NeurIPS|NeurIPS 2020 | Glance and Focus: 通用、高效的神经网络自适应推理框架
作者:清华大学自动化系直博二年级 王语霖
NeurlPS 2020 文章专题
第·3·期
本文将分享 清华大学发表于NeurIPS 2020的工作: 《Glance and Focus: 通用、高效的神经网络自适应推理框架》 。
这项工作提出了一个通用于绝大多数CNN的自适应推理框架 , 将MobileNetV3的平均推理速度加快了30% , 将ResNet/DenseNet加速了3倍以上 , 且在iPhone XS Max上的实际测速和理论结果高度吻合 。 此外 , 它的计算开销可以简单地动态在线调整 , 无需额外训练 。

文章图片
论文链接:
https://arxiv.org/abs/2010.05300
代码/预训练模型:
https://github.com/blackfeather-wang/GFNet-Pytorch
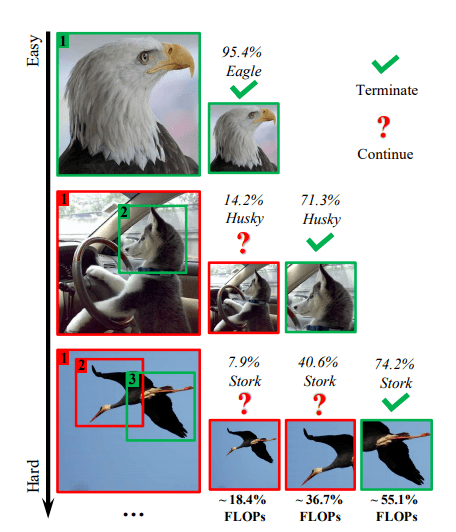
文章图片
图1 Glance and Focus Network (GFNet) 效果图
1. Introduction (研究动机及简介)
在基于卷积神经网络(CNN)的图像任务中 , 提升网络效果的一个有效方法是使用高分辨率的输入 , 例如 , 在ImageNet分类[1]任务上 , 近年来的最新网络(DenseNet[2], SENet[3], EfficientNet[4])往往需要使用224x224或更大的输入图片以取得最佳性能:
然而 , 这种方式会带来较大的计算开销 , 因为推理CNN所需的计算量(FLOPs)基本与像素数目成正比[5] , 即与图形的长、宽成二次关系 , 如下图所示:
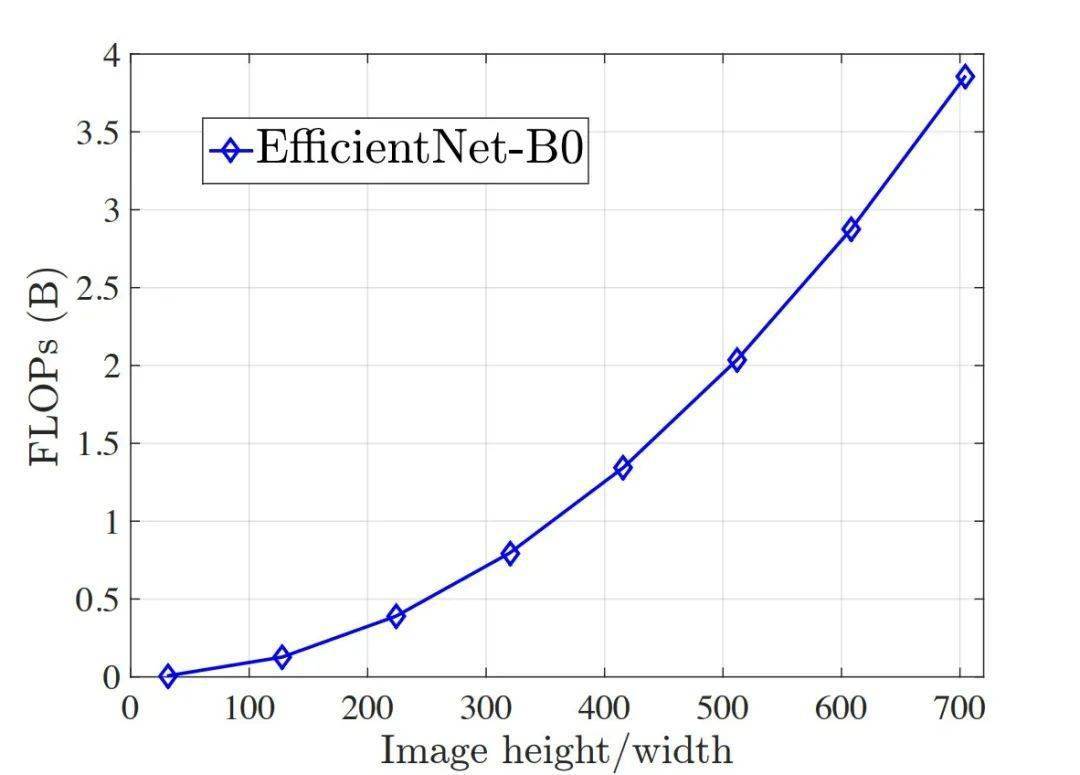
文章图片
图2 CNN计算量与图片长/宽的关系
在实际应用(例如手机APP、自动驾驶系统、图片搜索引擎)中 , 计算量往往正比于能耗或者时间开销 , 显然 , 无论出于成本因素还是从安全性和用户体验的角度考虑 , 网络的计算开销都应当尽可能小 。 那么 , 如何在保留高分辨率输入所带来的好处的同时 , 减小其计算开销呢?
事实上 , 我们可以借助神经网络的一个有趣的性质 。 与人类视觉相似 , 神经网络往往可以通过仅仅处理图像中与任务相关的一小部分区域而得到正确的结果 , 例如在下图中 , 遮挡住屋顶、飞鸟或花朵之外的部分 , 神经网络仍然可以得到正确的分类结果[6]:

文章图片
图3 部分关键信息足以使神经网络做出可靠的判断
这便是本文所提出方法的出发点 , 我们的目标是 , 对于输入图片 , 自适应地找到其与任务最相关的区域 , 进而通过使神经网络只处理这些区域 , 以尽可能小的计算量得到可信的结果 。 具体而言 , 我们采用的方法是 , 将一张分辨率较高的图片表征为若干个包含其关键部分的“小块”(Patch) , 而后仅将这些小块输入神经网络 。 以下面的示意图为例 , 将一张224x224的图片分解为3个96x96的Patch进行处理所需的计算量仅为原图的55.2% 。
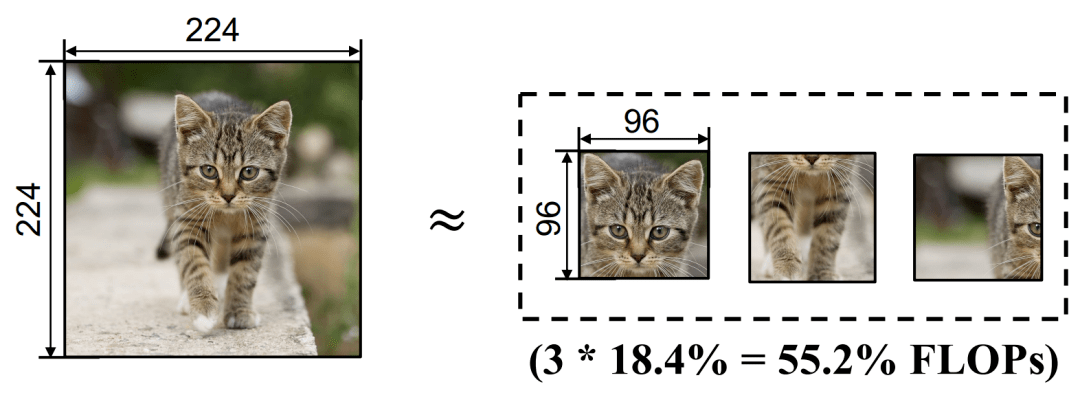
文章图片
图4 Glance and Focus Network (GFNet) 的基本建模方式
2. Method (方法详述)
为了实现上述目的 , 事实上 , 有两个显然的困难:
(a) 任意给定一张输入图片 , 如何判断其与任务最相关的区域在哪里呢?

文章图片
图5 对于不同输入 , 应分配不同大小的计算资源
为了解决这两个问题 , 我们设计了一个Glance and Focus的框架 , 将这一思路建模为了一个序列决策过程 , 如下图所示 。
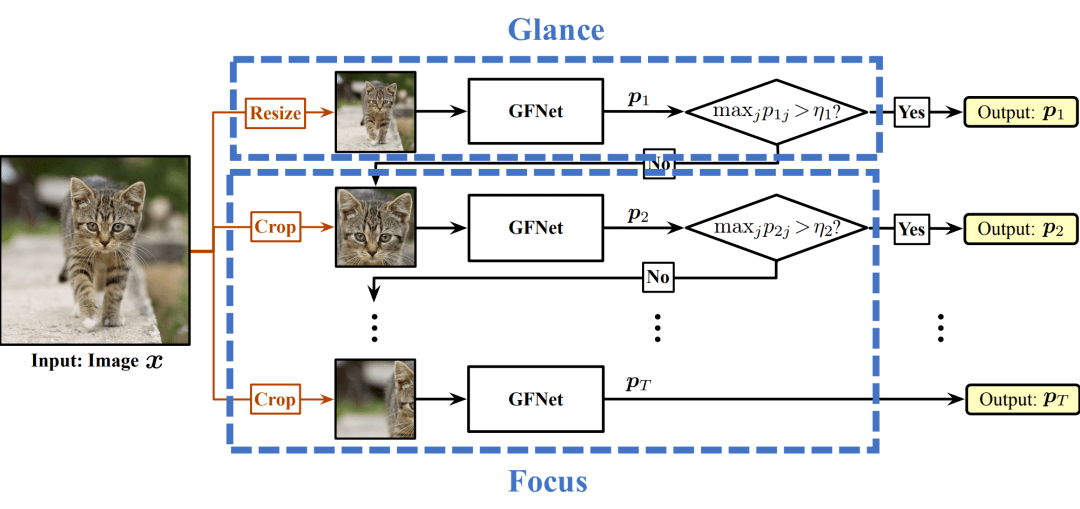
文章图片
图6 Glance and Focus Network (GFNet) 的基本框架
其具体执行流程为:
1. 首先 , 对于一张任意给定的输入图片 , 由于我们没有任何关于它的先验知识 , 我们直接将其放缩为一个patch的大小 , 输入网络 , 这一方面产生了一个初步的判断结果 , 另一方面也提供了原始输入图片的空间分布信息;这一阶段称为扫视(Glance) 。
2. 而后 , 我们再以这些基本的空间分布信息为基础 , 逐步从原图上取得高分辨率的patch , 将其不断输入网络 , 以此逐步更新预测结果和空间分布信息 , 得到更为准确的判断 , 并逐步寻找神经网络尚未见到过的关键区域;这一阶段称为关注(Focus) 。
值得注意的是 , 在上述序列过程的每一步结束之后 , 我们会将神经网络的预测自信度(confidence)与一个预先定义的阈值进行比较 , 一旦confidence超过阈值 , 我们便视为网络已经得到了可信的结果 , 这一过程立即终止 。 此机制称为自适应推理(Adaptive Inference) 。
通过这种机制 , 我们一方面可以使不同难易度的样本具有不同的序列长度 , 从而动态分配计算量、提高整体效率;另一方面可以简单地通过改变阈值调整网络的整体计算开销 , 而不需要重新训练网络 , 这使得我们的模型可以动态地以最小的计算开销达到所需的性能 , 或者实时最大化地利用所有可用的计算资源以提升模型表现 。
关于这些阈值的具体整定方法 , 由于比较繁杂 , 不在这里赘述 , 可以参阅我们的paper~
3. Network Architecture (网络结构)
下面我们简要介绍Glance and Focus Network (GFNet) 的具体结构 , 如下图所示 。 关于具体的训练方法 , 可以参阅我们的paper~
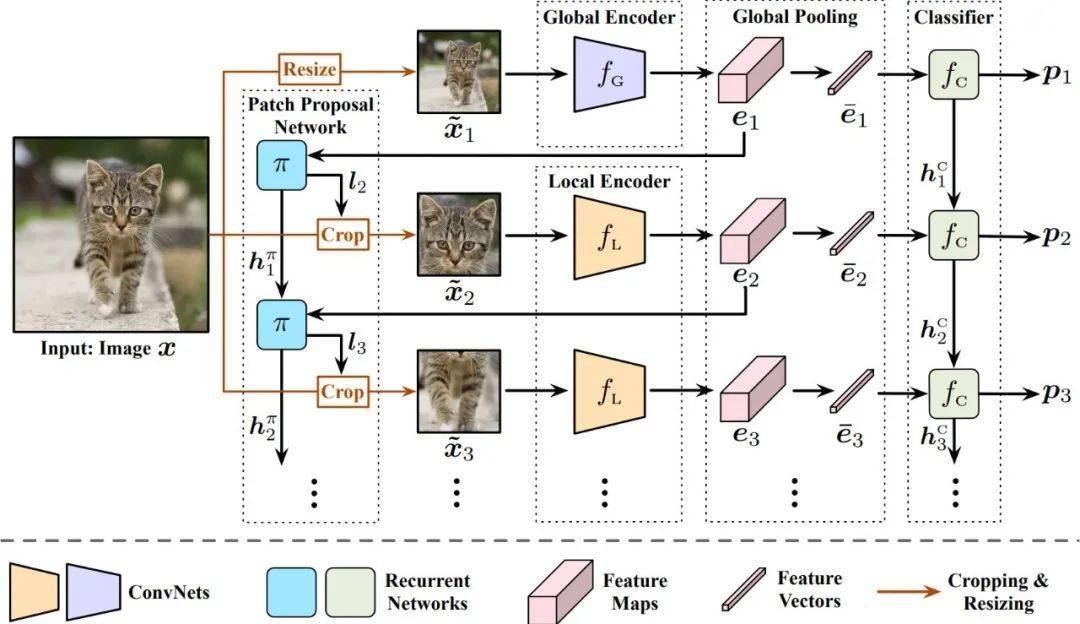
文章图片
图7 Glance and Focus Network (GFNet) 的网络结构
GFNet共有四个组件 , 分别为:
- 全局编码器和局部编码器(Global Encoder and Local Encoder) 为两个CNN , 分别用于从放缩后的原图和局部patch中提取信息 , 之所以用两个CNN , 是因为我们发现一个CNN很难同时适应缩略图和局部patch两种尺度(scale)的输入 。 几乎所有现有的网络结构均可以作为这两个编码器以提升其推理效率(如MobileNet-V3、EfficientNet、RegNet等) 。
- 分类器(Classifier) 为一个循环神经网络(RNN) , 输入为全局池化后的特征向量 , 用于整合过去所有输入的信息 , 以得到目前最优的分类结果 。
- 图像块选择网络(Patch Proposal Network) 是另一个循环神经网络(RNN) , 输入为全局池化前的特征图(不做池化是为了避免损失空间信息) , 用于整合目前为止所有的空间分布信息 , 并决定下一个patch的位置 。 值得注意的是由于取得patch的crop操作不可求导 , PPN是使用强化学习中的策略梯度方法(policy gradient)训练的 。
在实验中我们考虑了两种设置:
下图为我们在不同网络结构上实现GFNet的实验结果 , 其中横轴为网络的平均理论计算开销 , 纵轴为准确率 , (a-e)为budgeted batch classi?cation的结果 , (f)为anytime prediction的结果 。
可以看出 , GFNet明显地提升了包括MobileNetV3、RegNet和EfficientNet在内的最新网络结构的推理效率 , 同等精度下 , 计算开销减小达30-40%以上 , 对于ResNet/DenseNet的增幅可达3倍甚至更高;同等计算开销下 , 对MobileNetV3提点2%左右 , 对ResNet/DenseNet达5-10%以上 。
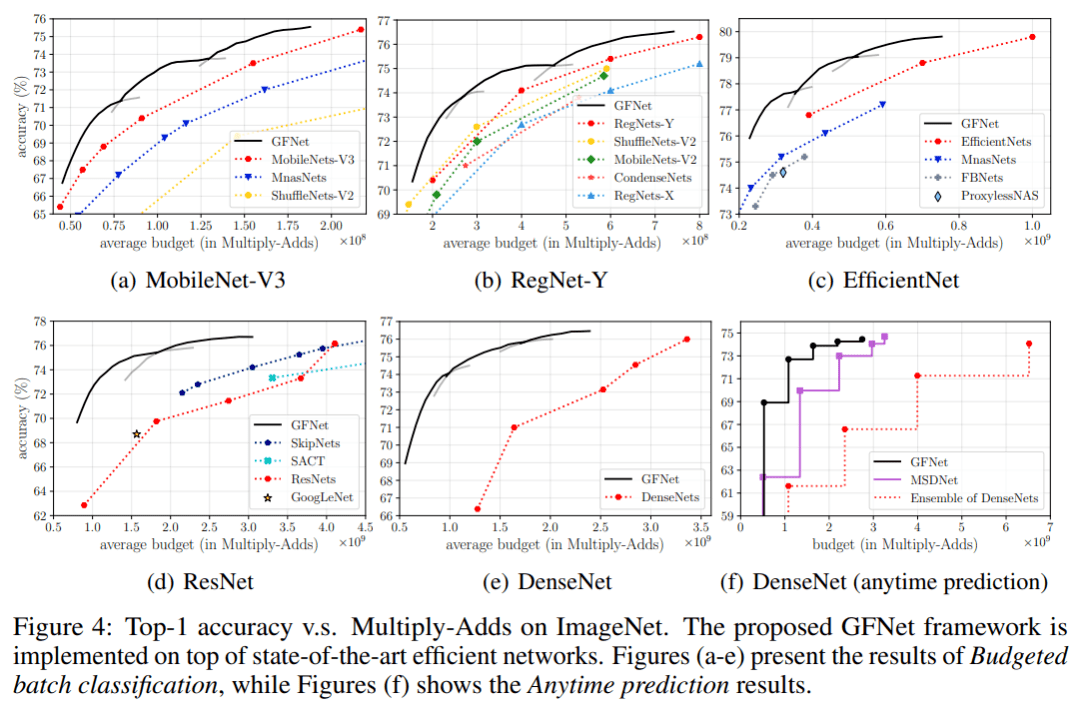
文章图片
图8 GFNet基于不同CNN的实验结果(Accuracy v.s. Multiply-Adds)
GFNet的另一个显著优势是 , 由于其没有更改CNN的具体结构 , 其可以方便地在移动端或边缘设备上使用现有的工具部署 , 且享有和理论结果几乎等同的实际加速比 。 下图为我们在一台iPhone XS Max(就是我的手机)上基于TensorFlow Lite的测试结果:
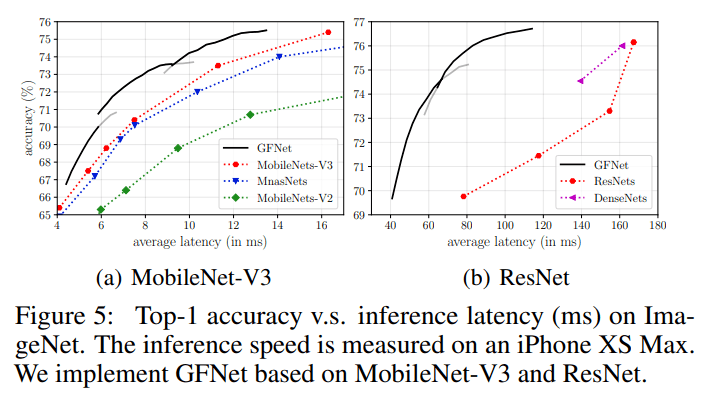
文章图片
图9 GFNet在一台iPhone XS Max上的实际测试结果(Accuracy v.s. Latency)
下面是GFNet的一些可视化结果 , 可以从中看出 , 对于比较简单的样本 , GFNet可以仅在Glance阶段或Focus阶段的第一步以很高的confidence得到正确的结果 , 对于较为复杂的样本 , 则实现了以不断关注关键区域的形式逐步提升confidence 。

文章图片
图10 GFNet的可视化结果
5. Conclusion (结语)
//
作者介绍:
王语霖 , 清华大学自动化系直博二年级 , 导师为吴澄院士和黄高助理教授 。 此前于北京航空航天大学自动化科学与电气工程学院获工学学士学位 。 目前的研究兴趣为深度学习与计算机视觉 , 在NeurIPS 2019/2020以第一作者发表两篇学术论文 。
参考资料:
[1] http://www.image-net.org/
[2] https://arxiv.org/pdf/2001.02394.pdf
[3] https://arxiv.org/pdf/1709.01507.pdf
[4] https://arxiv.org/pdf/1905.11946.pdf
[5] https://papers.nips.cc/paper/5542-recurrent-models-of-visual-attention.pdf
【NeurIPS|NeurIPS 2020 | Glance and Focus: 通用、高效的神经网络自适应推理框架】[6] https://arxiv.org/pdf/1910.08485.pdf
推荐阅读










- 平板|小新 Pad Pro 2020 平板开启 OTA7 ZUI 13 灰度推送
- 国际|特奖得主任队长,清华夺冠NeurIPS 2021国际深度元学习挑战赛
- 国际|2020年我国产出卓越科技论文46万余篇
- 排名|2020年我国国际顶尖期刊论文数量排名世界第二 上升2位
- 最新消息|印度创企2021年获360亿美元投资 比2020年增长2倍
- 未来|汾酒荣获2020年度中国食品工业协会科学技术奖两项殊荣
- the|美国疾控中心公布2020年十大死因:心脏病排名第一 癌症第二
- the|CDC:美国人均预期寿命在2020年缩短近2年
- 疫情|中科院报告:2020年中国共出版科普图书近亿册
- 期刊|中国首部科学传播报告:2020年出版科普图书9853.6万册