
文章图片
首先看Kernel Primitive API 。 通过对算子 Kernel实现中的底层代码进行抽象与封装 , 提供高性能的Block级IO和 Compute运算 , 实现了算子计算与硬件解耦 。 这样一来 , Kernel 开发可以更加专注计算逻辑的实现 , 在保证性能的同时大幅减少代码量 , 如softmax算子实现由155行减少为30行 , 逻辑更加清晰 , 可维护性更高 。
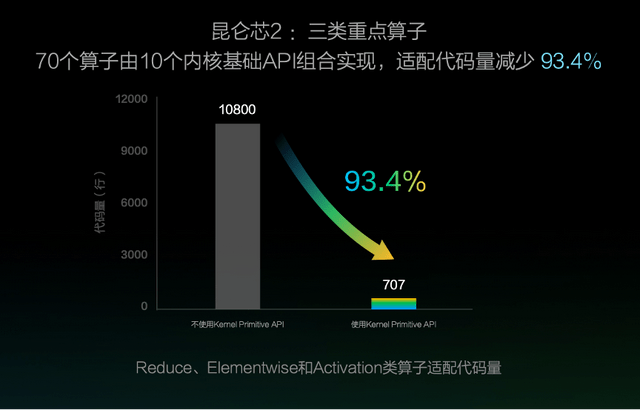
该方案还能够大幅减少硬件适配时的算子开发成本 , 以昆仑芯2接入为例 , 通过Kernel Primitive API组合实现Reduce、Elementwise和Activation这三类算子 , 适配代码量减少93.4% 。 使用 Kernel Primitive API还实现了一处优化、多处收益的效果 , 仅对IO运算进行向量化访存优化 , 飞桨的70个算子性能就可以平均提升12.8% 。
文章图片
其次是 NNAdapter 。 我们知道 , 硬件厂商通过直接子图/整图接入时 , 需要理解框架的内部实现机制 , 门槛高且沟通成本大 。 飞桨在框架和硬件之间建立了NNAdapter统一适配层 , 向上通过 NNAdapter API完成框架适配层的统一接口 , 向下通过 NNAdapter HAL完成硬件抽象层 (HAL)的统一接口 , 实现了对硬件设备的抽象和封装 , 为 NNAdapter在不同硬件设备提供统一的访问接口 。
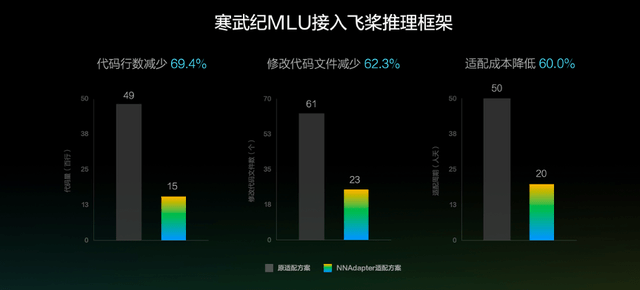
这一方案实现了算子定义及框架调度执行与硬件的解耦 , 降低了门槛 , 减少了成本 。 以寒武纪MLU适配为例 , NNAdapter方案相比原直接子图接入方案 , 代码行数减少69.4% , 修改的代码文件减少62.3% , 人力投入成本降低60% 。
文章图片
最后是预发布版本的神经网络编译器 CINN 。CINN全称为Compiler Infrastructure for Neural Networks , 面向飞桨框架深度优化 , 同时支持训练和推理 。

文章图片
在硬件适配时 , 大量复杂算子需要利用硬件提供的特定基础计算库实现 , 这些复杂算子与硬件的基础计算库差别较大 , 导致了适配成本很高 。
CINN将复杂算子拆分成基础算子组合实现 , 使得适配时只需实现少量基础算子即可完成对各种复杂算子的支持 , 并且这些基础算子与硬件计算库更接近 , 因此实现成本更低 。 然后 , 再通过自动融合及自动代码生成技术 , 解决kernel增多带来的调度和访存开销 , 提升性能 。
CINN编译器方案能带来多大的提升呢?马艳军举例表示 , 「在这次预发布的CINN版本中 , ResNet50 模型的训练性能已持平手工极致优化水平 。 」
推荐阅读




- 柯腾|争做细分赛道冠军——探寻厦门“小巨人”企业成长密码
- 低碳发展|四川做强清洁能源产业
- 硬件|上线两年用户破两亿,腾讯会议还能做什么?
- 数字货币|比特币发明者到底是谁?马斯克这么说
- |南安市司法局凝初心践使命 以民为本做实人民调解
- 孩子|“双减”后 科学实践课如何做好“加法”
- 生产线|贵阳经开区打造千亿元级产业园区——做强经济“顶梁柱”
- 视界|这部电影里的黑洞竟然和真实黑洞这么像?丨夜问
- 模型|2022前展望大模型的未来,周志华、唐杰、杨红霞这些大咖怎么看?
- 信息|财报识别系统教你怎样做好金融信贷审批工作!