Jiangmen
作者:麻省理工学院在读博士生 唐昊天、刘志健
?
ECCV 2020系列文章专题
收官之作
本文将分享来自 麻省理工学院在读博士生唐昊天和刘志健等人在 ECCV 2020的工作 。 文章关注的焦点是 如何自动设计用于自动驾驶的高效三维场景理解模型 , 并提出了一种新的三维点云计算模块稀疏点云-栅格卷积 (SPVConv) 和3D神经网络结构自动搜索 (3D-NAS) 。 本文中自动设计的模型SPVNAS在SemanticKITTI数据集上取得了当前最先进的性能 。
本文是ECCV 2020系列文章专题最后一篇啦!想看更多往期精彩内容 , 后台回复“ ECCV”即可查看~

文章图片
论文地址:
https://arxiv.org/pdf/2007.16100.pdf
代码链接:
https://github.com/mit-han-lab/e3d
项目主页:
https://spvnas.mit.edu
一、三维深度学习面临巨大内存和计算开销

文章图片
三维传感器技术的发展使得三维深度学习变得越发重要
在自动驾驶、AR/VR等应用愈加炙手可热的背景下 , 三维深度学习和激光雷达视觉受到越来越多的关注 。 研究人员往往采用基于栅格化的方法和直接处理点云的方法进行三维物体、场景理解 , 然而基于栅格的方法在高分辨率下面临巨大的计算和访存开销 , 而直接处理点云的方法则受限于不规则内存访问 , 因此很长一段时间内两种方法都十分低效 。
基于这样的观察 , 2019年末 , 麻省理工学院 (下称MIT) 韩松实验室 (HAN Lab)发表论文《用于高效3D深度学习的Point-Voxel CNN》 (Point-Voxel CNN for Efficient 3D Deep Learning) , 并提出新型点云处理框架 (Point-Voxel CNN , 下称PVCNN) , 将点云处理领域的两类思路: 基于栅格和 直接处理点云的方法进行了结合 。
PVCNN可以快速、高效地进行3D点云数据 , 与此同时还能避免稀疏性带来的巨大的不规则数据访存开销 , 提高硬件效率 。 这篇论文最终被人工智能顶会 NeurIPS 2019接收为 Spotlight论文 。
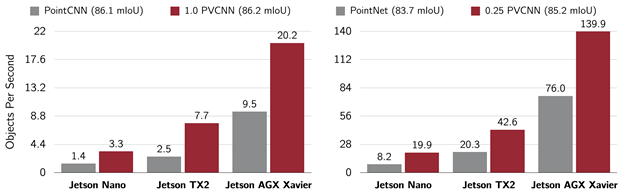
文章图片
PVCNN和传统的基于直接处理点云的方法在三维物体部件分割任务上的比较: PVCNN可以在端设备上以实时速度分割三维物体 。
虽然PVCNN在小物体和较小的区域理解中展现了强劲的性能 , 其在大规模室外场景上仍然无法高效部署 。
为解决这一问题 , 2020年8月下旬 , 韩松实验室在ECCV 2020发表新论文《搜索由稀疏点云-栅格卷积构成的高效3D架构》(Searching Efficient 3D Architectures with Sparse Point-Voxel Convolution) 。
二、大规模室外场景下的高效三维模块设计
在2019年提出PVCNN的基础上 , 本次论文首先提出了一种新的稀疏点云-栅格卷积 (Sparse Point-Voxel Convolution, 下称SPVConv) 。 这是一个高效、轻量的3D模块 , 解决了此前的PVConv难以高效处理极大规模室外场景的痛点 。
SPVConv改变了2019年论文中在栅格表示 (Volumetric Representation) 下聚合邻域信息的思路 , 转而在稀疏张量 (Sparse Tensor) 表示下利用三维稀疏卷积 (3D Sparse Convolution) 来处理邻点信息 。
这样 , 负责邻域聚合的稀疏卷积分支 (Sparse Convolution Branch) 的计算和内存访问复杂度均和场景本身的尺度无关 , 便解决了此前的PVCNN难以扩展到大规模场景的问题 。
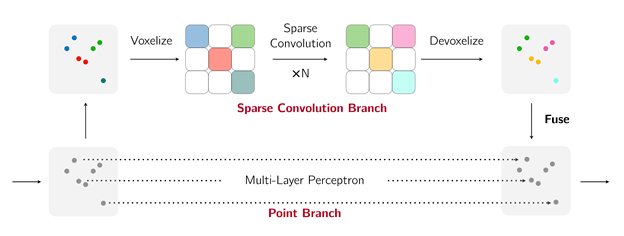
文章图片
SPVConv是专为大规模室外场景设计的高效3D处理模块
SPVConv中也保留了PVCNN中点云分支 (Point Branch) 的设计来高效建模室外场景中的小物体 , 例如行人和非机动车 。 能够准确、快速识别这些小物体对于自动驾驶模型的安全至关重要 , 而SPVConv中的点云分支正可以将它的注意力集中在这些小物体上:
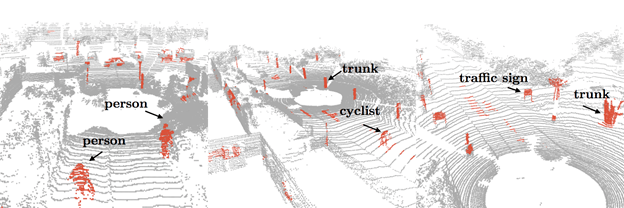
文章图片
SPVConv中的点云分支学到了将注意力集中在小物体上
值得一提的是 , 本文中的实验也发现稀疏卷积操作 (Sparse Convolution) 容易直接忽视场景中的这些小物体 。
【Sparse|ECCV 2020 | MIT提出自动设计SPVNAS模型】三、自动搜索由SPVConv构成的三维场景理解神经网络
在SPVConv带来的新的设计空间上 , 本文更通过3D神经网络结构搜索 (3D-NAS) 大幅优化了此前领域内最先进的稀疏卷积方法的计算效率及其在识别小物体上的能力 , 提速的同时提高准确率 。
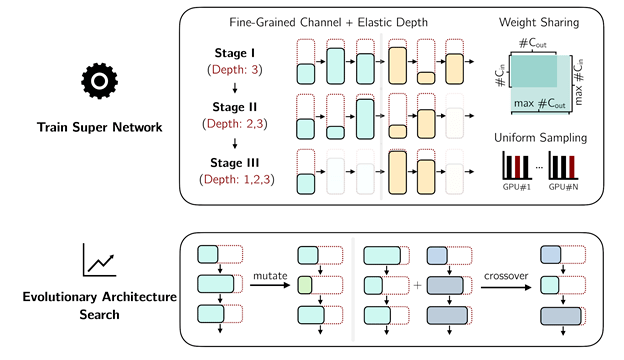
文章图片
3D-NAS的整体流程
本文中 , 3D-NAS将网络的设计流程分为两个阶段 , 以支持高效设计高效3D场景理解网络 。
在第一阶段中 , 作者提出训练一个包含设计空间中所有子网络的超网络结构 。 由于超网络的训练必须兼顾到大量结构迥异的子网络(数量可达10^40) , 作者提出使用分布式均匀采样 (Distributed Uniform Sampling) 和权值共享 (Weight Sharing) 来解决对于可变通道数子网络的支持 。 而对于更具挑战性的可变网络深度支持 , 作者则提出了深度渐进收缩 (Progressive Depth Shrinkage) 策略:他们将超网络的训练分为多段 , 每一段中都允许更大的子网络深度选择范围 , 这样在超网络训练结束之后便可以支持任意深度的子网络 。
第一阶段完成后 , 作者提出使用基于遗传算法的网络结构搜索 (Evolutionary Architecture Search) 。 得益于第一阶段中所有子网络均被训练 , 在网络结构搜索阶段只需直接在验证集上运行推理便可以得到用于指导搜索的模型精确度指标 , 而无需像一些传统的神经网络搜索算法那样对每个被采样的模型进行重新训练 。 作者发现 , 相比于EfficientNet或RegNet等方法中用到的GridSearch , 3D-NAS框架能够将模型的部署代价降低一个数量级以上 。
四、相关实验结果
此项工作是最早的在三维计算机视觉领域做神经网络结构自动搜索的工作之一 , 并且在极具挑战性的室外场景雷达点云语义分割任务上完胜该领域此前的设计 , 在自动驾驶的权威评测SemanticKITTI上 , 由3D-NAS设计的、SPVConv组成的SPVNAS模型位列单帧3D场景语义分割榜单的第一位 。
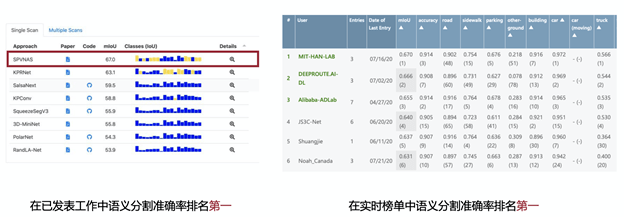
文章图片
SemanticKITTI排行榜
链接: http://www.semantic-kitti.org/tasks.html#semseg
在和MinkowskiNet的对比实验中 , SPVNAS在计算量和参数量上比前者减少接近8倍 , 在GTX1080Ti实测速度上优于前者将近3倍的情况下仍然达到更高的准确率 。 在测量特定数据集中检测相应物体准确度的标准IoU (Intersection over Union) 上 , SPVNAS在小物体上实现了最高达25%的IoU改进 , 也能够更好地分割马路上的边界 。
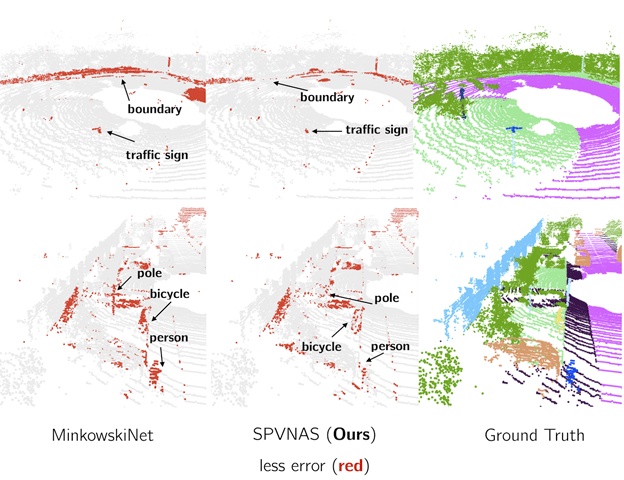
文章图片
相比MinkowskiNet , SPVNAS能减低小物体和边界区域上的分割误差
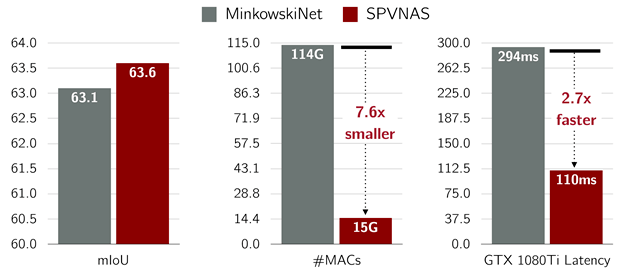
文章图片
SPVNAS的计算效率明显高于此前最先进的MinkowskiNet
此外 , 文中还进行了不同计算资源限制下的实验 。 可以发现 , SPVNAS取得的性能在所有计算量/延时限制下都远优于此前手动设计的模型 。 而且SPVNAS模型可以在GTX1080Ti显卡上达到接近雷达采集频率 (9 FPS) 的速度 , 远超此前最先进的MinkowskiNet(3 FPS) 。
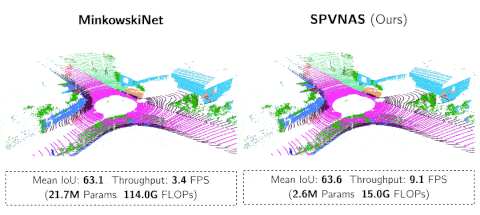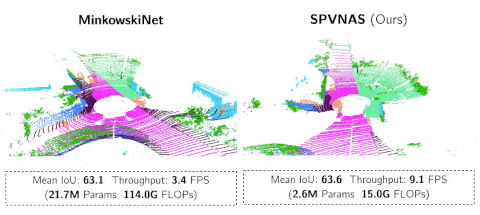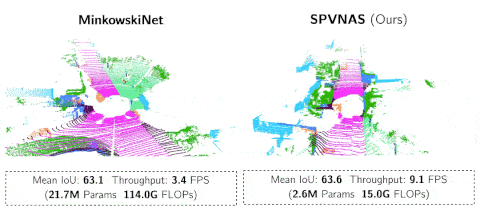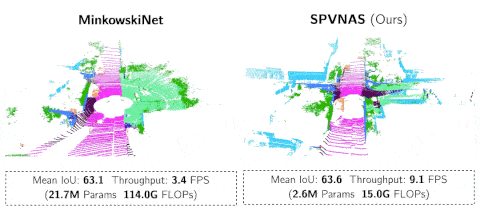
文章图片
SPVNAS 以 9.1 FPS的速度在NVIDIA GTX1080Ti上运行 , 远比MinkowskiNet更加高效
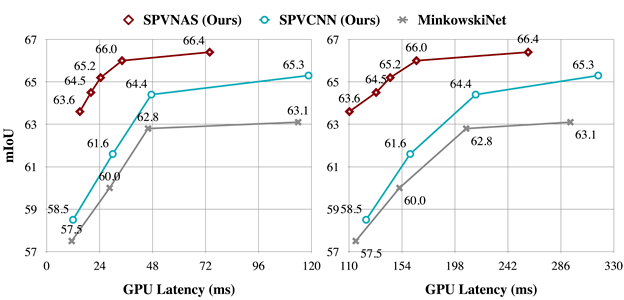
文章图片
SPVNAS在所有计算资源限制下均获得远超MinkowskiNet和手动设计的SPVCNN的性能
该实验室还设计了一组不具有解码器 (decoder) 的、更高效的SPVNAS模型 , 可以在达到在GTX1080TiGPU上超过10 FPS推理的同时 , 将此前具有相近速度的基于球面投影和2DCNN的方法的计算量和参数量降低一个数量级 , 准确率提升3.1% - 10.4% mIoU 。 值得一提的是 , 这组模型的精度也超过了此前另一最先进的直接基于点云的三维深度学习方法KPConv 。
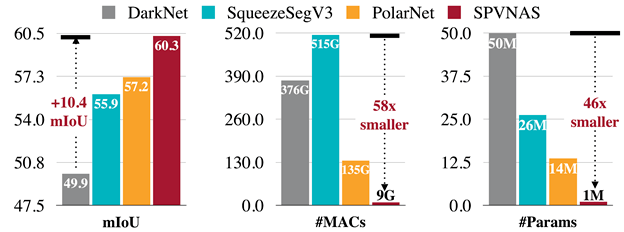
文章图片
SPVNAS的计算效率和性能都远优于基于2D投影的方法
代码开源
论文的相关实现已经在韩松实验室官方GitHub主页开源 。 关于SPVNAS的部分可以参考:
https://github.com/mit-han-lab/e3d
值得一提的是 , 本文中还提出了一个高度优化的3D稀疏计算库 , torchsparse , 该库的最新版本在运行标准的稀疏卷积网络时能相对于此前学术界最先进的开源库MinkowskiEngine获得1.9倍的加速 。 torchsparse亦设计了更友好的用户接口并能够直接支持韩松实验室ECCV 2020中提出的SPVConv操作 。 torchsparse源代码:
https://github.com/mit-han-lab/torchsparse
据悉 , 这项工作获得了麻省理工学院-IBM沃森人工智能实验室、赛灵思、ON Semi、三星以及AWS的支持 。 韩松实验室也希望借助该研究激励更多人研究轻量高效、硬件友好的深度学习 , 并在自动驾驶等现实场景落地 。
//
作者介绍:
唐昊天 , 麻省理工学院韩松实验室一年级博士生 , 此前于2020年7月从上海交通大学计算机科学与工程系获得学士学位 。 他目前的研究兴趣是用于高效三维理解的算法和计算机系统协同设计 。
个人主页:http://kentang.net
刘志健 , 麻省理工学院韩松实验室三年级博士生 , 此前于2018年从上海交通大学获得学士学位 , 2020年从麻省理工学院获得硕士学位 。 他的研究兴趣主要是高效和硬件友好的深度学习及其在三维计算机视觉中的应用 。
个人主页:http://zhijianliu.com
推荐阅读







- 平板|小新 Pad Pro 2020 平板开启 OTA7 ZUI 13 灰度推送
- 国际|2020年我国产出卓越科技论文46万余篇
- 排名|2020年我国国际顶尖期刊论文数量排名世界第二 上升2位
- 最新消息|印度创企2021年获360亿美元投资 比2020年增长2倍
- 未来|汾酒荣获2020年度中国食品工业协会科学技术奖两项殊荣
- the|美国疾控中心公布2020年十大死因:心脏病排名第一 癌症第二
- the|CDC:美国人均预期寿命在2020年缩短近2年
- 疫情|中科院报告:2020年中国共出版科普图书近亿册
- 期刊|中国首部科学传播报告:2020年出版科普图书9853.6万册
- 传播|2020年中国新建科普网站2732个