机器之心原创
作者:张倩
百度与鹏城实验室联合发布全球首个知识增强千亿大模型——鹏城 - 百度 · 文心(ERNIE 3.0 Titan) , 是目前为止全球最大的中文单体模型 。 同时 , 百度产业级知识增强大模型 “文心” 全景图首次亮相 。从 15 亿参数的 GPT-2 到 1750 亿参数的 GPT-3 , 我们已经看到了模型规模增长和训练数据增加所带来的显著收益 , 其中最重要的一点就是对标注数据的依赖显著降低 , 这使得很多数据稀缺的场景也能用上性能强大的 AI 模型 , 为 AI 的大规模工业化应用扫清了障碍 。
正如百度 CTO 王海峰所说 , 「人工智能将成为新一轮科技革命和产业变革的重要驱动力量 。 随着数据的井喷 , 算法的进步 , 算力的突破 , 效果好、泛化能力强、通用性强的预训练大模型成为人工智能发展的新方向 。 」驱动产业变革的前提是人工智能要在各行各业的各种场景下有很强的通用性 , 而预训练大模型刚好满足了此轮产业变革对通用性的要求 。
作为国内人工智能的「头雁」 , 百度也很早就看到了这种通用性所蕴含的力量 , 并在过去的几年中研发了一系列大模型 。 不过 , 和业内很多大模型不同的是 , 百度的大模型都有一个特点——引入了「知识增强」 。
众所周知 , GPT-3 这类模型往往有一个缺点——缺乏常识 。 比如在被问及「我的脚有几个眼睛」时 , 它会回答「两个」 。 这一缺陷被业内称为「GPT-3 的阿喀琉斯之踵」 。 在具体的应用中 , 它会导致模型在一些涉及逻辑推理和认知的任务上表现较差 。 为了弥补这一缺点 , 不少研究引入了知识图谱 , 通过知识增强的方法提升语义模型的能力 , 百度文心就是其中的杰出代表 。
文心 ERNIE 1.0 的诞生可以追溯到 2019 年 3 月 , 彼时 , BERT 也才问世不到半年 。 和 BERT 不同的是 , 当时的文心 ERNIE 已经用上了知识增强的概念 。
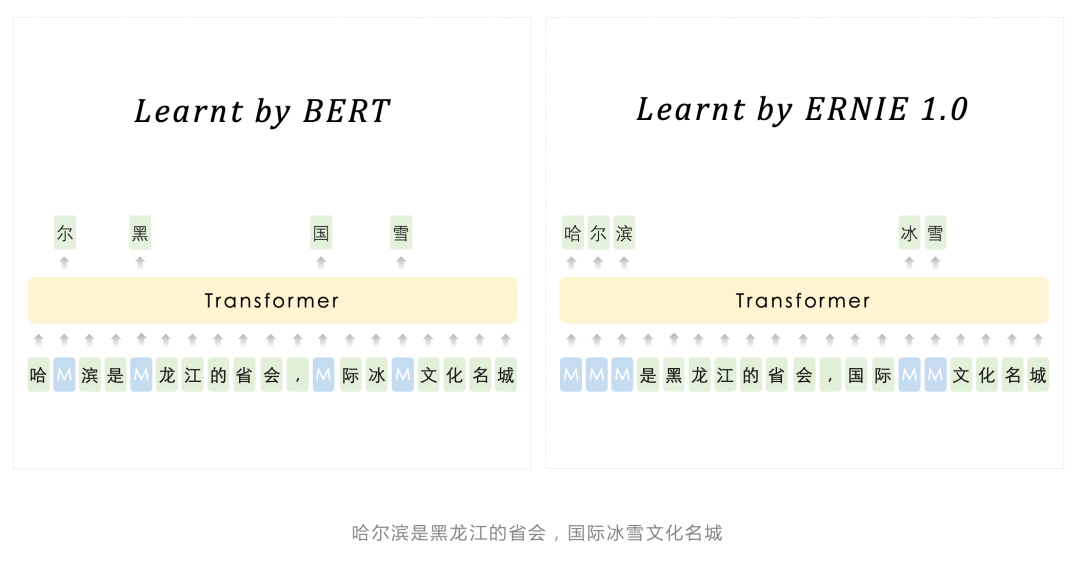
文章图片
百度文心能够同时从百度积累的大规模知识和海量多元数据中持续学习 , 如同站在巨人的肩膀上 , 训练效率和理解准确率都得到大幅提升 , 并具备了更好的可解释性 。 除了将知识和数据融合学习 , 百度文心还通过知识增强跨语言学习与知识增强跨模态学习 , 从多种语言、多种模态数据中学习到统一的语义表示和理解能力 , 分化出了跨语言大模型 ERNIE-M 和跨模态大模型 ERNIE-ViL、ERNIE-ViLG 等一系列模型 。 这些模型组成了一个知识增强大模型矩阵 。
今天 , 这一矩阵的完整图景首次亮相 , 它就是百度刚刚发布的「产业级知识增强大模型『文心』」 。
推荐阅读







- 水管|柔性泄水管概述、性能参数
- 旗舰|小米 12 Pro 评测:多项「首发」,能否再次成为安卓旗舰「质检员」?
- 参数|CELL+100 细胞制备隔离器,欢迎咨询
- 方面|小米12 Pro将于12月28日发布,主要参数已确认,价格很感人!
- 参数|联想拯救者 Y90 双擎风冷电竞手机官宣,搭载 6.92 英寸 144Hz 屏
- Huawei|多项交互创新,体验更上层楼 华为发布超级智慧笔记本
- Google|Google新增多项COVID-19功能:帮用户快速找到附近检测点和接种点
- 网络|中国移动与华为推出多项5.5G成果,拟将现有5G能力提升十倍
- IT|新款本田奥德赛将于12月27日正式上市 外观内饰有多项变化
- 参数|俄开发能找到血液中癌细胞的新技术