选自arXiv
机器之心编译
编辑:Panda
在当前 NLP 领域 , 基于 Transformer 的模型可谓炙手可热 , 其采用的大规模预训练方法已经为多项自然语言任务的基准带来了实质性的提升 , 也已经在机器翻译等领域得到了实际应用 。 但之前却很少有研究者思考:预训练是否也能提升卷积在 NLP 任务上的效果?近日 ,资源雄厚的 Google Research 的一项大规模实证研究填补了这一空白 。 结果发现 , 在许多 NLP 任务上 , 预训练卷积模型并不比预训练 Transformer 模型更差 。 本文将重点关注该研究的实验结果和相关讨论 , 具体实验设置请参阅论文 。

文章图片
论文地址:https://arxiv.org/pdf/2105.03322.pdf
在这个预训练已成为惯用方法的现代 , Transformer 架构与预训练语言模型之间似乎已经有了密不可分的联系 。 BERT、RoBERTa 和 T5 等模型的底层架构都是 Transformer 。 事实上 , 近来的预训练语言模型很少有不是基于 Transformer 的 。
尽管基于上下文的表征学习历史丰富 , 但现代预训练语言建模却是始于 ELMo 和 CoVE 等基于循环架构的模型 。 尽管它们取得了巨大成功 , 但使用这些架构的研究已经减少了很多 , 因为 Transformer 已经偷走了 NLP 社区的心 , 而且 NLP 社区也已经将它(可能较为隐式地)看作是在前代架构上明确无疑的进步 。
【模型|NLP任务非Transformer不可?谷歌研究发现预训练卷积模型往往更优】近来有研究展现了全卷积模型的潜力并质疑了 Transformer 等自注意力架构的必要性 。 举个例子 ,康奈尔大学博士 Felix Wu 等人在 2019 年提出的卷积式 seq2seq 模型在机器翻译和语言建模等一系列规范基准任务上都取得了优于 Transformer 的表现 。 在这些发现的基础上 , 我们自然会有疑问:我们是否应该考虑 Transformer 之外的预训练模型?
尽管卷积模型早期取得了一些成功 , 但在预训练语言模型时代 , 卷积是否仍然重要还是一个有待解答的问题 。 研究者表示 , 之前尚未有研究工作在预训练 - 微调范式下对卷积架构进行严格评估 。 这正是本研究的主要目的 。 具体而言 , 这篇论文的目标是通过实证方式验证预训练卷积模型在一系列任务上是否能与预训练的 Transformer 相媲美 。
预训练方案与模型架构之间的交互关系这一主题所得到的研究仍旧不足 。 只有 Transformer 能从预训练大量获益吗?如果我们使用一种不同架构的归纳偏置(inductive bias) , 预训练是否也能带来显著增益?预训练的卷积模型能在某些情况中取得更优表现吗?这篇论文研究了这些问题 。
基于卷积的模型有一些明显的优势 。 第一 , 卷积不会有自注意力那种二次内存复杂度的问题—这是一个重大问题 , 甚至足以催生出一类全新的「高效」Transformer 架构;第二 , 卷积在本地执行 , 并不依赖位置编码作为模型的顺序信号 。 话说回来 , 卷积也有许多缺点 。 举个例子 , 卷积无法获取全局信息 , 这意味着这样的模型无法执行一种跨多个序列的跨注意力形式 。
本文将展示一种预训练的序列到序列模型 , 即 Seq2Seq 。 卷积模型的训练使用了基于跨度的序列到序列去噪目标 , 其类似于 T5 模型使用的目标 。 研究者在原始范式(无预训练)和预训练 - 微调范式下对多种卷积变体模型进行了评估 , 比如扩张模型、轻量模型和动态模型 。 这些评估的目标是理解在预训练时代卷积架构的真正竞争力究竟如何 。
实验结果表明 , 在毒性检测、情感分类、新闻分类、查询理解和语义解析 / 合成概括等一系列 NLP 任务上 , 预训练卷积能与预训练 Transformer 相媲美 。 此外 , 研究者发现在某些情况下 , 预训练的卷积模型在模型质量和训练速度方面可以胜过当前最佳的预训练 Transformer 。 而且为了平衡考虑 , 研究者也描述了预训练卷积并不更优或可能不适用的情况 。
本文的主要贡献包括:
- 在预训练 - 微调范式下对卷积式 Seq2Seq 模型进行了全面的实证评估 。 研究者表示 , 预训练卷积模型的竞争力和重要性仍还是一个仍待解答的问题 。
- 研究者还得出了几项重要观察结果 。 具体包括:(1)预训练能给卷积模型和 Transformer 带来同等助益;(2)在某些情况下 , 预训练卷积在模型质量与训练速度方面与预训练 Transformer 相当 。
- 研究者使用 8 个数据集在多个领域的许多任务上执行了广泛的实验 。 他们发现 , 在 8 项任务的 7 项上 , 预训练卷积模型优于当前最佳的 Transformer 模型(包括使用和未使用预训练的版本) 。 研究者比较了卷积和 Transformer 的速度和操作数(FLOPS) , 结果发现卷积不仅更快 , 而且还能更好地扩展用于更长的序列 。
研究者主要关注了以下研究问题(RQ):
- RQ1:预训练能否为卷积和 Transformer 带来同等助益?
- RQ2:卷积模型(不管是否使用预训练)能否与 Transformer 模型媲美?它们在什么时候表现较好?
- RQ3:相比于使用 Transformer 模型 , 使用预训练卷积模型是否有优势 , 又有哪些优势?相比于基于自注意力的 Transformer , 卷积模型是否更快?
- RQ4:预训练卷积不适用于哪些情况?哪些情况需要警惕?原因是什么?
- RQ5:是否有某些卷积模型变体优于另一些模型?
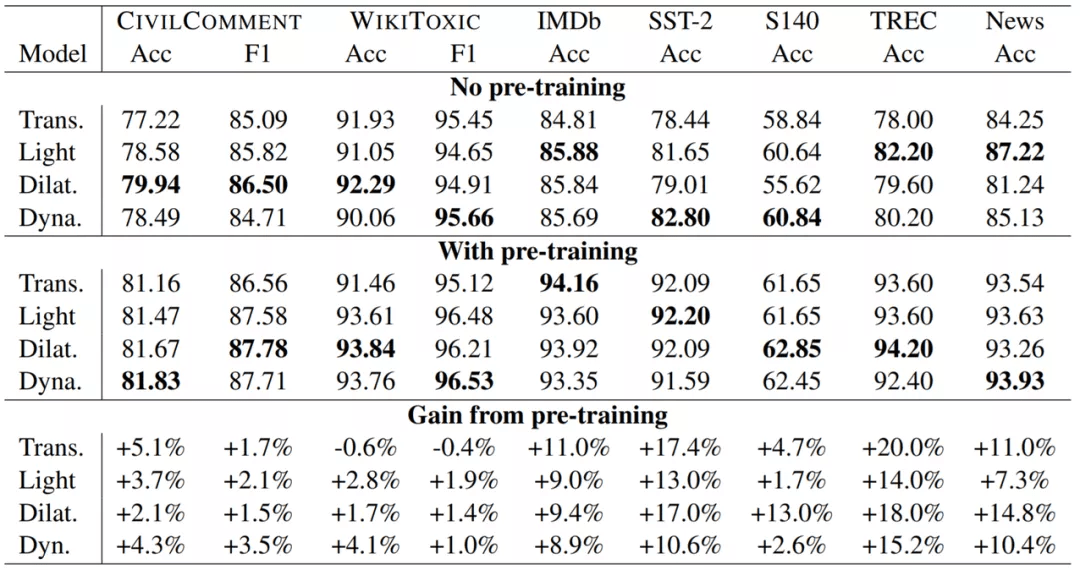
下表 2 是在毒性检测、情感分类、问题分类和新闻分类上 , 预训练卷积和预训练 Transformer 的表现比较 。 所有模型都是 12 层的 seq2seq 架构 , 都有大约 2.3 亿个参数 。 可以看到 , 预训练对卷积也有所助益 , 并且总是优于使用和没使用预训练的 Transformer 模型 。
文章图片
结果总结
实验发现 , 在多个领域的 7 项任务上 , (1)相比于没使用预训练的 Transformer , 没使用预训练的卷积是具有竞争力的 , 而且常常更优;(2)预训练卷积在 7 项任务中的 6 项上都优于预训练 Transformer 。 这是问题 RQ2 的答案 。
实验还发现预训练能给卷积带来助益 , 其产生助益的方式类似于助益基于自注意力的模型的方式 。 因此 , 预训练的优势并不是 Transformer 模型独占的 。 这是问题 RQ1 的答案 。
研究者还发现 , 在这些预训练卷积模型中 , 扩张卷积和动态卷积通常优于轻量卷积 , 这回答了问题 RQ5 。
最后 , 研究者观察到 , 使用预训练后 , 模型的相对性能(即排名)会改变 。 这说明使用预训练来构建架构肯定会有某种效果 。 这种效果的直接影响是不使用预训练时表现好(相对而言)的模型并不一定在使用预训练后表现最佳 。 因此 , 除了将架构与预训练方案组合到一起使用之外 , 我们也需要注意不同的架构在使用预训练后可能会有不同的行为 。
讨论和分析
下面将通过详细的分析和讨论对结果进行扩展讨论 。 其中将讨论预训练卷积的优劣和预训练对性能的影响 , 并将为广大社区给出一些建议 。
1. 预训练卷积在哪些情况下不管用?
根据实验结果 , 我们可以观察到卷积模型相较于完善的预训练 Transformer 的潜在优势 , 并且在某些情况下还能获得质量上的提升 。 但是 , 进一步理解卷积的缺陷可能会有所助益 。
预训练卷积的一个明显缺点是它们缺乏跨注意力的归纳偏置 , 而在 Transformer 编码器中 , 使用自注意力可以自然而然地获得这一能力 。 因为这个原因 , 对于需要建模两个或更多序列的关系的任务而言 , 不宜使用预训练卷积 。 为了验证这一点 , 研究者在 SQuAD 和 MultiNLI 上执行了实验 , 结果发现 , 正是由于缺少归纳偏置 , 预训练卷积的表现远远不及 Transformer 。 在检查和评估模型时 , 我们应该能清楚地区分这一点 , 就像早期的 SNLI 排行榜能清楚地区分使用和不使用跨注意力的模型一样 。
之前在 SQuAD/MNLI 等基准上的评估表明 , 预训练卷积模型确实乏善可陈 。 举个例子 , 在 MultiNLI 上 , 卷积仅能实现约 75% 的准确度 , 而 Transformer 能轻松达到约 84% 。 类似地 , 卷积在 SQuAd 上能达到 70% 左右 , 而 Transformer 则可达约 90% 。 这完全在意料之中 , 因为前提 / 问题无法与假设 / 上下文交互(RQ4) 。 但是 , 研究者通过实验发现 , 这种现象的原因只是单纯地缺乏这种跨注意力属性 。 当在编码器中使用单层跨注意力增强卷积时 , 结果发现预训练卷积能在 MultiNLI 等数据集上达到与预训练 Transformer 非常相近的水平 , 实现约 83% 的准确度 。
话虽如此 , 跨注意力归纳偏置是否真的重要 , 还需要实践者进一步证明 。 研究者强调 , 在扩大规模时 , 连接句子对的模式并不一定是必要的 , 因为这需要对句子对的每种排列进行推理 。 因为这个原因 , 在实践中 , 使用双编码器设置来执行快速嵌入空间查找是更为实际和可行的做法 。 鉴于卷积在一系列编码任务上的强劲表现 , 可以期待预训练卷积在双编码器设置中的出色效果 。
2. 相比于预训练 Transformer , 预训练卷积有何优势?
基于实验结果可知 , 相比于使用 Transformer , 使用卷积能获得一些质量提升 。 下面讨论其它优势 。
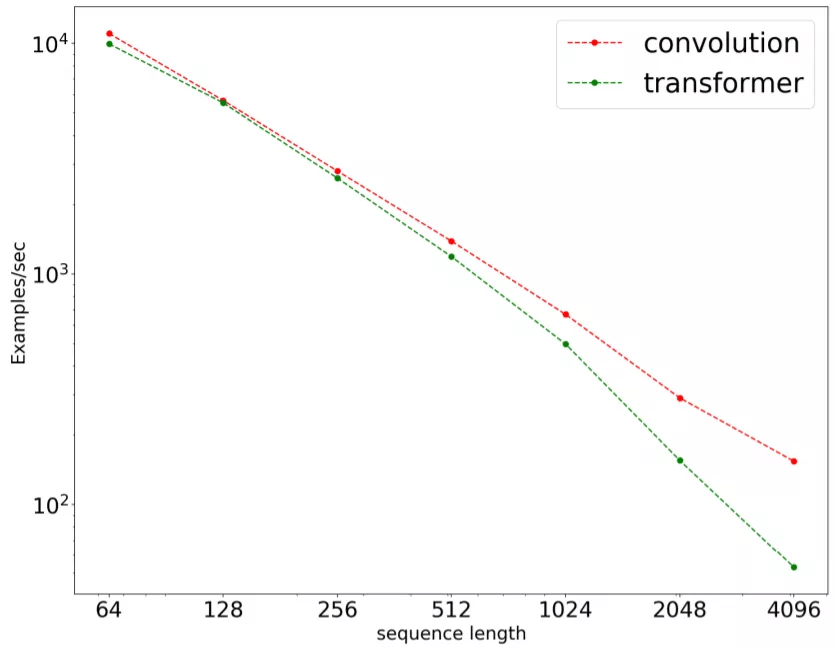
- 在处理长序列时 , 卷积速度更快 , 扩展更好 。
文章图片
图 1:在一个 seq2seq 掩码语言建模任务上 , 序列长度对处理速度的影响 。 结果是使用 16 块 TPUv3 芯片在 C4 预训练上通过基准测试得到的 。 结果以对数标度展示 。
上图 1 展示了在一个序列到序列任务上 , 卷积(LightConvs)与 Transformer 的训练速度 。 输入长度的取值为 {64, 128, 256, 512, 1024, 2048, 4096} 。 结果发现 , 卷积不仅速度总是更快(序列更短时也更快) , 而且扩展性能也更好 。 卷积会线性扩展到更长的序列 , 而 Transformer 无法扩展 。
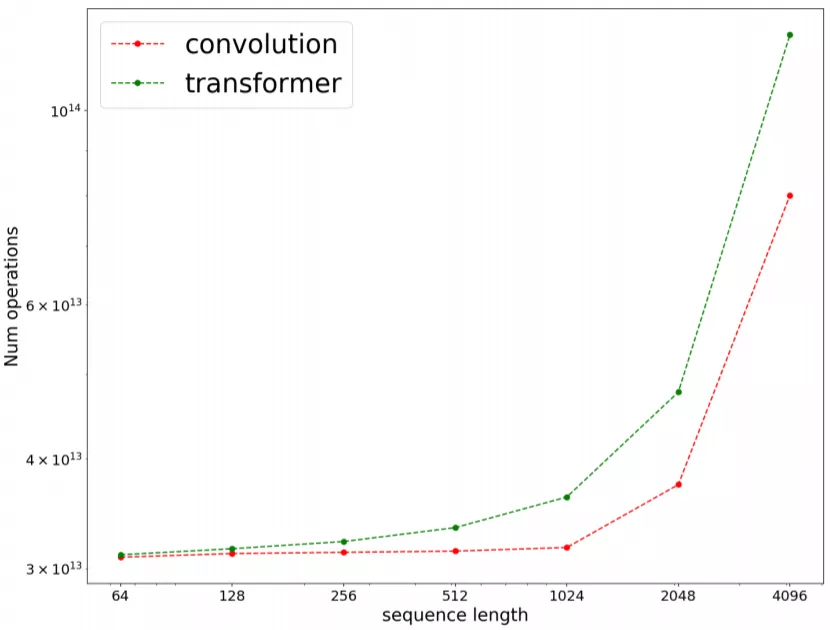
- 卷积的 FLOPs 效率更高
文章图片
图 2:在一个 seq2seq 掩码语言建模任务上 , 序列长度对 FLOPs 数量(爱因斯坦求和的操作数)的影响 。 结果是使用 16 块 TPUv3 芯片在 C4 预训练上通过基准测试得到的 。 结果以对数标度展示 。
整体而言 , 不管是时钟 , 还是 FLOPs , 卷积都更快一些 , 这解答了问题 RQ3 。 此外 , 研究者还发现卷积的 FLOPs 效率在不同序列长度上延展得也更好 。
3. 是否建议用卷积完全替代 Transformer?
尽管 Transformer 已经主导了 NLP 研究社区 , 但这篇论文认为卷积的一些优势被忽视了 , 比如模型质量、速度、FLOPs 和扩展性 。 此外 , 此前我们并不知道预训练是否能助益卷积 。 这篇论文表明 , 在某些任务上 , 预训练能给卷积模型带来与给 Transformer 模型带来的类似增益 。 但是 , 研究者也着重指出 , 卷积难以应付需要跨注意力的任务 , 也难以建模在同一序列中有多个句子或文档的情况 。 研究者认为这是一个值得实践者探索的研究方向 , 并有望发掘出 Transformer 之外的新架构 。
4. 不要将预训练与架构的发展进步混为一谈
这篇论文还表明 , 轻量、动态和扩张卷积都能从预训练获益 , 其带来的增益程度不比给 Transformer 带来的增益少 。
在当前的研究图景中 , 预训练总是与 Transformer 架构紧密相关 。 因此 , 人们总是将 BERT 的成功、Transformer 和大规模语言模型这三者混为一谈 。 尽管到目前为止确实只有 Transformer 会使用大规模预训练 , 但可以相信其它架构也可能有类似潜力 。
基于实验结果 , 研究者相信在架构和预训练的组合效果方面还有进一步的研究空间 。 这项研究本身也有望提升卷积模型在 NLP 领域的竞争力 。 他们表示 , 在探索解决 NLP 任务时 , 不要总是局限于当前最佳的 Transformer , 也应积极地探索其它替代框架 。
推荐阅读







- 地面|全程回顾神舟十三号航天员乘组圆满完成第二次出舱任务
- 人物|马斯克谈特斯拉机器人:不止重复性任务 或能成人类朋友
- 恒星|韦布发射升空 五大天文任务可期
- 长三乙火箭|2021年中国航天宇航发射任务圆满收官
- Windows|第三方软件让你实现Windows 11任务栏拖拽操作
- 火星任务|参考封面 | 2021,应对重大挑战的一年
- 通信|长三乙火箭成功发射通信技术试验卫星九号 2021年中国航天宇航发射任务圆满收官
- 信息|我国成功发射天绘 4 卫星,用于地理信息测绘等任务
- 模型|2022前展望大模型的未来,周志华、唐杰、杨红霞这些大咖怎么看?
- 技术|嫁接香蕉:“不可能任务”完成!