
文章图片
当前 , 社区普遍使用分布式训练方法来训练具有海量数据的神经网络 , 但这种方法在面对不同神经网络模型、不同计算资源以及训练中出现的动态变化 , 往往表现得力不从心 。 飞桨创新性地以系统性端到端方式设计分布式训练框架 , 这样做提升了针对不同场景的内在自适应能力 , 进而既能满足多样性应用和差异化计算资源下的各种需求 , 性能表现与其他方法相比也颇具竞争力 。
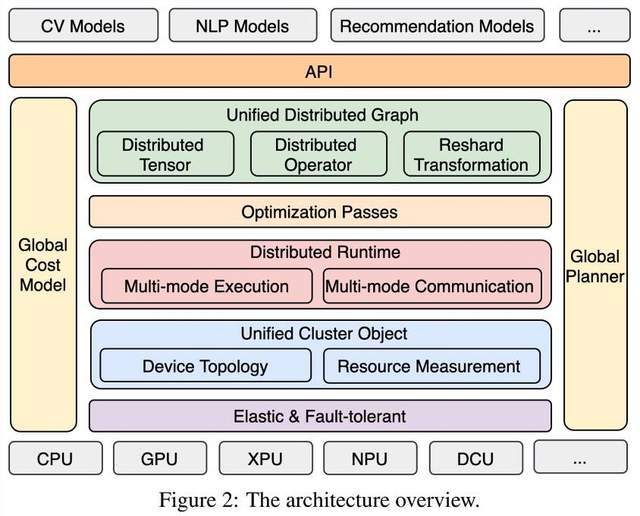
在12月6日百度提交的arXiv论文《End-to-end Adaptive Distributed Training on PaddlePaddle》中 , 我们可以更清楚地洞悉该技术的结构示意图 。
文章图片
论文地址:https://arxiv.org/abs/2112.02752
马艳军在会上介绍了这种端到端自适应大规模分布式训练的设计思路:
? 首先 , 针对不同的模型和硬件 , 抽象成统一的分布式计算视图和异构资源视图 , 并通过硬件感知切分和映射功能及端到端的代价模型 , 搜索出最优的模型切分和硬件放置组合策略 , 将模型参数、梯度和优化器状态按照最优策略分配到不同计算卡上 , 达到节省显存、负载均衡和提升训练性能的目的;
? 接着 , 采用异步流水运行机制 , 以高通信和高并发的方式高效训练;
? 最后 , 为了进一步提高训练的稳定性和资源利用率 , 飞桨提供弹性调度模块 , 感知硬件资源变化 , 自动重构资源视图 , 触发各个模块自动的发生变化 , 如重新构建资源视图、切分、硬件分配、流水运行 。 在不中断训练情况下 , 弹性调度集群可用机器来进一步提升训练的性能 。
这一端到端自适应大规模分布式训练架构的效果如何呢?从飞桨已经做的几组实验结果来看 , 效果很不错 。 比如 , 在 512卡GPU集群训练GPT模型 , 训练速度有显著优势;在鹏城云脑 II集群上采用自适应优化 , 训练速度更是能够达到优化前的2.1倍 。
降低硬件适配成本:三大自研优化方案 硬件适配是开发者使用深度学习框架开发应用时可能会遇到的头疼问题之一 。 随着智能芯片种类的日益复杂 , 适配成本显然已经成为一个重大问题 。
为了开发者适配硬件时有更多选择 , 飞桨一直在努力 。 在WAVE SUMMIT 2020峰会上公布了飞桨硬件生态伙伴圈 , 通过与全球芯片、整机等相关硬件领导厂商的密切合作 , 积极适配芯片或 IP 。 但应看到 , 基于技术创新降低硬件的接入成本同样重要 。
因此 , 百度在峰会上正式推出了硬件适配统一方案 , 这是一种多层次、低成本的硬件适配方案 , 包括飞桨三大自研优化方案:Kernel Primitive API、NNAdapter 和神经网络编译器 CINN(预发布版本) , 分别提供了算子开发与映射、子图与整图接入以及编译器后端接入三类互相关联的方案 , 灵活性十足 。
推荐阅读




- 柯腾|争做细分赛道冠军——探寻厦门“小巨人”企业成长密码
- 低碳发展|四川做强清洁能源产业
- 硬件|上线两年用户破两亿,腾讯会议还能做什么?
- 数字货币|比特币发明者到底是谁?马斯克这么说
- |南安市司法局凝初心践使命 以民为本做实人民调解
- 孩子|“双减”后 科学实践课如何做好“加法”
- 生产线|贵阳经开区打造千亿元级产业园区——做强经济“顶梁柱”
- 视界|这部电影里的黑洞竟然和真实黑洞这么像?丨夜问
- 模型|2022前展望大模型的未来,周志华、唐杰、杨红霞这些大咖怎么看?
- 信息|财报识别系统教你怎样做好金融信贷审批工作!