(3)掩码解码器用于最终分类和分割 。
文章图片
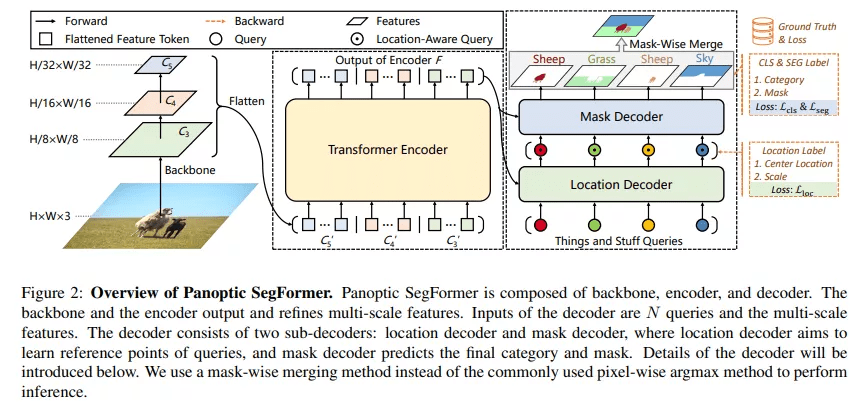
图 2:Panoptic SegFormer 架构 。
Transformer 编码器
分割任务中有两个比较重要的因素:高分辨率和多尺度特征图 。 由于多头注意力层的计算成本很高 , 以前基于 transformer 的方法只能在编码器中处理低分辨率的特征图 , 这限制了分割性能 。 与这些方法不同 , 该研究使用可变形注意力层来实现 transformer 编码器 。 由于可变形注意层的计算复杂度较低 , 因此该研究的编码器可以将位置编码细化为高分辨率和多尺度特征映射 。
位置解码器
在全景分割任务中 , 位置信息在区分具有不同实例 id 的 things 方面起着重要作用 。 受此启发 , 该研究设计了一个位置解码器 , 将 things 和 stuff 位置信息引入到可学习的查询中 。
具体来说 , 给定 N 个随机初始化的查询和由 Transformer 编码器生成的细化特征 token , 解码器将输出 N 个位置感知查询 。 在训练阶段 , 该研究在位置感知查询之上应用辅助 MLP 头来预测目标物体的中心位置和尺度 , 并使用位置损失 L_loc 进行监督预测 。 请注意 , MLP 头是一个辅助分支 , 在推理阶段可以丢弃 。
掩码解码器
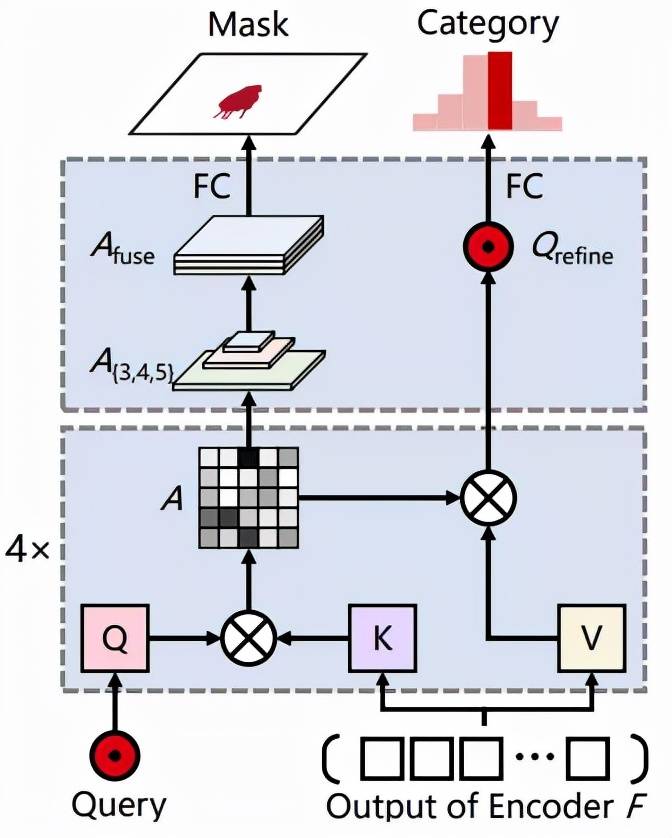
如图 3 所示 , 掩码解码器根据给定的查询来预测物体类别和掩码 。 掩码解码器的查询 Q 是来自位置解码器的位置感知查询 , 掩码解码器的键 K 和值 V 是来自 transformer 编码器的细化特征 token F 。
文章图片
图 3:掩码解码器架构 。
Mask-Wise 推理
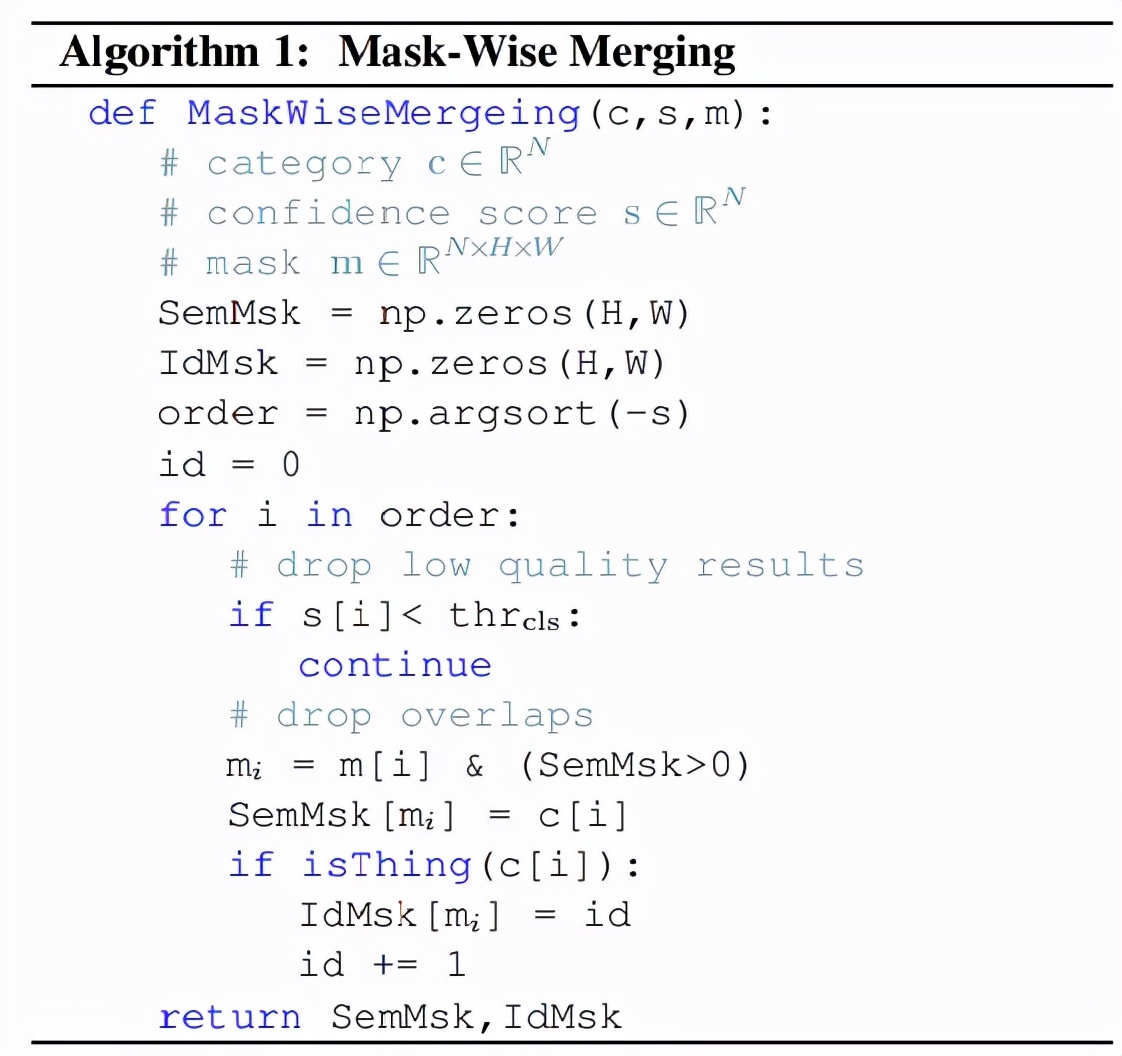
全景分割要求为每个像素分配一个类别标签(或空白)和一个实例 id(对于 stuff 忽略 id) 。 一种常用的后处理方法是启发式过程 , 它采用类似 NMS 的过程来生成 things 的非重叠实例分割 , 称之为 mask-wise 策略 。
对于 stuff , 该研究采用基于启发式过程的 mask-wise 策略来生成非重叠结果 , 而不是 pixel-wise 策略 。 此外 , 该研究平等的对待 things 、stuff, 并通过它们的置信度分数来解决所有掩码之间的重叠 , 而不是在启发式过程中(things 和 stuff 着两者)倾向于 things , 这标志着该研究所用方法与其他方法之间的差异 。 Mask-Wise 推理过程如下所示:
文章图片
Mask-Wise 推理过程 。
实验
该研究在 COCO 上对 Panoptic SegFormer 进行评估 , 并将其与 SOTA 方法进行比较 。 实验提供了全景分割的主要结果和一些可视化结果 。
该研究在 COCO val set 和 test-dev set 上进行实验 。 下表 1 和表 2 报告了 Panoptic SegFormer 与其他 SOTA 方法的对比结果 。 Panoptic SegFormer 在以 ResNet-50 作为主干和单尺度输入的的情况下 , 在 COCO val 上获得了 50.0% PQ , 并且超过了之前的方法 PanopticFCN 和 DETR, 分别提高了 6.4% PQ 和 6.6% PQ 。
推荐阅读







- 卡多|中国移动被迫终止加拿大业务:所有服务停止,2022年1月5日起停运
- China|中国移动加拿大子公司宣布停止运营其CMLink业务
- 该公司|中国移动加拿大子公司 CMLink 宣布于 2022年1 月 5 日起停止运营
- 最新消息|别无选择?担心人手短缺,加拿大一省允许新冠阳性员工继续上班
- 人物|车顶维权女车主曝光庭审内容:特斯拉拿不出任何实锤证据
- 栏目|神评 | 凡是拿iPhone对比的一律视为不如苹果
- 模型|经逆向工程,Transformer「翻译」成数学框架 | 25位学者撰文
- 通信运营商|年底运营商积分过期 不如拿来薅话费
- 技术|从千行百业到千家万户,腾讯拿自己的AI能力探出了一条新路
- 安全|CISA发布Apache Log4j漏洞扫描器 以筛查易受攻击的应用实例