机器之心报道
编辑:杜伟、陈萍
来自 Facebook AI 的研究者提出了 NormFormer , 该模型能够更快地达到目标预训练的困惑度 , 更好地实现预训练困惑度和下游任务性能 。在原始的 Transformer 架构中 , LayerNorm 通常在 Residual 之后 , 称之为 Post-LN(Post-Layer Normalization)Transformer , 该模型已经在机器翻译、文本分类等诸多自然语言的任务中表现突出 。
最近的研究表明 , 在 Post-LN transformer 中 , 与较早层的网络相比 , 在较后层的网络中具有更大的梯度幅度 。
实践表明 , Pre-LN Transformer 可以使用更大的学习率、极小的学习率进行预热(即 warm-up) , 并且与 Post-LN Transformer 相比通常会产生更好的性能 , 所以最近大型预训练语言模型倾向于使用 Pre-LN transformer 。
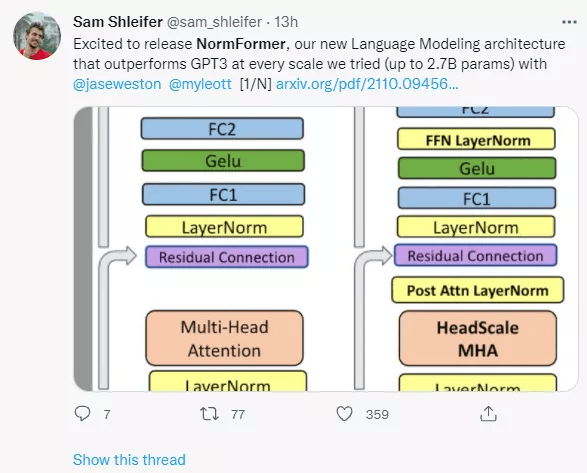
来自 Facebook AI 的研究者表明 , 虽然 Pre-LN 比 Post-LN 提高了稳定性 , 但也具有缺点:较早层的梯度往往大于较后层的梯度 。 这些问题可以通过该研究提出的 NormFormer 来缓解 , 它通过向每一层添加 3 个归一化操作来缓解梯度幅度不匹配问题(见图 1 , 中间):自注意力之后添加层归一 , 自注意力输出的 head-wise 扩展 , 在第一个全连接层之后添加层归一 。 这些操作减少了早期层的梯度 , 增加了后期层的梯度 , 使不同层的梯度大小更接近 。
此外 , 这些额外的操作产生的计算成本可以忽略不计(+0.4% 的参数增加) , 但这样做可以提高模型预训练困惑度和在下游任务的表现 , 包括在 1.25 亿参数到 27 亿参数的因果模型和掩码语言模型的性能 。 例如 , 该研究在最强的 1.3B 参数基线之上添加 NormFormer 可以将同等困惑度提高 24% , 或者在相同的计算预算下更好地收敛 0.27 倍困惑度 。 该模型以快 60% 的速度达到了与 GPT3-Large (1.3B)零样本相同的性能 。 对于掩码语言模型 , NormFormer 提高了微调好的 GLUE 性能 , 平均提高了 1.9% 。

文章图片
论文地址:https://arxiv.org/pdf/2110.09456.pdf
与计算匹配、微调好的 Pre-LN 基线相比 , NormFormer 模型能够更快地达到目标预训练的困惑度 , 更好地实现预训练困惑度和下游任务性能 。
论文一作 Sam Shleifer 在推特上表示:很高兴发布 NormFormer , 这是我们新的语言建模架构 , 在实验过的每个扩展(高达 2.7B 参数)上都优于 GPT-3 。
文章图片
来自魁北克蒙特利尔学习算法研究所的机器学习研究者 Ethan Caballero 表示:「更多的归一化 is All You Need , 在 GPT-3 架构中使用 NormFormer 达到了 SOTA 性能 ,速度提高了 22% , 并在下游任务中获得了更强的零样本性能 。 」
推荐阅读







- 浦峰|冬奥纪实8k超高清试验频道开播,冬奥结束后转入常态化运转
- 数字化|零售数字化转型显效 兴业银行手机银行接连获奖
- 建设|这一次,我们用SASE为教育信息化建设保驾护航
- 智能化|适老化服务让银行更有温度
- 苏宁|可循环包装规模化应用 苏宁易购绿色物流再上新台阶
- |南安市交通运输局强化渣土 运输安全专项整治
- 测试|图森未来完成全球首次无人驾驶重卡在公开道路的全无人化测试
- 网络化|工信部:2025年建成500个以上智能制造示范工厂
- 识别|沈阳地铁重大变化!能摘口罩吗?
- 智能化|龙净环保:智能型物料气力输送系统的研究及应用成果通过鉴定