Jiangmen
From:Google ?编译:T.R
?3D物体的位置和朝向一直是计算机视觉领域的核心问题之一, 这一视觉任务 对于增强现实和机器人操控等方面具有不可或缺的作用 。 先前的诸多研究 为这一问题提供了可能的解决方案 , 但是对于透明物体则会失效 。 为了解决透明物体的深度估计问题 , 像ClearGrasp等算法尝试利用深度神经网络来补全由透明物体造成缺失的深度图 , 但是这种方法也存在缺 陷 。
为了解决这一问题 , 研究人员提出了一种名为KeyPose的算法 , 基于多视角标注和关键点估计为透明物体的三维位姿估计提供了有效的手段 。 这种方法可以通过预测透明物体的3D关键点来直接获取其深度信息 。
3D物体的位置和朝向一直是计算机视觉领域的核心问题之一 , 这一涉及目标级别感知的视觉任务对于增强现实和机器人操控等方面具有不可或缺的作用 , 在这些应用中获取目标的3D位姿至关重要 。 只有准确获取位姿才能对目标进行控制、或是在其周围放置虚拟物体 。
先前有众多研究 , 包括机器学习的方法为这一问题提供了可能的解决方案 , 例如Deep Nets利用了像Kinect一类具有深度传感器的信息 , 直接测量出与目标物体的距离 。 但针对透明或者反射物体来说 , 直接深度感知在一定程度上就会失效 , 例如下图中的透明物体深度相机就无法获取他们的测量值 , 同时三维重建的结果也很难令人满意 。

文章图片
左图显示了透明物体的RGB图像 , 右图显示了重建后的深度以及点云 。 透明杯子无法被有效测量 , 同时重建的深度值也出现了较大误差 。
为了解决透明物体的深度估计问题 , 像 ClearGrasp等算法尝试 利用深度神经网络来补全由透明物体造成缺失的深度图 。 这种算法利用深度网络从给定的RGB-D图中估计出表面法向量、透明物体的掩膜以及遮挡边界 , 随后利用它们去优化所有透明物体表面的初始边界 。 这种方法可以使得场景中的透明物体通过 后处理的方式解决 , 但补全算法有自己的限制 , 特别是当网络完全在合成数据集上训练的时 , 对于透明物体的深度补全会产生较大的误差 。
为了解决这一问题 , 研究人员提出了一种名为 KeyPose的算法 , 基于多视角标注和关键点估计为透明物体的三维位姿估计提供了有效的手段 。 这种方法可以 通过预测透明物体的3D关键点来直接获取其深度信息 。
为了训练这一系统 , 研究人员还构建了一个 大型的真实世界透明物体数据集 , 利用手工筛选关键点的方式半自动的实现了高效的标注 。 KeyPose在训练过程中直接将单目或者双目图像作为输入 , 而不会显式地计算深度 。 这一方法可以实现高水平的位姿估计效果 , 并将深度估计的典型误差控制在了5-10mm范围内 。
基于3D关键点标签的真实世界透明目标数据集
研究人员利用机器人辅助的半自动手段进行数据采集 , 提高数据集的构建效率 。 实验中使用的是Kinect Azure深度相机与双目相机 , 同时机器人在沿着给定轨迹运行时不断相机的拍摄结果 , 数据采集过程如下图所示 。

文章图片
基于机械臂的自动化图像序列采集装置
在图中可以看到 , 研究人员使用了AprilTags来精确地追踪相机在拍摄过程中的位姿 。 人们只需要手工标注每一段视频中很少一部分图像中的2D关键点 , 就可以基于多视图几何从视频中的所有帧里抽取出3D关键点的信息 , 以百倍的量级提升了数据集的构建效率 。
文章图片
数据集构建流程
研究人员一共在十种不同背景下、捕捉了五类共计十五个不同的物体图像 , 共得到了600个视频序列和48k的立体和深度图像 。 同时研究人员还捕捉了相同物体的不透明版本 , 为深度估计提供了基准信息 , 所有的图像都利用了3D位姿点进行标注 。 作为ClearGrasp中合成数据的有力补充 , 研究人员已经将这一数据集公开 。

文章图片
采集到的数据集
【物体|谷歌提出位姿估计新算法KeyPose, 基于立体视觉有效估计透明物体的3D位姿】基于早期融合的KeyPose算法
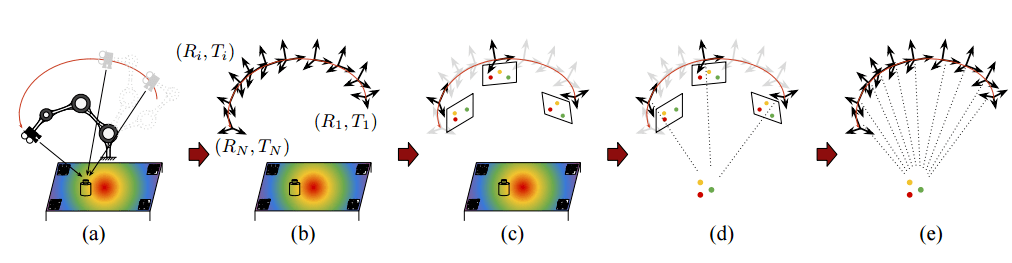
为了直接利用立体图像估计出关键点 , 研究人员提出了下图所示的算法流程 。 来自双目的图像被裁剪并送入KeyPose网络中 , 随后预测出稀疏的三维关键点集来代表目标的3D位姿 。
这一网络模型的关键在于KeyPose使用了早期融合的方法来对立体视觉图像进行处理 , 使得网络可以隐式的计算双目时差 。 而与早期融合不同的是 , 晚期融合算法则独立地预测每一幅图像的关键点而后进行融合 。 实验表明早期融合的方法可以取得相较于晚期融合方法两倍的精度提升 。 下图中的热力图展示了每个关键点对应的视差热力图 , 这些热力图的融合实现了对于关键点的有效估计 。

文章图片
KeyPose系统流程图 , 立体图像首先传入模型得到每个关键点概率性的热力图 , 这些在UV坐标系下的热力图与网络生成的视差热力图相融合得到了关键点的三维坐标(X,Y,Z)
实验结果
下图显示了KeyPose针对当个物体所获取的实验结果 , 左图是原始的立体图像之一、中间是预测出的三维关键点投影到二维图像中的结果 , 右侧是瓶子3D模型的可视化 , 利用3D关键点信息将模型置于图中的对应位置 。 模型的精度与5~10mm, 其中针对瓶子实现了MAE为5.2mm的关键点估计精度 , 杯子的预测精度也达到了了10.1mm , 在标准GPU(Titan V+i7)上运行仅仅需要5ms 。
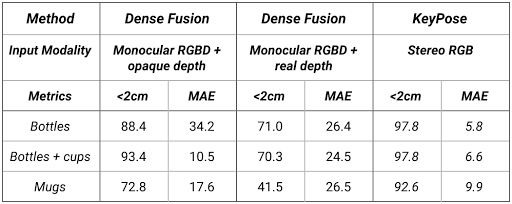
下表展示了不同类别的估计精度 , 值得一提的是在测试过程中背景也是训练过程中未知的 , 可以显示出模型针对处于不同环境中透明物体关键点估计的泛化性 。
文章图片
与DenseFusion的定量比较 , 其中<2mm指的是结果中误差小于2mm所占的百分比 , 其中还对比了DenseFusion在不透明物体下的表现 。 实验表明 , KeyPose针对透明物体的估计结果都要优于DenseFusion处理不透明物体的性能 。
这一工作展示了在无需深度图辅助的情况下可以实现 从RGB图像对透明物体进行三维位姿估计的可行性 , 同时也验证了早期融合架构对于双目视觉输入的有效性 。 在未来的研究中心 , 作者将继续推动自监督的方法来代替数据集构建过程中的手动标注 , 从而提升整个研究路线的效率 。 如果想要了解更多 , 请参看论文及其补充材料:
https://sites.google.com/view/keypose/
ref:
https://sites.google.com/view/keypose/
https://openaccess.thecvf.com/content_CVPR_2020/papers/Liu_KeyPose_Multi-View_3D_Labeling_and_Keypoint_Estimation_for_Transparent_Objects_CVPR_2020_paper.pdf
https://arxiv.org/pdf/1912.02805.pdf
推荐阅读







- Google|谷歌暂缓2021年12月更新推送 调查Pixel 6遇到的掉线断连问题
- 精度|将建模速率提升10倍,消费级3D扫描仪Magic Swift在2021高交会大显“身手”
- 识别|天津滨海机场RFID行李全流程跟踪系统完成建设 行李标签识别成功率可提升至99%
- the|美FDA将批准辉瑞为12-15岁儿童提供COVID-19加强针
- IT|美律所对法拉第未来提起集体诉讼 涉嫌触犯证券法
- Siamese|一个框架统一Siamese自监督学习,清华、商汤提出简洁、有效梯度形式,
- 产品|国内首家提供EMI解决方案及产品供应商签约,提供EMI IC、PMIC等产品
- Tesla|马斯克也要效仿谷歌Facebook 为特斯拉设立控股母公司?
- 中国|411 家游戏企业签署防沉迷公约,95% 游戏添加适龄提示
- 警告!|冒充老干妈员工诈骗腾讯被判12年 两被告提出上诉