全球首个知识增强的千亿大模型是怎样诞生的?
算力
OpenAI 之所以能训练出 GPT-3 , 算力是首先要满足的条件 。 微软 2020 年公布的信息显示 , 他们专门为 OpenAI 打造的超级计算机拥有 285,000 个 CPU 核以及 10,000 个 GPU , 供 OpenAI 在上面训练所有的 AI 模型 。
鹏城 - 百度 · 文心的训练算力则来自两个部分:初始化基于百度的百舸集群;训练基于鹏城实验室联合国内优势科研力量研发的鹏城云脑 Ⅱ 。 后者是我国首个国产自主 E 级 AI 算力平台 , 先后在 IO 500 总榜和 10 节点榜、MLPerf training V1.0、AIPerf 500 等国际国内多个权威竞赛榜单中斩获头名 , 为鹏城 - 百度 · 文心的强大技术能力奠定了基础 。
框架
大模型的训练需要大算力 , 但并不是简单地堆砌算力 。 相反 , 这是一个系统性的工作 , 需要解决模型参数量单机无法加载、多机通信负载重、并行效率低等难题 。 具体到鹏城 - 百度 · 文心 , 问题就更复杂了 。 一方面 , 鹏城 - 百度 · 文心的模型结构设计引入了诸多小形状的张量计算 , 导致层间计算量差异较大 , 流水线负载不均衡;另一方面 , 「鹏城云脑 II」的自有软件栈需要深度学习框架高效深度适配 , 才能充分发挥其集群的领先算力优势 。
为了克服这些挑战 , 飞桨的准备工作很早就开始了 。 今年 4 月份 , 飞桨就提出了 4D 混合并行策略来支持千亿参数规模语言模型的高效分布式训练 。
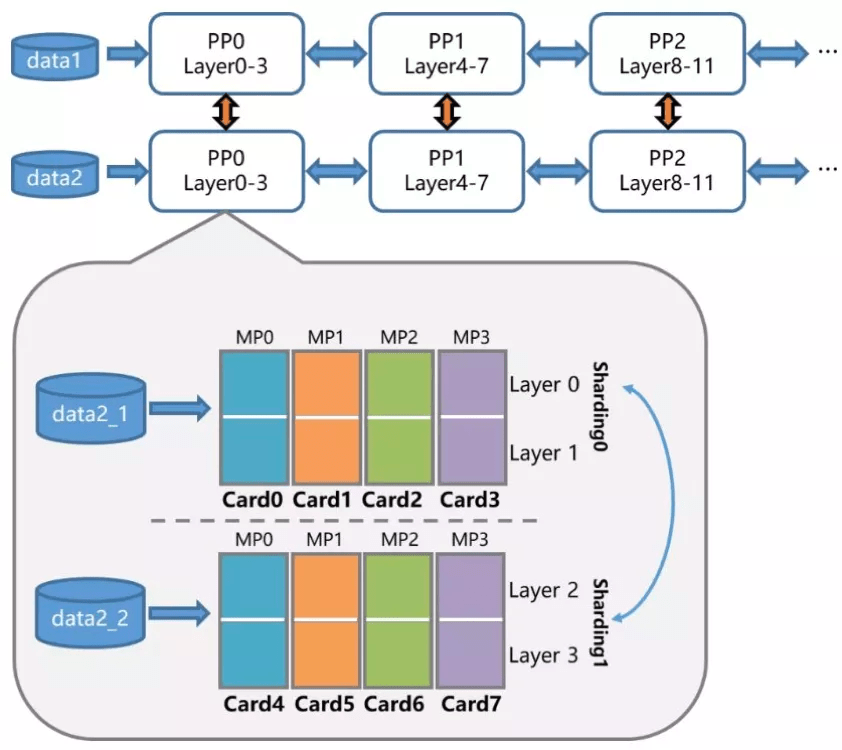
文章图片
4D 混合并行策略示意图
如今 , 为了适配鹏城云脑 II , 飞桨又设计并研发了具备更强扩展能力的端到端自适应大规模分布式训练架构(论文链接:https://arxiv.org/abs/2112.02752) 。 该架构可以针对不同的模型和硬件 , 抽象成统一的分布式计算视图和资源视图 , 并通过硬件感知细粒度切分和映射功能 , 搜索出最优的模型切分和硬件组合策略 , 将模型参数、梯度、优化器状态按照最优策略分配到不同的计算卡上 , 达到节省存储、负载均衡、提升训练性能的目的 。 这一架构将鹏城 - 百度 · 文心的训练性能提升到了传统分布式训练方法的 2.1 倍 , 并行效率高达90% 。
此外 , 为进一步提高模型训练的稳定性 , 飞桨还设计了容错功能 , 可以在不中断训练的情况下自动替换故障机器 , 加强模型训练的鲁棒性 。
在推理方面 , 飞桨基于服务化部署框架 Paddle Serving , 通过多机多卡的张量模型并行、流水线并行等一系列优化技术 , 获得最佳配比和最优吞吐 。 通过统一内存寻址(Unified Memory)、算子融合、模型 IO 优化、量化加速等方式 , 鹏城 - 百度 · 文心的推理速度得到进一步提升 。
推荐阅读



- 水管|柔性泄水管概述、性能参数
- 旗舰|小米 12 Pro 评测:多项「首发」,能否再次成为安卓旗舰「质检员」?
- 参数|CELL+100 细胞制备隔离器,欢迎咨询
- 方面|小米12 Pro将于12月28日发布,主要参数已确认,价格很感人!
- 参数|联想拯救者 Y90 双擎风冷电竞手机官宣,搭载 6.92 英寸 144Hz 屏
- Huawei|多项交互创新,体验更上层楼 华为发布超级智慧笔记本
- Google|Google新增多项COVID-19功能:帮用户快速找到附近检测点和接种点
- 网络|中国移动与华为推出多项5.5G成果,拟将现有5G能力提升十倍
- IT|新款本田奥德赛将于12月27日正式上市 外观内饰有多项变化
- 参数|俄开发能找到血液中癌细胞的新技术