机器之心报道
编辑:杜伟、蛋酱
Rapper 要酝酿一整天的歌词 , AI 或许几分钟就能写出来 。给你一段 Rap , 你能看出这是 AI 写的吗?

文章图片
仔细品味 , 也能发现这段词中的美中不足之处 , 但这作词水平可以说是不错的 。
同样的第一句 , 可以迅速生成完全不同的段落:

文章图片
人类Rapper的双押 , 还是更厉害一点:

文章图片

文章图片
只需要给定一句输入 , AI 就能生成整首歌词 。 从押韵、流畅度、节奏方面 , 基本不逊于人类 Rapper 。
这项研究来自港科大、清华、复旦等机构 , 在这篇论文中 , 研究者提出了一个基于 Transformer 的 Rap 生成系统「DeepRapper」 , 该系统可以同时模拟 Rap 的韵律和节奏 。

文章图片
论文链接:https://arxiv.org/pdf/2107.01875.pdf
由于没有现成可用的节奏对齐的 Rap 数据集 , 为了构建这个系统 , 研究者设计了一个数据挖掘 pipeline , 并收集了一个大规模的 Rap 数据集进行韵律建模 。
一开始 , 研究者先从网上抓取了许多包含歌词和音频的说唱歌曲 , 并对每一首抓取的说唱歌曲进行一系列数据预处理步骤 。 为了更好地建模 , 研究者以自回归的方式从右到左生成每一句 Rap , 这样就可以很容易地识别出一个句子的最后几个单词 (即反向句子的第一个单词) 来押韵 。
此外 , 为了进一步提高 Rap 的押韵质量 , 研究者在语言模型中加入了一些押韵表征 , 并在推理过程中通过押韵约束来提高生成的 Rap 中的 N-gram 韵律 。
研究者使用一个特殊的标记 [ BEAT ] 来表示有节奏的节拍 , 并将其插入到相应的词之前的歌词中 。 通过这种方式 , 可以在训练和生成方面按照歌词的顺序来模拟节拍 。
受到预训练语言模型的成功启发 , 研究者将预训练纳入系统 。 为了获得大规模的预训练数据 , 研究者还使用了数据挖掘 pipeline 收集了另外两个数据集:
1)节拍对齐的非说唱歌曲 , 它可以比说唱数据集更大 , 因为非说唱歌曲比说唱歌曲更通用; 2)纯歌词 , 同样比非说唱歌曲数据集更大 。
在预训练阶段 , 研究者基于上述两个数据集对 DeepRapper 模型进行了预训练 , 然后调整模型在说唱歌曲与调整节拍上的性能 , 微调模型即用于最终的说唱产生 。 客观评估和主观评估的实验结果都证实了 DeepRapper 在生成押韵和节奏的说唱歌词方面的优势 。
【模型|AI都会写灵魂Rap了?Transformer跨界说唱,节奏流畅度都不在话下】Rap 数据集
以前用于 rap 生成的作品(Potash 等人 , 2015 年;Liang 等人 , 2018 年;Nikolov 等人 , 2020 年)通常使用只有歌词的说唱数据集 , 而不考虑节奏节拍信息 。 为了在 rap 生成中建模节奏 , 说唱数据集应该包含具有对齐节奏节拍的歌词 。 然而 , 节拍对齐很难实现 , 因为它们的注释需要专业音乐家来识别说唱歌曲中的重读音节 。
因此 , 为了解决这个问题 , 研究者设计了一个数据挖掘 pipeline 来自动提取 beatlyric 对齐 。
数据挖掘 pipeline
下图 1 展示了数据挖掘 pipeline 的整体框架 , 包含 5 个步骤:数据抓取、人声(vocal)与伴奏分离、人声与歌词对齐、节拍检测以及歌词与节拍对齐 。

文章图片
挖掘数据集
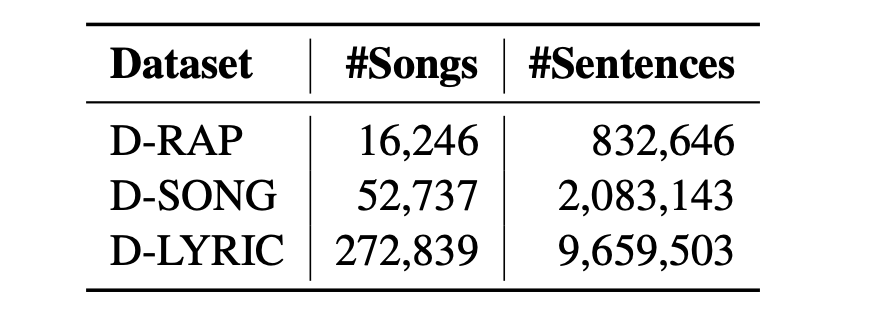
基于上图数据挖掘 pipeline , 研究者得到了一个具有对齐节拍的说唱歌词(rap lyric)数据集 , 并命名为 D-RAP 。 该数据集满足了构建具有韵律和节奏的 rap 生成系统的要求 。 他们以 4:1 的比例将 D-RAP 数据集划分为训练和验证集 。
与一般歌曲相比 , 说唱风格的歌曲数量往往较少 , 因此研究者挖掘了另外两个数据集 , 以使用相同的挖掘 pipeline 对 DeepRapper 模型进行预训练 , 它们分别是具有对齐节拍的非说唱歌曲数据集 D-SONG 和没有对齐节拍的纯歌词数据集 D-LYRIC 。
研究者在下表 1 中对这三个数据集包含的歌曲数量和歌词句子数量进行了统计 。
文章图片
下图 2 展示了 D-RAP 数据集中具有对齐节拍的说唱歌曲示例 。

文章图片
Rap 生成模型
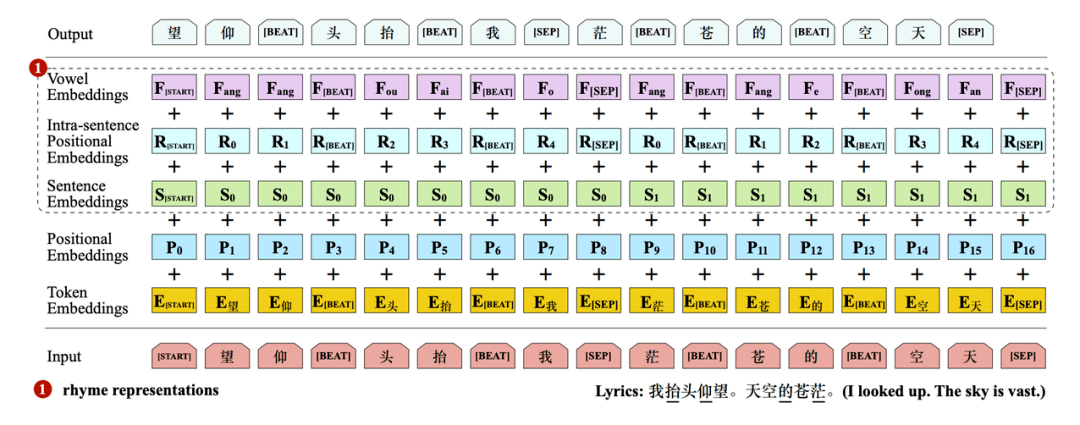
如下图 3 所示 , 研究者展示了 rap 生成模型的整体架构以及韵律和节奏建模的细节 。
具体地 , 研究者使用 Transformer 构建了一个用于 rap 生成的自回归语言模型 , 并引入了以下一些新的对齐:
1)为了更好地建模韵律 , 该模型从左到右生成歌词句子 , 这是因为押韵字通常位于句子结尾;
2)如前所述 , 节奏对于 rap 效果至关重要 , 因而插入了一个特殊的 token [BEAT]来进行显式节拍建模;
3)与仅有词嵌入和位置嵌入的原始 Transformer 不同 , 研究者添加了多个额外嵌入以更好地建模韵律和节奏 。
文章图片
实验评估
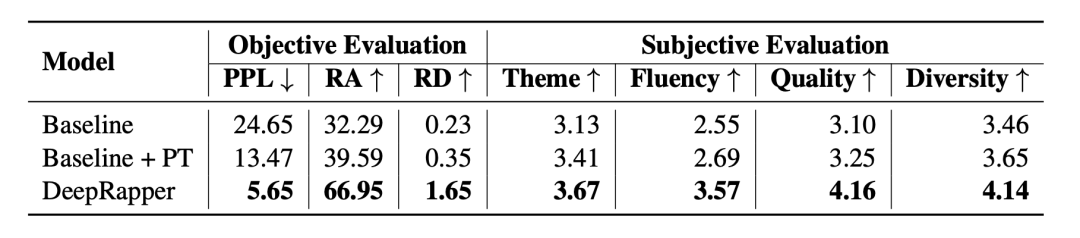
下表 2 展示了 DeepRapper 的客观与主观评估结果 , 并与两个 baseline 进行了比较 。 Baseline 模型是一个标准的自回归语言模型 , 与 DeepRapper 的模型配置相同 , 但没有本文提出的韵律模型(+PT 的意思是采用了预训练) 。 客观评估结果的维度包括 perplexity、韵律准确性和韵密度;主观评估维度包括主题、流畅度、押韵质量和押韵多样性 。
文章图片
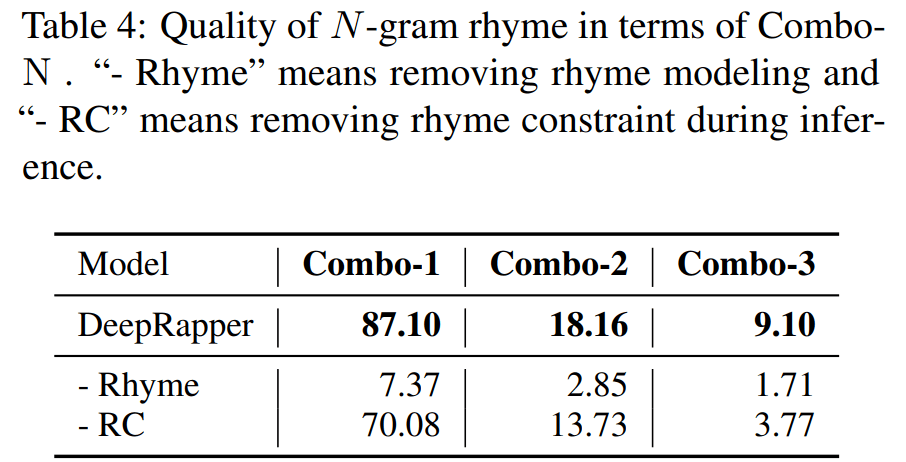
为了突出 DeepRapper 在建模 N-gram 韵律中的优势 , 研究者使用 Combo-N 来度量 DeepRapper 中每个设计建模 N-gram 韵律的能力 。 结果如下表 4 所示:
文章图片
为了更好地度量节拍质量 , 研究者分别使用 DeepRapper 和具有节拍频率控制的 DeepRapper 随机生成了大约 5000 个样本 。 他们提出了一阶分布(First Order Distribution, FOD)和二阶分布(Second Order Distribution, SOD) , 并度量了生成样本与 DRAP 数据集之间分布的距离 。
研究者将当前 [BEAT] 的间隔定义为当前 [BEAT] 与下个 [BEAT] 之间的歌词数量 。 因此 , FOD 被定义为当前 [BEAT]间隔的分布 , SOD 被定义为当前 [BEAT]与下个 [BEAT]之间间隔差的分布 。 间隔的数值区间为[0, 1] , 具体结果如下表 5 所示:
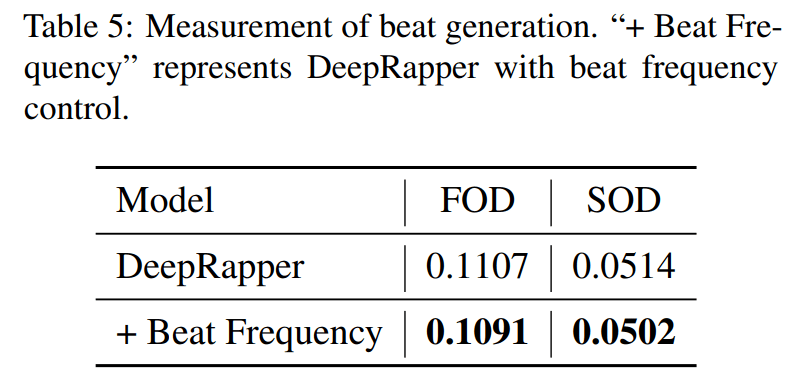
文章图片
下图 6 中 , 研究者展示了生成的 rap 歌曲示例 , 可以看出 DeepRapper 的生成效果还不错 。

文章图片
推荐阅读







- 市场|因时乘势 奋进启航|写给2022年的一封信
- 协同|网文论︱网络文学与AI写作:人机协同演化时代的文学之灵
- Xiaomi|小米一款折叠式智能手机专利申请曝光 配备磁吸式手写笔
- 手机|新一代 MIX FOLD?小米申请折叠屏手机外观专利,支持手写笔
- 模型|2022前展望大模型的未来,周志华、唐杰、杨红霞这些大咖怎么看?
- 诺克比|爱德华·威尔逊写小说:把“蚂蚁社会”作为人类的一个隐喻
- 韦贝尔|爱德华·威尔逊写小说:把“蚂蚁社会”作为人类的一个隐喻
- 模型|经逆向工程,Transformer「翻译」成数学框架 | 25位学者撰文
- 化纤|JXK STUDIO 虎年肥猫 1/6仿真动物模型手办可爱摆件
- 模型|达摩院2022十大科技趋势发布:人工智能将催生科研新范式