:2021,人类太空事业的重大年份
- 语境|B站2021个人年度报告发布:你共计看了多少个视频
- 最新消息|IT系统出错 英国银行给7.5万人多发11亿工资