机器之心专栏
机器之心编辑部
华为诺亚实验室的研究者提出了一种新型视觉 Transformer 网络架构 Transformer in Transformer , 它的表现优于谷歌的 ViT 和 Facebook 的 DeiT 。 论文提出了一个全新的 TNT 模块(Transformer iN Transformer) , 旨在通过内外两个 transformer 联合提取图像局部和全局特征 。 通过堆叠 TNT 模块 , 研究者搭建了全新的纯 Transformer 网络架构——TNT 。 值得注意的是 , TNT 还暗合了 Geoffrey Hinton 最新提出的 part-whole hierarchies 思想 。 在 ImageNet 图像识别任务上 , TNT 在相似计算量情况下的 Top-1 正确率达到 81.3% , 高于 DeiT 的 79.8% 和 ViT 的 77.9% 。
Transformer 网络推动了诸多自然语言处理任务的进步 , 而近期 transformer 开始在计算机视觉领域崭露头角 。 例如 , DETR 将目标检测视为一个直接集预测问题 , 并使用 transformer 编码器 - 解码器架构来解决它;IPT 利用 transformer 在单个模型中处理多个底层视觉任务 。 与现有主流 CNN 模型(如 ResNet)相比 , 这些基于 transformer 的模型在视觉任务上也显示出了良好的性能 。
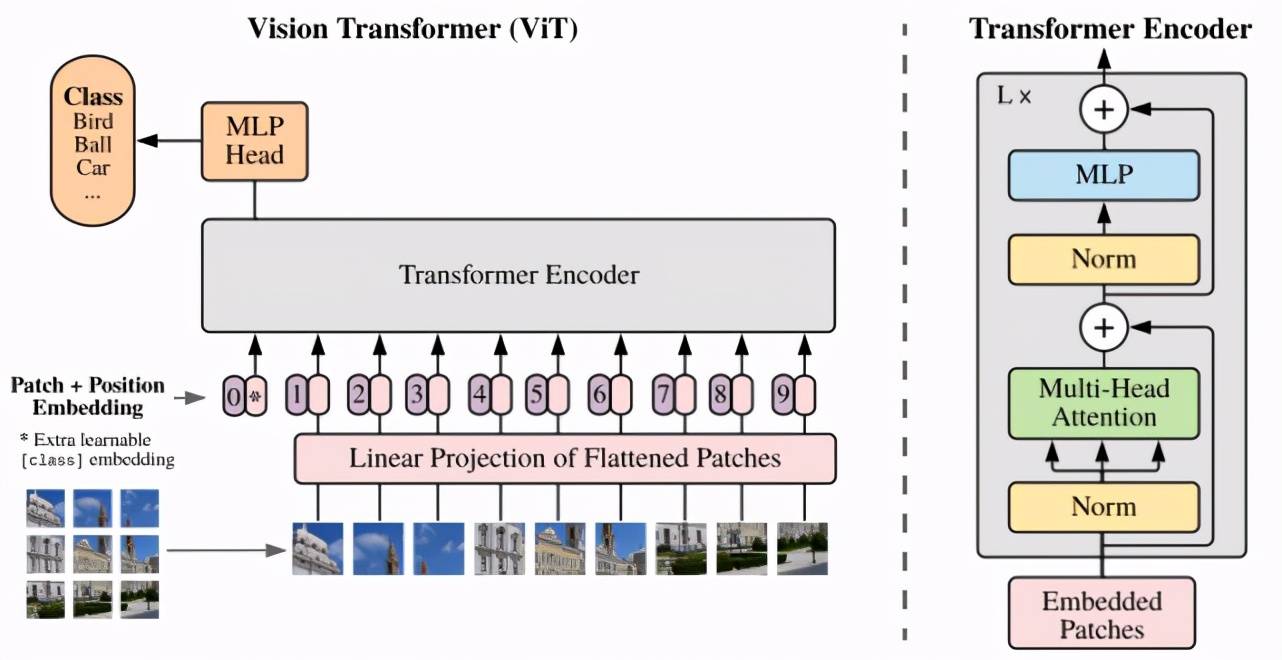
谷歌 ViT(Vision Transformer)模型是一个用于视觉任务的纯 transformer 经典技术方案 。 它将输入图片切分为若干个图像块(patch) , 然后将 patch 用向量来表示 , 用 transformer 来处理图像 patch 序列 , 最终的输出做图像识别 。 但是 ViT 的缺点也十分明显 , 它将图像切块输入 Transformer , 图像块拉直成向量进行处理 , 因此 , 图像块内部结构信息被破坏 , 忽略了图像的特有性质 。
文章图片
图 1:谷歌 ViT 网络架构 。
在这篇论文中 , 来自华为诺亚实验室的研究者提出一种用于基于结构嵌套的 Transformer 结构 , 被称为 Transformer-iN-Transformer (TNT) 架构 。 同样地 , TNT 将图像切块 , 构成 Patch 序列 。 不过 , TNT 不把 Patch 拉直为向量 , 而是将 Patch 看作像素(组)的序列 。
【视觉|优于ViT和DeiT,华为利用Transformer块构建新型视觉骨干模型TNT】
文章图片
论文链接:https://arxiv.org/pdf/2103.00112.pdf
具体而言 , 新提出的 TNT block 使用一个外 Transformer block 来对 patch 之间的关系进行建模 , 用一个内 Transformer block 来对像素之间的关系进行建模 。 通过 TNT 结构 , 研究者既保留了 patch 层面的信息提取 , 又做到了像素层面的信息提取 , 从而能够显著提升模型对局部结构的建模能力 , 提升模型的识别效果 。
在 ImageNet 基准测试和下游任务上的实验均表明了该方法在精度和计算复杂度方面的优越性 。 例如 ,TNT-S 仅用 5.2B FLOPs 就达到了 81.3% 的 ImageNet top-1 正确率 , 这比计算量相近的 DeiT 高出了 1.5% 。
方法
图像预处理
图像预处理主要是将 2D 图像转化为 transformer 能够处理的 1D 序列 。 这里将图像转化成 patch embedding 序列和 pixel embedding 序列 。 图像首先被均匀切分成若干个 patch , 每个 patch 通过 im2col 操作转化成像素向量序列 , 像素向量通过线性层映射为 pixel embedding 。 而 patch embedding(包括一个 class token)是一组初始化为零的向量 。 具体地 , 对于一张图像 , 研究者将其均匀切分为 n 个 patch:
其中是 patch 的尺寸 。
Pixel embedding 生成:对于每个 patch , 进一步通过 pytorch unfold 操作将其转化成 m 个像素向量 , 然后用一个全连接层将 m 个像素向量映射为 m 个 pixel embedding:
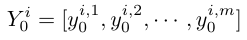
文章图片
其中和 , c 是 pixel embedding 的长度 。 N 个 patch 就有 n 个 pixel embedding 组:
Patch embedding 生成:初始化 n+1 个 patch embedding 来存储模型的特征 , 它们都初始化为零:
其中第一个 patch embedding 又叫 class token 。
Position encoding:对每个 patch embedding 加一个 patch position encoding:
对每个 pixel embedding 加一个 pixel position encoding:
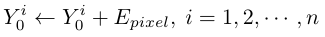
文章图片
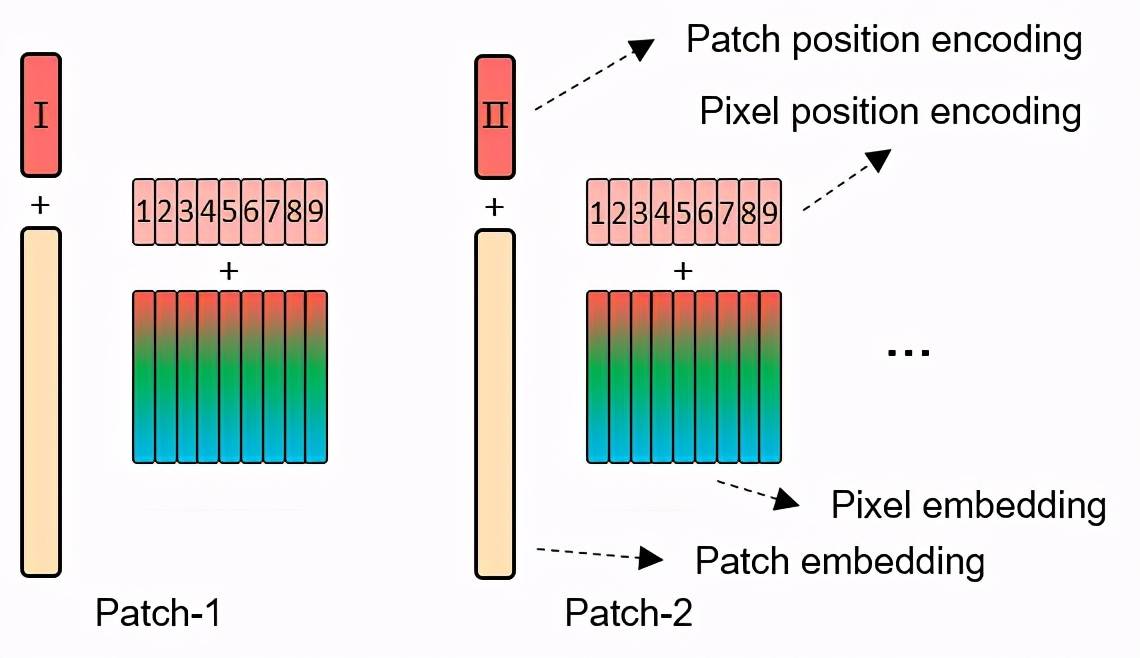
两种 Position encoding 在训练过程中都是可学习的参数 。
文章图片
图 2:位置编码 。
Transformer in Transformer 架构
TNT 网络主要由若干个 TNT block 堆叠构成 , 这里首先介绍 TNT block 。 TNT block 有 2 个输入 , 一个是 pixel embedding , 一个是 patch embedding 。 对应地 ,TNT block 包含 2 个标准的 transformer block 。
如下图 3 所示 , 研究者只展示了一个 patch 对应的 TNT block , 其他 patch 是一样的操作 。 首先 , 该 patch 对应的 m 个 pixel embedding 输入到内 transformer block 进行特征处理 , 输出处理过的 m 个 pixel embedding 。 Patch embedding 输入到外 transformer block 进行特征处理 。 其中 , 这 m 个 pixel embedding 拼接起来构成一个长向量 , 通过一个全连接层映射到 patch embedding 所在的空间 , 加到 patch embedding 上 。 最终 , TNT block 输出处理过后的 pixel embedding 和 patch embedding 。
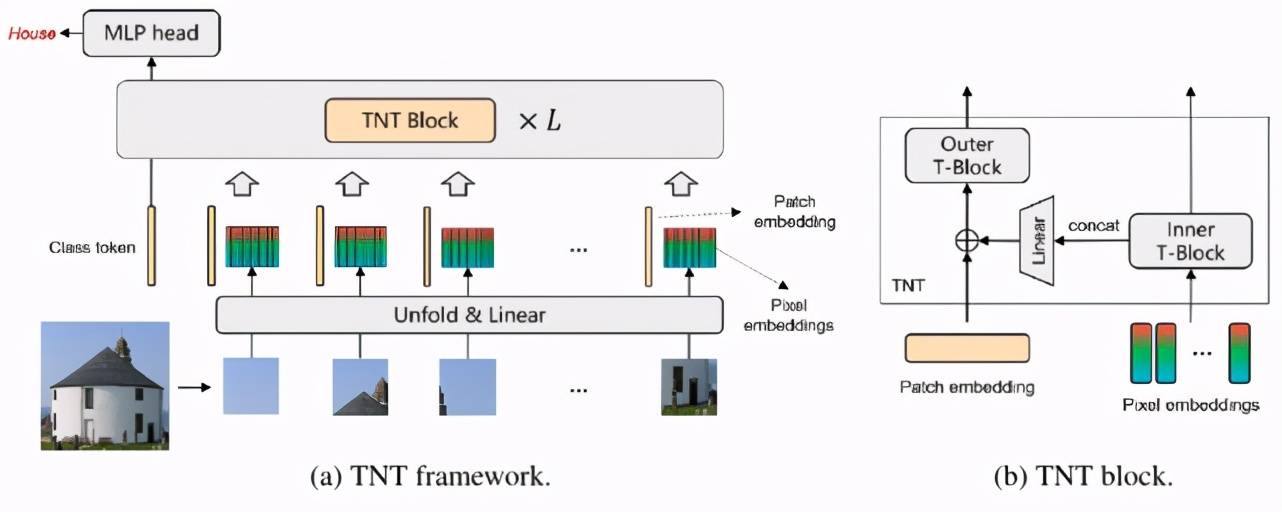
文章图片
图 3:Transformer in Transformer 架构 。
通过堆叠 L 个 TNT block , 构成了 TNT 网络结构 , 如下表 1 所示 , 其中 depth 是 block 个数 , #heads 是 Multi-head attention 的头个数 。

文章图片
表 1:TNT 网络结构参数 。
实验
ImageNet 实验
研究者在 ImageNet 2012 数据集上训练和验证 TNT 模型 。 从下表 2 可以看出 , 在纯 transformer 的模型中 , TNT 优于所有其他的纯 transformer 模型 。 TNT-S 达到 81.3% 的 top-1 精度 , 比基线模型 DeiT-S 高 1.5% , 这表明引入 TNT 框架有利于在 patch 中保留局部结构信息 。 通过添加 SE 模块 , 进一步改进 TNT-S 模型 , 得到 81.6% 的 top-1 精度 。 与 CNNs 相比 , TNT 的性能优于广泛使用的 ResNet 和 RegNet 。 不过 , 所有基于 transformer 的模型仍然低于使用特殊 depthwise 卷积的 EfficientNet , 因此如何使用纯 transformer 打败 EfficientNet 仍然是一个挑战 。
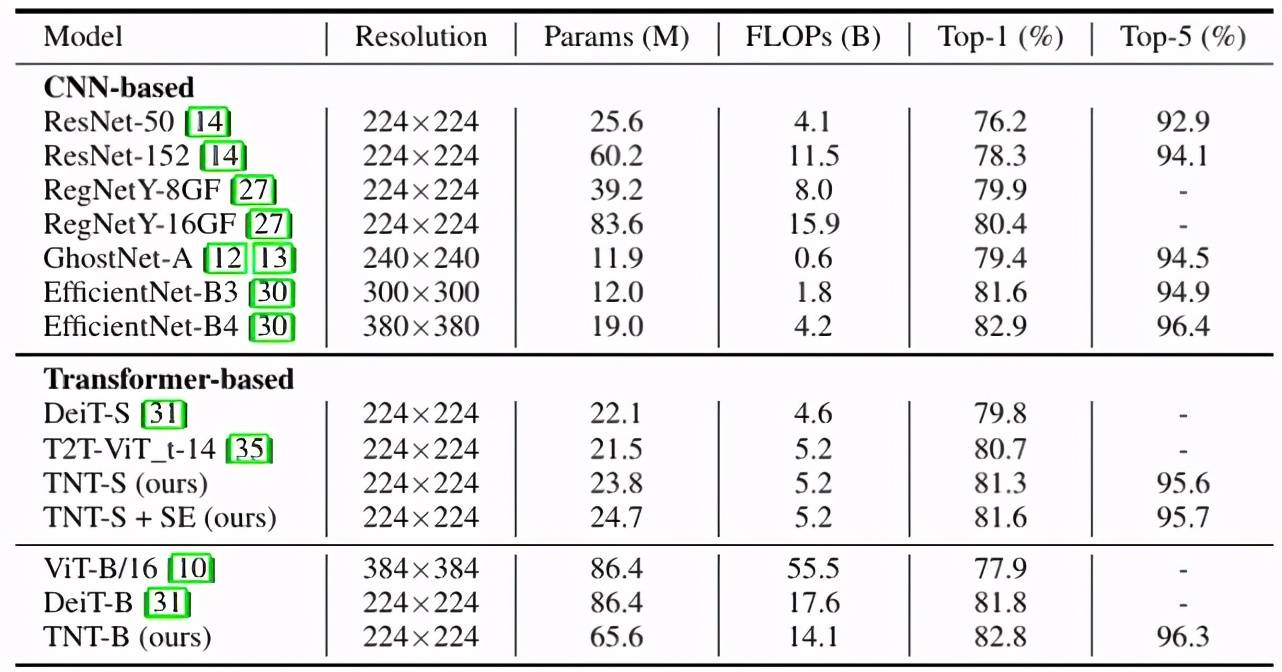
文章图片
表 2:TNT 与其他 SOTA 模型在 ImageNet 数据集上的对比 。
在精度和 FLOPS、参数量的 trade-off 上 , TNT 同样优于纯 transformer 模型 DeiT 和 ViT , 并超越了 ResNet 和 RegNet 代表的 CNN 模型 。 具体表现如下图 4 所示:
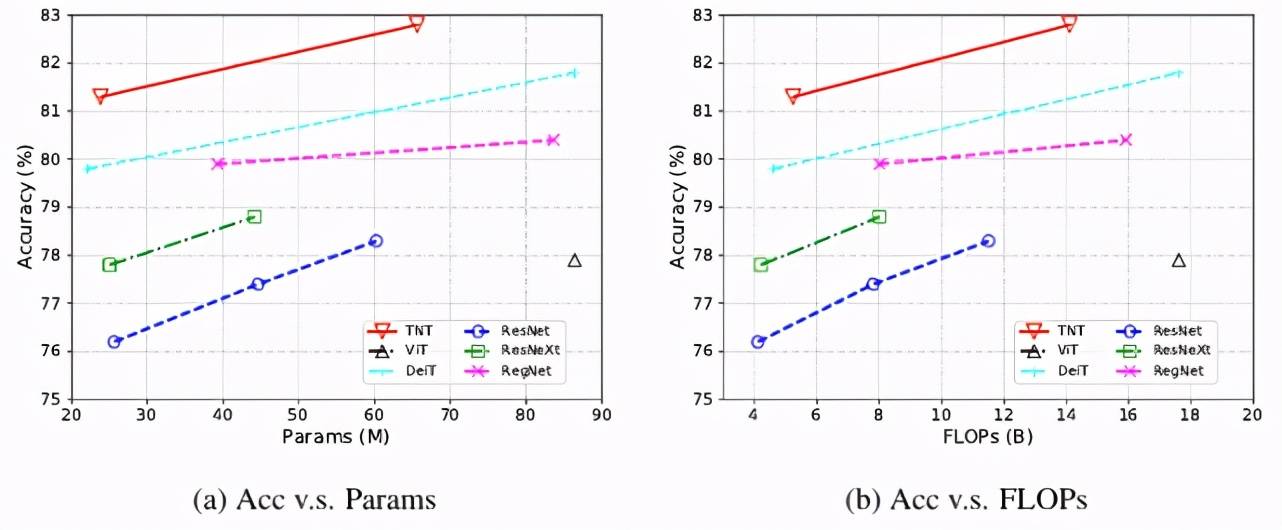
文章图片
图 4:TNT 与其他 SOTA 模型在精度、FLOPS 和参数量指标上的变化曲线 。
特征图可视化
研究者将学习到的 DeiT 和 TNT 特征可视化 , 以进一步探究该方法的工作机制 。 为了更好地可视化 , 输入图像的大小被调整为 1024x1024 。 此外 , 根据空间位置对 patch embedding 进行重排 , 形成特征图 。 第 1、6 和 12 个 block 的特征图如下图 5(a) 所示 , 其中每个块随机抽取 12 个特征图 。 与 DeiT 相比 , TNT 能更好地保留局部信息 。
研究者还使用 t-SNE 对输出特征进行可视化(图 5(b)) 。 由此可见 , TNT 的特征比 DeiT 的特征更为多样 , 所包含的信息也更为丰富 。 这要归功于内部 transformer block 的引入 , 能够建模局部特征 。
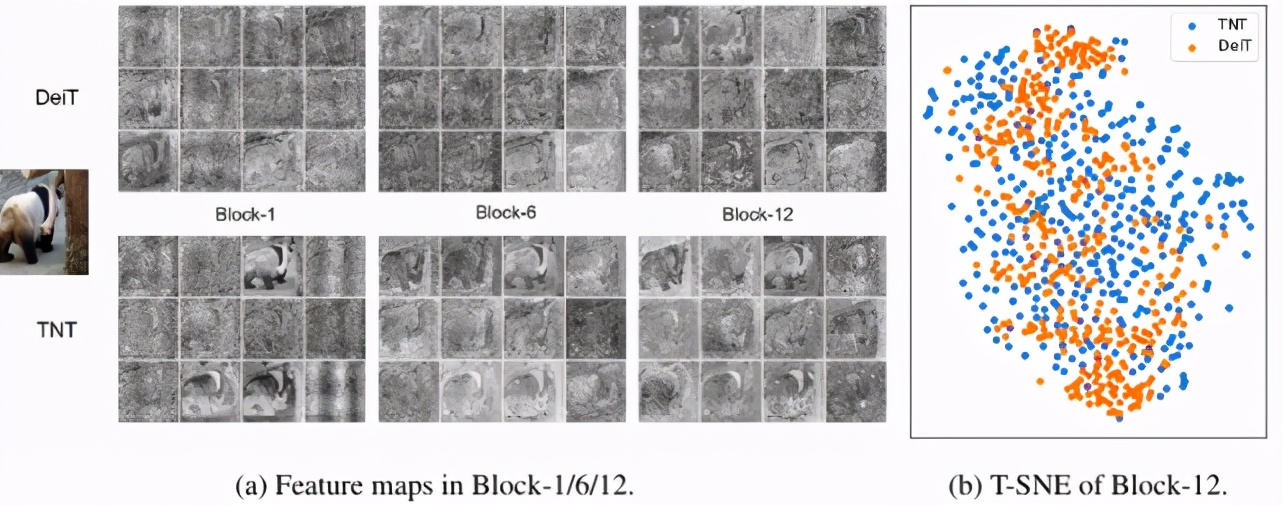
文章图片
图 5:DeiT 和 TNT 特征图可视化 。
迁移学习实验
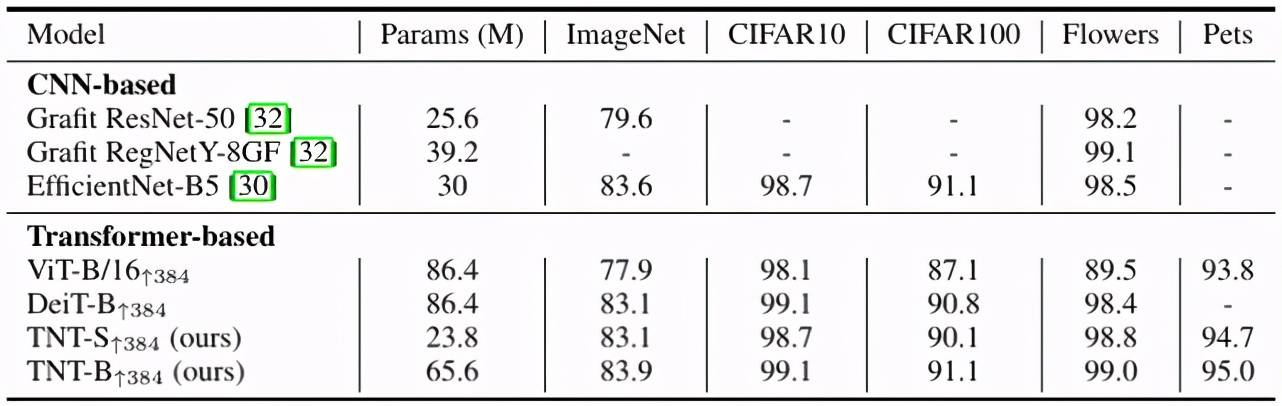
为了证明 TNT 具有很强的泛化能力 , 研究者在 ImageNet 上训练的 TNT-S、TNT-B 模型迁移到其他数据集 。 更具体地说 , 他们在 4 个图像分类数据集上评估 TNT 模型 , 包括 CIFAR-10、CIFAR-100、Oxford IIIT Pets 和 Oxford 102 Flowers 。 所有模型微调的图像分辨率为 384x384 。
下表 3 对比了 TNT 与 ViT、DeiT 和其他网络的迁移学习结果 。 研究者发现 , TNT 在大多数数据集上都优于 DeiT , 这表明在获得更好的特征时 , 对像素级关系进行建模具有优越性 。
文章图片
表 3:TNT 在下游任务的表现 。
总结
该研究提出了一种用于视觉任务的 transformer in transformer(TNT)网络结构 。 TNT 将图像均匀分割为图像块序列 , 并将每个图像块视为像素序列 。 本文还提出了一种 TNT block , 其中外 transformer block 用于处理 patch embedding , 内 transformer block 用于建模像素嵌入之间的关系 。 在线性层投影后 , 将像素嵌入信息加入到图像块嵌入向量中 。 通过堆叠 TNT block , 构建全新 TNT 架构 。 与传统的视觉 transformer(ViT)相比 , TNT 能更好地保存和建模局部信息 , 用于视觉识别 。 在 ImageNet 和下游任务上的大量实验都证明了所提出的 TNT 架构的优越性 。
推荐阅读







- 视觉|超高色准打破行业天花板,创维S82还原真实世界
- 视觉|下瓦房“钻石壹号”品牌区 ——全新升级 耀世登场
- Windows|微软正为Windows 11开发新Mica视觉效果
- 硬件|瑞芯微智能视觉芯片RV1126荣获CPSE安博会最高殊荣:金鼎奖
- 检测|基于双目视觉的目标检测与追踪方案详解
- 最新消息|视觉中国成立元视觉拍卖公司 注册资本5000万
- 网友|马斯克在线科普特斯拉为何不用雷达 网友:纯视觉成本低
- BEVDet|自动驾驶权威评测世界第一,鉴智机器人推出纯视觉3D感知新范式
- Tesla|马斯克在线科普特斯拉为何不用雷达 网友道破真相:纯视觉成本低
- 形象|来了!中原银行7周年视觉形象正式发布