Jiangmen
编译: T.R From: Google
强化学习算法在过去几年中取得了巨大的成就 。 目前先进的强化学习模型大多需要大量的计算 , 因此不仅需要增加在环境中探索收集样本的行为主体的数量 , 还需要能够在庞大的训练数据下进行高效迭代训练的能力 。
为了解决这一问题 , 研究人员提出了名为Menger的 大规模分布式强化学习架构 , 可以在多线程集群中大规模地实现数千个行为单元 , 并大幅度减小任务的训练时间 。
强化学习算法在过去几年中取得了巨大的成就 , 从芯片布局到资源配置 , 从围棋到Dota , 它一往无前地进步着 。 简单来讲 , 强化学习算法的开发过程可以视为数据收集和模型训练的循环过程 , 其中主体会在环境中探索并收集样本 , 而后这些数据被送入到学习器中进行训练并更新模型 。
目前先进的强化学习模型大多需要在数百万个从环境中获取的样本上进行多次迭代训练循环才能够解决特定的目标任务 (例如Dota2的训练过程每两秒就能对200万帧进行学习) 。 在如此大的计算需求下 ,强化学习不仅需要提高效率增加在环境中探索收集样本的行为主体的数量 , 同时还需要能够在如此庞大的训练数据下进行高效迭代训练的能力 。
文章图片
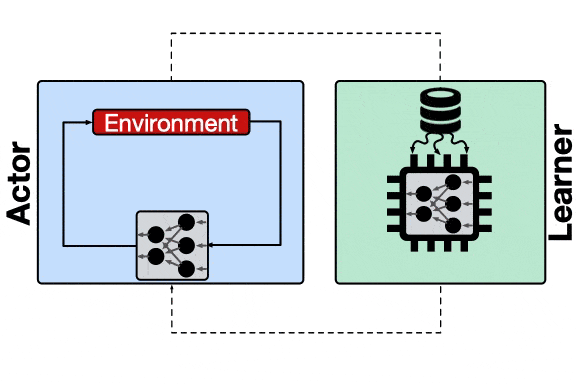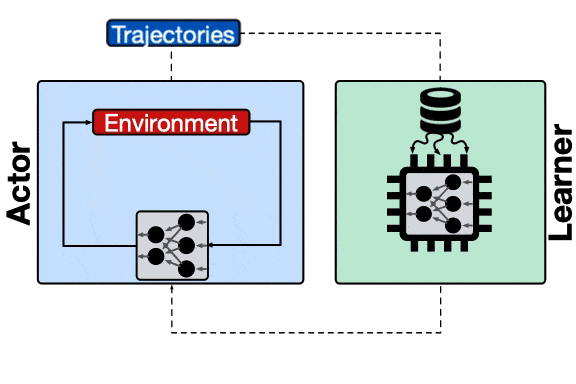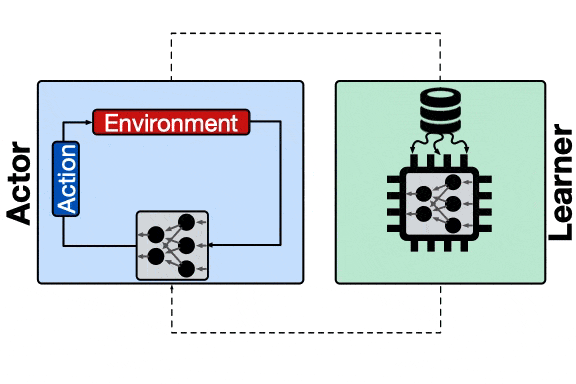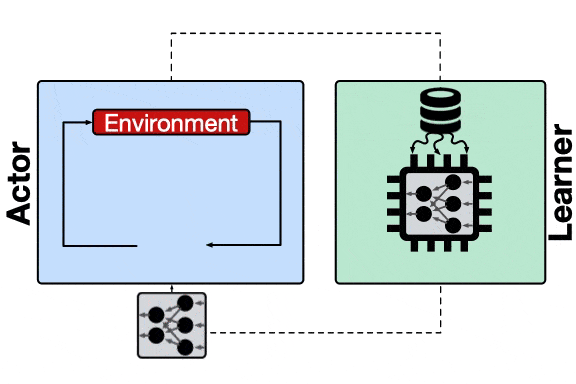
强化学习系统的基本训练流程 , 行为主体首先将采集到的样本送到学习器 , 而后学习器利用这些样本对模型进行训练并将更新后的模型推送给行为主体 。
为了解决这一问题 , 研究人员提出了名为 Menger的 大规模分布式强化学习架构 ,可以在多线程集群 (Borg cells) 中大规模地实现数千个行为单元 , 并大幅度减小任务的训练时间 。
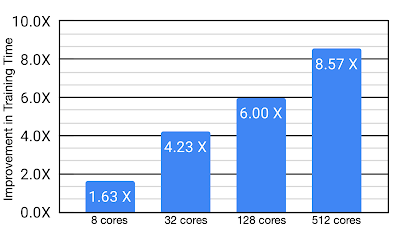
这篇文章讲解了整个架构的实现原理 , 以及如何提高现芯片设计中芯片布局任务的训练效率 。 实验表明 , 这种方法得到的结果 相较于原先的方法可以提升8.6x的训练效率 。
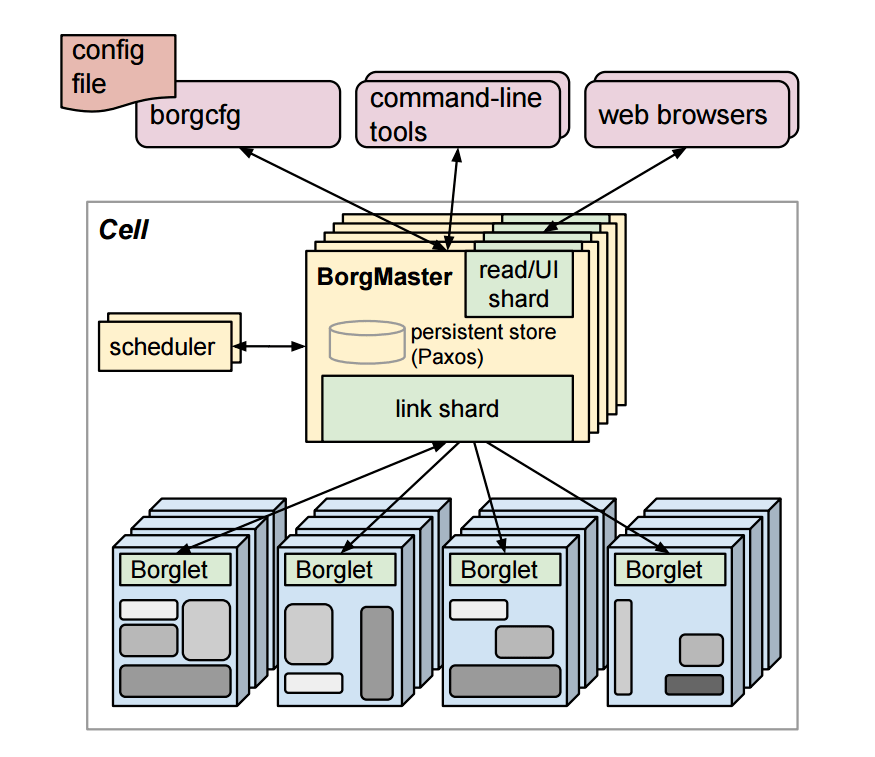
注释:Brog系统是一套大规模的集群管理系统 , 可以在数千个机器组成的多个集群上实现对于不同应用和任务的有效管理 。
Menger系统设计
人们在分布式强化学习系统领域研发出了不同的系统 , 包括Acme和SEED RL等 , 但每种系统都针对分布式系统中的不同方面进行优化 。
文章图片
文章图片
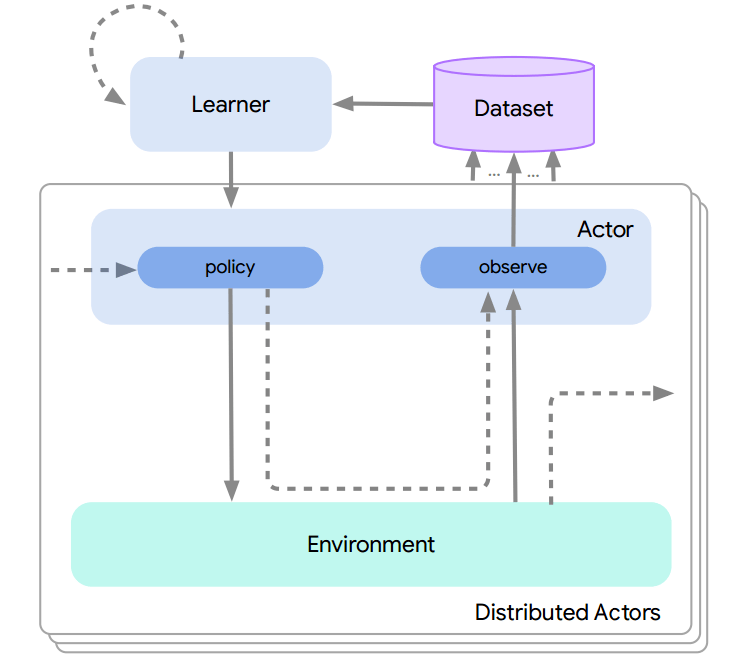
Acme和SEED系统
Acme在每个行动主体上使用了局部推理 , 并频繁地从学习器请求模型;SEED RL则使用了中心化的推理设计 , 利用一部分TPU核来进行批处理 。
但在分布式强化学习系统的设计中必须要关注一下两个部分的权衡:一方面是行为器与学习器间的数据样本和模型传输的通信开销;另一方面是行为器本身 (CPUs) 的推理开销与加速器 (GPUs/TPUs) 间的比较 。
在综合考虑目标任务对于观测数量、行为空间和模型大小的情况下 ,Menger选择了与Acme相似的局部推理方式 , 但却将行为器的规模进行了非常大的拓展!
在实现大规模与高速训练的过程中 , 主要存在以下两个挑战:
1. 为数量庞大的行为器提供模型请求服务会成为学习器的瓶颈所在 , 随着行为主体的增加收敛速度会越来越慢;
2. TPU的效率主要取决于输入流程的性能 , 当TPU计算核大幅度增加时输入流程的性能是决定整个训练效率的关键所在 。
高效的模型请求
为了解决传输的性能瓶颈 , 研究人员 在学习器与行为器间引入了分布式透传缓存机制 , 其中行为器使用TensorFlow进行优化 , 并利用Reverb作为后端 。
缓存原件的主要目的在于平衡庞大数量行为器的请求和学习器的任务 。 这些缓存原件不仅大幅度减小了学习器提供模型请求的压力 , 同时也将行为器的模型读取延时缩短约了4倍 , 使得算法、特别是PPO这样的策略训练循环更加迅速 。
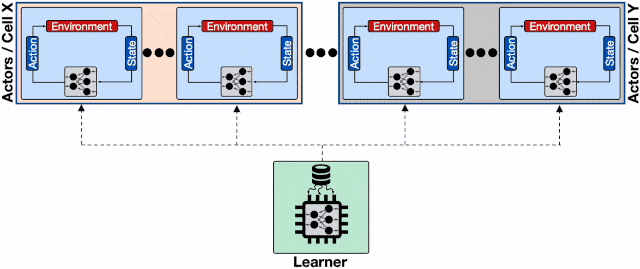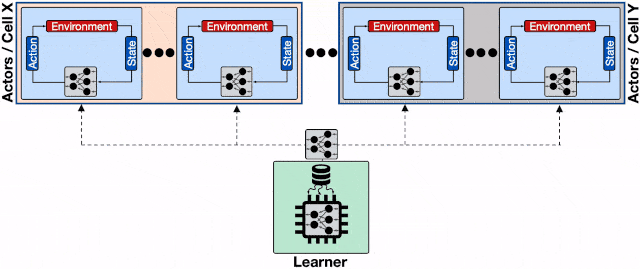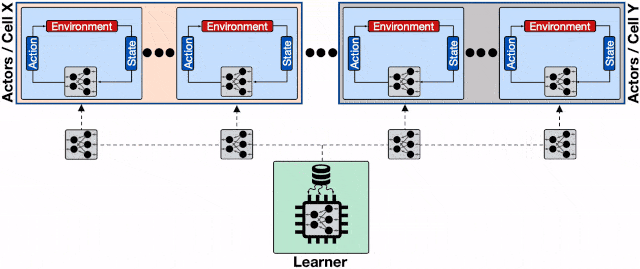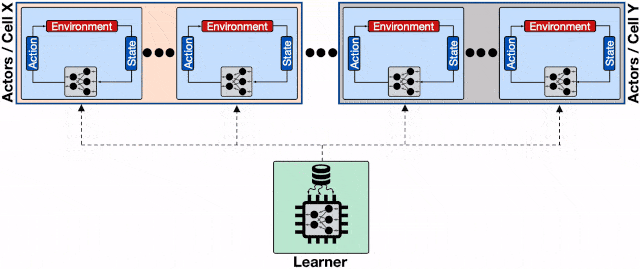
文章图片
分布式强化学习系统的架构 。 每一个蓝色的行为器都需要像学习器请求模型 , 通信开销会增加整体的收敛时间;
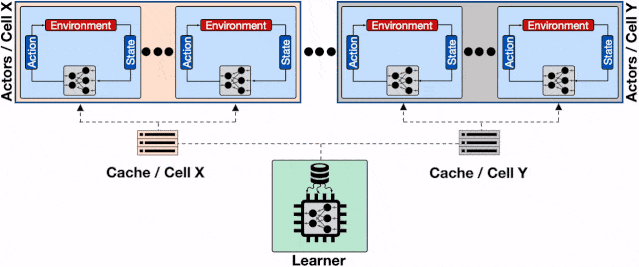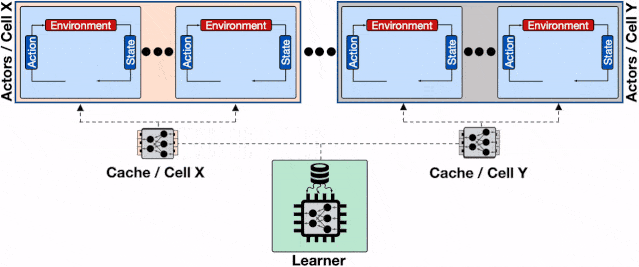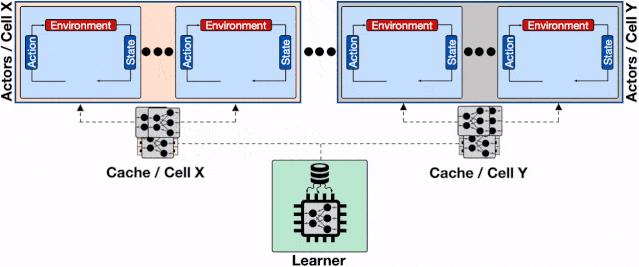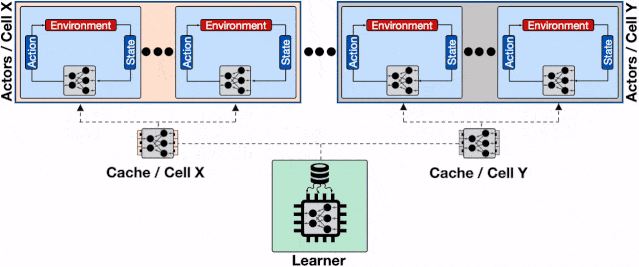
文章图片
增加了透传缓存机制的分布式系统 , 行为器会从邻近的缓存中读取模型、不仅缓解了学习器的负载压力、同时减小了行为器读取模型的平均延时 。
高通量输入流程
为了解决数据输入的性能瓶颈 , 研究人员 使用了机器学习任务专用的数据存储系统 Reverb 。 但仅仅使用单个Reverb回放缓存服务是不足以支撑大规模分布式强化学习系统的性能要求的 , 来自数千个行为器的数据写入效率会被大大拉低 。
文章图片
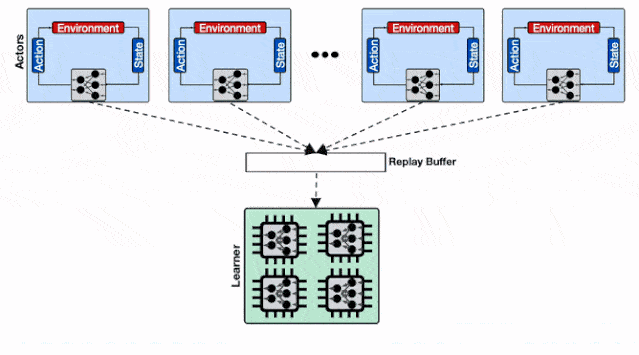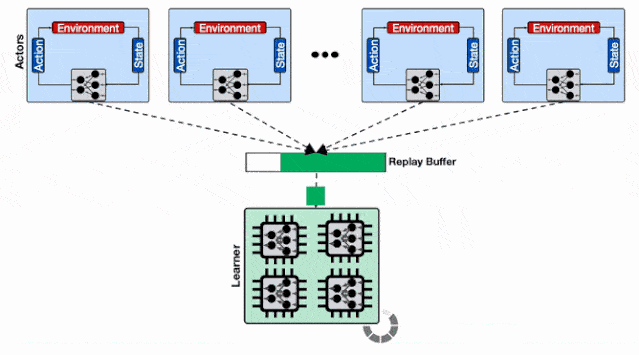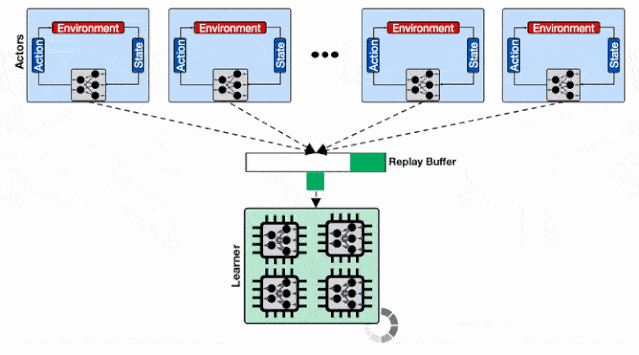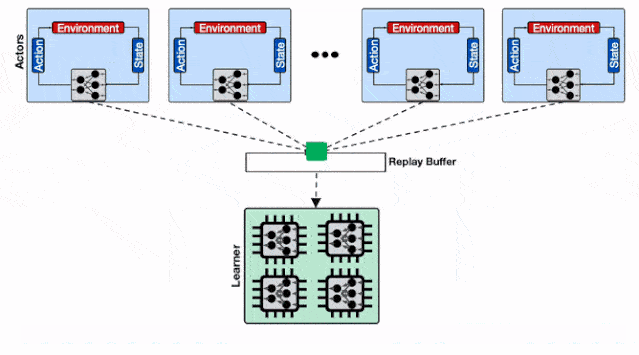
仅仅存在单个回放缓存时 , 数千个行为器的数据被拖慢 。 训练系统使用了多个计算核 , 那么仅仅使用一个数据回放缓存是不足以支撑高性能计算的 。
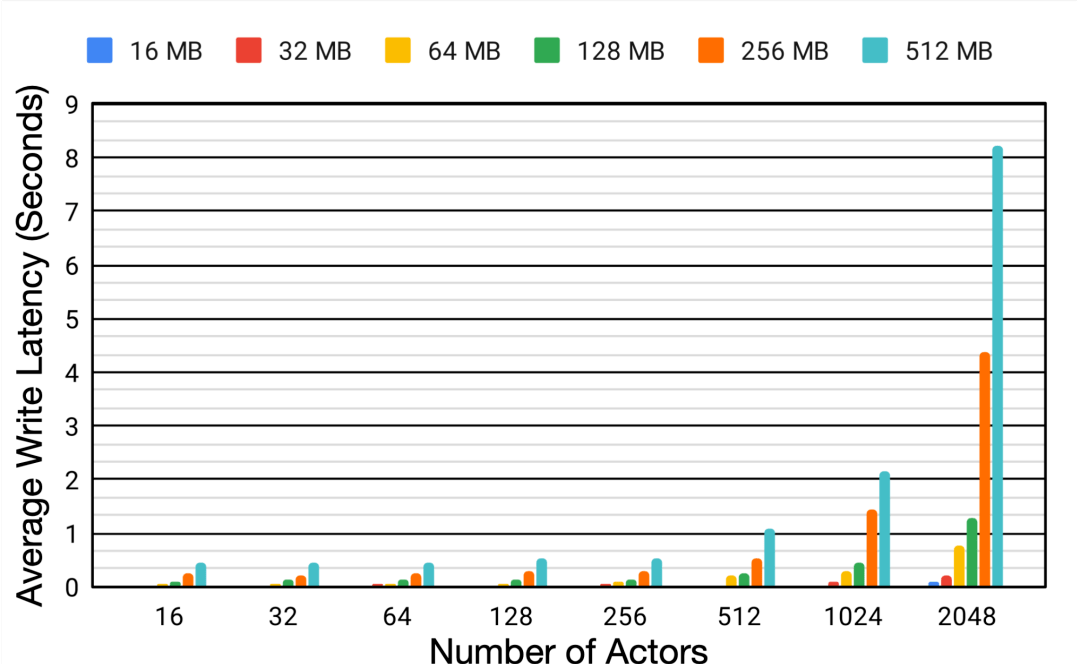
为了更好地理解分布式系统中回放缓存 (replay buffer) 的性能 , 研究人员利用不同的模型大小和行为器数量在相同的设备上进行了比较试验 。
实验表明 , 随着行为器数量从16增长到2048 , 模型大小从16M增加到512M的过程中 , 平均延时增加了6.2倍和18.9倍 , 这种写入数据的延迟大幅度降低了行为器从环境中收集数据的效率 , 并造成了整体训练过程的低效 。
文章图片
单个Reverb缓冲器的性能变化
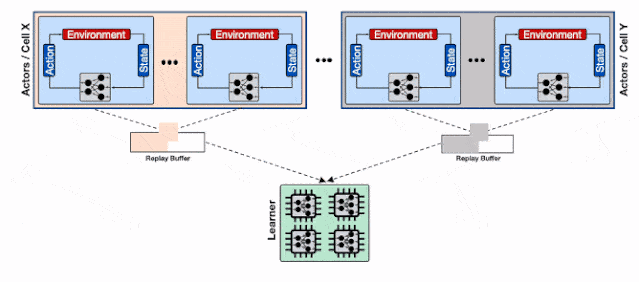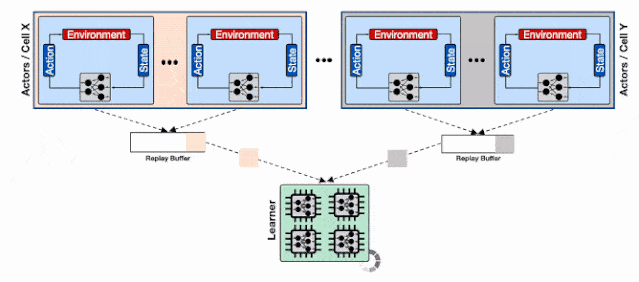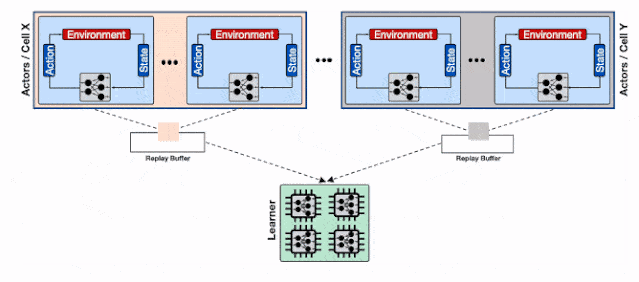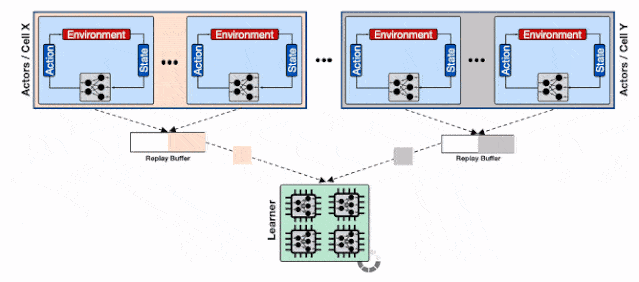
为了解决这一问题 , 研究人员 利用了Reverb的 分片能力来增加行为器和学习器以及回放缓存服务间的数据通量。 分片功能平衡了数量巨大的行为器与多个缓存器间的负载 , 避免了单个缓存器造成的瓶颈 , 最小化了写延时 。 这种方式使得Menger可以在不同Borg计算单元上大规模地进行拓展 。
文章图片
基于分片重放缓存的分布式强化学习系统 , 每个缓存收集来自多个学习器的数据 , 为输入学习器的加速硬件提供了更高的数据通量 。
案例分析:芯片布局任务
研究人员将这套算法应用于芯片设计中布局任务的优化中 ,实验表明针对实际任务这种方法将训练时间从8.6小时减低为一个小时 。 虽然Menger在TPU上进行了优化 , 但同时作者认为在GPUs上也会有相似地性能提升 。
文章图片
这种框架为大规模强化学习提供了有益的方向 , 虽然仅仅在芯片设计的位置布局上成功应用 , 但这也从一个侧面反映出强化学习与这套系统在各个领域较好的应用前景 。 未来如果想利用成百上千个智能体进行任务训练提升训练性能 , 这套分布式高速训练系统是不错的选择 。
ref:
ChipPlace:https://arxiv.org/pdf/2004.10746.pdf
https://ai.googleblog.com/2020/04/chip-design-with-deep-reinforcement.html
https://dy.163.com/article/FBKOFGVP0511CPMT.html
Borg:https://research.google/pubs/pub49065/
Reverb:https://github.com/deepmind/reverb
▼
【进行|?大规模分布式强化学习基础架构Menger, 大幅提高真实任务的学习效率】微信:thejiangmen
推荐阅读





- Apple|法官称苹果零售店搜包和解协议虽不完美,但可继续进行
- Samsung|三星:西安半导体工厂正常运行 已进行封闭管理
- 平台|[原]蚂蚁集团SOFAStack:新一代分布式云PaaS平台,打造企业上云新体验
- GripSeal|液压油缸能用GripSeal格雷希尔快速连接器进行油压密封测试吗?
- 通信技术|FCC的胜诉为Wi-Fi 6E的大规模升级扫清了道路
- 普鲁斯特|2022年,我不要再和任何人进行该死的愚蠢交谈
- 相关|博汇科技:对虚拟主播换脸、语音合成技术进行了研究
- 技术|建设一批智能工厂、开展大规模职业培训……“十四五”智能制造如何发展?
- 人物|贾跃亭所持1739.8万股乐视网股票将于明年1月5日进行网拍
- 进行了|真我GT2 Pro挑战直屏天花板:五项全能2K无级变帧!业内直屏独一档!