杨净 发自 凹非寺
量子位 报道 | 公众号 QbitAI
如何更顺滑的添加水印?
谷歌的这项新技术 , 让文本简直就像贴在地面上 , 哪怕是在沙尘横飞的场景里 。

文章图片
方法也很简单 。
只需输入一段视频 , 和指定对象的粗略蒙版 。

文章图片
那这个对象的所有相关场景元素 , 都能解锁!
比如人和狗的影子 。

文章图片
还有黑天鹅缓缓拂过的涟漪~

文章图片
以及上述那个赛车疾驰过后激起的沙尘 。
不管是任意对象和主体 , 不论怎么移动 , 所有元素都能抠出来 。
这就是谷歌最新的视频分层技术——omnimatte , 入选CVPR 2021 Oral 。
目前这项技术都已开源 。
如何实现
计算机视觉在分割图像或视频中的对象方面越来越有效 , 然而与对象相关的场景效果 。
比如阴影、反射、产生的烟雾等场景效果常常被忽略 。
而识别这些场景效果 , 对提高AI的视觉理解很重要 , 那谷歌这项新技术又是如何实现的呢?
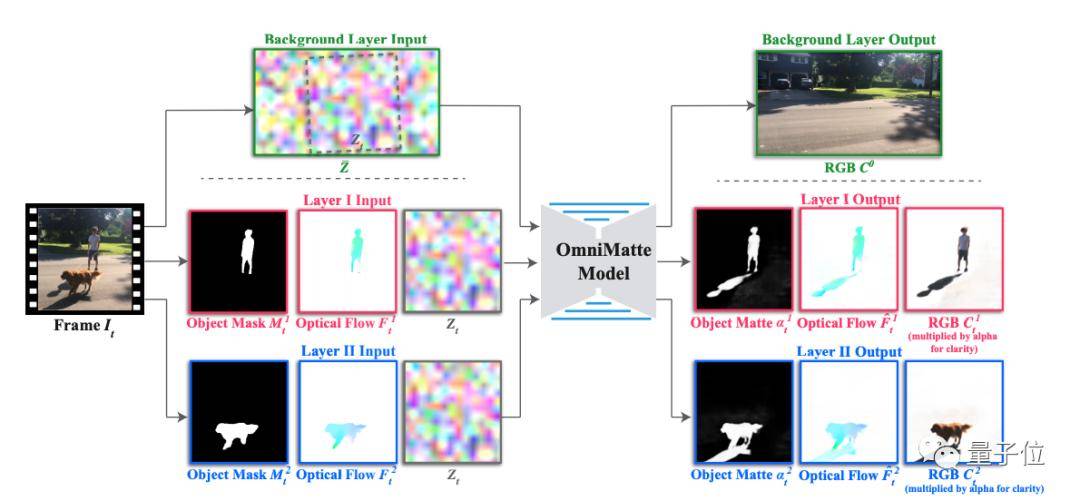
简单来说 , 用分层神经网络渲染方法自监督训练CNN , 来将主体与背景图像分割开来 。
由于CNN的特有结构 , 会有倾向性地学习图像效果之间的相关性 , 且相关性却强 , CNN越容易学习 。
文章图片
输入一段有移动物体的视频 , 以及一个或者多个标记主体的粗略分割蒙版 。
首先 , 使用现成的分割网络比如Mask RCNN , 来讲这些主体分成多个遮罩层和背景噪声图层 , 并按照某种规则进行排序 。
比如 , 在一个骑手、一辆自行车以及几个路人的场景中 , 就会把骑手和自行车归入一个层 , 把人群归入第二层 。
omnimatte模型是一个二维UNet , 逐帧处理视频 。 每一帧都用现成的技术来计算物体掩码 , 来标记运动中的主体 , 并寻找和关联蒙版中未捕捉到的效果 , 比如阴影、反射或者烟雾 , 重建输入帧 。
为了保证其他静止的背景元素不被捕获 , 研究人员引入了稀疏损失 。
此外 , 还计算了视频中每一帧和连续帧之间的密集光流场 , 为网络提供与该层对象相关的流信息 。
最终生成Alpha图像(不透明度图)和RGBA彩色图像 , 尤其RGBA图像 , 简直可以说是视频/图像剪辑法宝!
推荐阅读



- Google|谷歌暂缓2021年12月更新推送 调查Pixel 6遇到的掉线断连问题
- 最新消息|世界单体容量最大漂浮式光伏电站在德州并网发电
- 最新消息|中围石油回应被看成中国石油:手续合法 我们看不错
- 最新消息|CES线下回归受阻:受奥密克戎肆虐影响
- 最新消息|IT系统出错 英国银行给7.5万人多发11亿工资
- 最新消息|宁德时代再投240亿元扩产宜宾基地
- 最新消息|宝马LG和其他公司正考虑使用量子计算机解决具体问题
- 最新消息|快手调整员工福利:减少房补、取消免费三餐 新增生育奖金
- 最新消息|被骂“从未见过如此厚颜无耻之书” 中华书局回应称即日下架
- Tesla|马斯克也要效仿谷歌Facebook 为特斯拉设立控股母公司?