机器之心专栏
机器之心编辑部
在 ACL 2021 的一篇杰出论文中 , 研究者提出了一种基于单语数据的模型 , 性能却优于使用双语 TM 的「TM-augmented NMT」基线方法 。自然语言处理(NLP)领域顶级会议 ACL 2021 于 8 月 2 日至 5 日在线上举行 。 据官方数据, 本届 ACL 共收到 3350 篇论文投稿 , 其中主会论文录用率为 21.3% 。 腾讯 AI Lab 共入选 27 篇论文(含 9 篇 findings) 。
在不久之前公布的获奖论文中 , 腾讯 AI Lab 与香港中文大学合作完成的《Neural Machine Translation with Monolingual Translation Memory》获得杰出论文 。 本文作者也受邀参与机器之心举办的 ACL 2021 论文分享会 , 感兴趣的同学可以点击文末链接查看回顾视频 。
下面我们来看一下这篇论文的具体内容 。

文章图片
论文地址:https://arxiv.org/abs/2105.11269
先前的一些工作已经证明翻译记忆库(TM)可以提高神经机器翻译 (NMT) 的性能 。 与使用双语语料库作为 TM 并采用源端相似性搜索进行记忆检索的现有工作相比 , 该研究提出了一种新框架 , 该框架使用单语记忆并以跨语言方式执行可学习的记忆检索 。 该框架具有一些独特的优势:
- 首先 , 跨语言记忆检索器允许大量的单语数据作为 TM;
- 其次 , 记忆检索器和 NMT 模型可以联合优化以达到最终的翻译目标 。
方法
该研究首先将翻译任务转化为两步过程:检索和生成 , 并在论文中描述了跨语言记忆检索模型和记忆增强型(memory-augmented)翻译模型的模型设计 。 最后 , 该论文展示了如何使用标准最大似然训练联合优化这两个组件 , 并通过交叉对齐预训练解决了冷启动(cold-start)问题 。
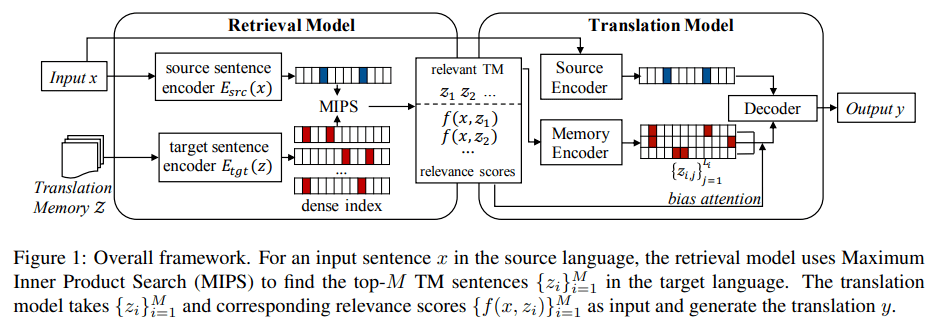
文章图片
该方法的整体框架如图 1 所示 , 其中 TM 是目标语言
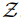
文章图片
中句子的集合 。 给定源语言中的输入 x , 检索模型首先会根据相关函数
【模型|ACL 2021 | 腾讯AI Lab、港中文杰出论文:用单语记忆实现高性能NMT】
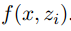
文章图片
, 选择一些来自 Z 的可能有用的句子
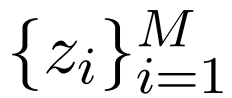
文章图片
, 其中

文章图片
。 然后 , 翻译模型以检索到的集合
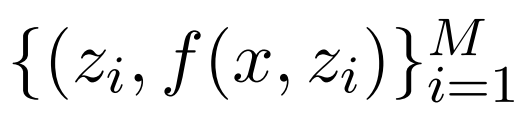
文章图片
和原始输入 x 为条件 , 使用概率模型
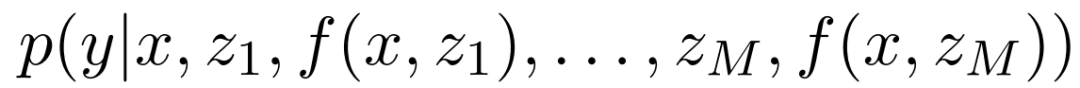
文章图片
来生成输出 y 。
值得注意的是 , 相关性分数
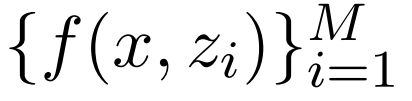
文章图片
也是翻译模型输入的一部分 , 它能够鼓励翻译模型更多地关注更相关的句子 。 在训练期间 , 该研究借助翻译参考的最大似然改进了翻译模型和检索模型 。
检索模型
检索模型负责从大型单语 TM 中为源语句选出最相关的语句 。 这可能涉及测量源语句和数百万个候选目标语句之间的相关性分数 , 带来了严重的计算挑战 。 为了解决这个问题 , 该研究使用一个简单的双编码器框架(Bromley 等, 1993)来实现检索模型 , 这样最相关句子选择可以利用最大内积搜索实现(MIPS ,Maximum Inner Product Search) 。 借助高性能数据结构和搜索算法(例如 Shrivastava 和 Li , 2014;Malkov 和 Yashunin , 2018) , 可以高效地进行检索 。 具体来说 , 该研究将源语句 x 和候选语句 z 之间的相关性分数 f(x, z) 定义为它们的密集向量表征的点积:
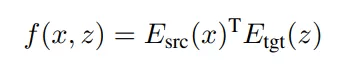
文章图片
翻译模型
给定一个源语句 x、相关 TM 的小型集合
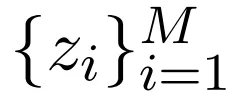
文章图片
、相关性分数
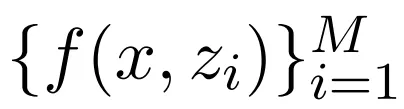
文章图片
, 翻译模型会定义一个如下形式的条件概率

文章图片
该翻译模型建立在标准的编码器 - 解码器 NMT 模型上:(源)编码器将源语句 x 转换为密集向量表征 , 解码器以自回归方式生成输出序列 y 。 在每一个时间步(time step)t , 解码器都会处理先前生成的序列
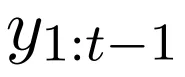
文章图片
和源编码器的输出 , 生成隐藏状态 h_t 。 然后隐藏状态 h_t 通过线性投影转换为 next-token 概率 , 接着会有一个 softmax 函数操作 , 即
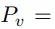
文章图片

文章图片
为了容纳额外的记忆输入 , 该研究使用记忆编码器扩展了标准的编码器 - 解码器 NMT 框架 , 并允许使用从解码器到记忆编码器的交叉注意力机制 。 具体来说 , 记忆编码器对每个 TM 语句 z_i 单独进行编码 , 从而产生一组上下文 token 嵌入
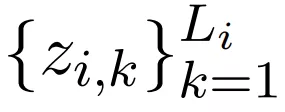
文章图片
, 其中 L_i 是 token 序列 z_i 的长度 。 研究者计算了所有 TM 语句的交叉注意力:
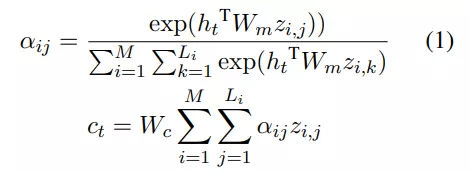
文章图片
为了使从翻译输出到检索模型的梯度流有效 , 该研究将注意力分数与相关性分数进行了偏置处理 , 重写了等式(1)如下所示:
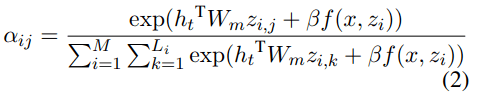
文章图片
训练
该研究在负对数似然损失函数
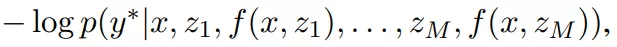
文章图片
中使用随机梯度下降来优化模型参数 θ 和 φ , 其中
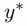
文章图片
指参考翻译 。
然而 , 如果检索模型从随机初始化开始 , 那么所有 top TM 语句 z_i 可能都与 x 无关(或无用) 。 这导致检索模型无法接收有意义的梯度并进行改进 , 翻译模型将学会完全忽略 TM 输入 。 为了避免这种冷启动问题 , 该研究提出了两个交叉对齐任务来热启动检索模型 。
第一个任务是句子级的交叉对齐 。 具体来说 , 该研究在每个训练 step 上对训练语料库采样 B 个源 - 目标对 。 设 X 和 Z 分别对应由 E_src 和 E_tgt 编码的源向量和目标向量的 (B×d) 矩阵 。
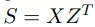
文章图片
是一个相关性分数的 (B×B) 矩阵, 其中每一行对应一个源语句 , 每列对应一个目标语句 。 当 i = j 时 , 任何
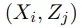
文章图片
对都应该对齐 。 目标是最大化矩阵对角线上的分数 , 然后减小矩阵中其他元素的值 。 损失函数可以写成:
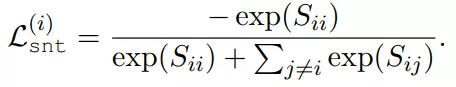
文章图片
第二个任务是 token 级交叉对齐 , 其目的是在给定源语句表征的情况下预测目标语言中的 token , 反之亦然 。 该研究使用词袋损失:
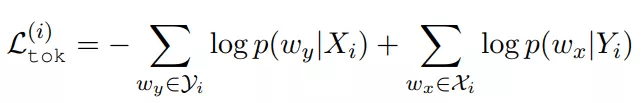
文章图片
其中
文章图片
表示第 i 个源(目标)语句中的 token 集 , token 概率由线性投影和 softmax 函数计算 。
实验结果
该研究在三种设置下进行了实验:
(1)可用的 TM 仅限于双语训练语料库的常规设置;
(2)双语训练对很少 , 但用单语数据作为额外 TM 的低资源设置;
(3)基于单语 TM 的非参数域自适应设置 。
常规设置
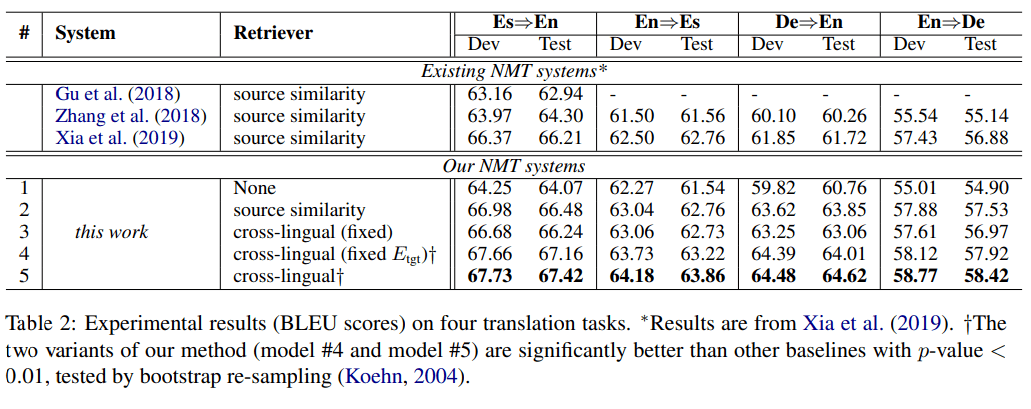
为了研究每个模型组件的效果 , 研究人员实现了一系列的模型变体(如表 2 中的 #1 - #5):
文章图片
如上表 2 所示 , 可以观察到:
(1)该研究使用异步索引刷新训练的完整模型(模型 #5) , 在四个翻译任务的测试集上获得了最佳性能 , 比 non-TM 基线(模型 #1)平均高出 3.26 个 BLEU 点 , 最高可达 3.86 个 BLEU 点( De?En) 。 这一结果证实了单语 TM 可以提高 NMT 的性能 。
(2)端到端学习检索器模型是大幅提高性能的关键 , 使用预训练的固定跨语言检索器只能提供中等的测试性能 , 微调 E_src 和固定 E_tgt 显著提高了性能 , 同时微调 E_src 和 E_tgt 则能获得最强的性能(模型 #5 > 模型 # 4 > 模型 #3) 。
(3)跨语言检索(模型 #4 和模型 #5)可以获得比源相似性搜索(模型 #2)更好的结果 。
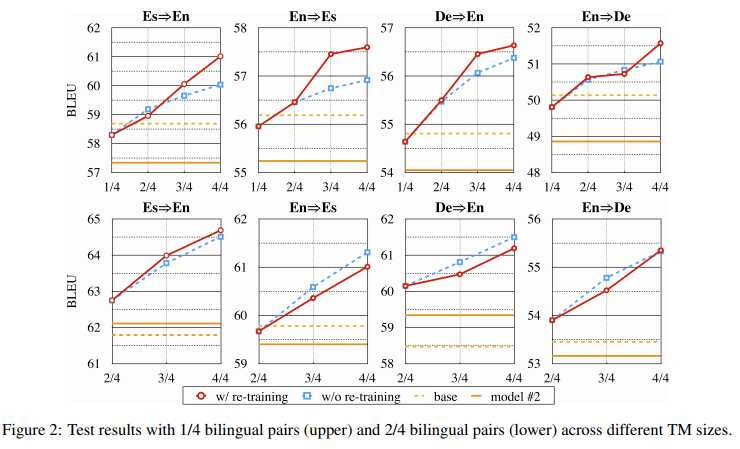
低资源设置
图 2 为在测试集上的主要结果 , 所有实验的一般模式都是一致的 , 由结果可得:TM 越大 , 模型的翻译性能越好 。 当使用所有可用的单语数据 (4/4) 时 , 翻译质量显著提高 。 未经重新训练的模型的性能与经过重新训练的模型的性能相当 , 甚至更好 。 此外 , 该研究还观察到 , 当训练对非常少时(只有 1/4 的双语对可用) , 小型 TM 甚至会影响模型的性能 , 这可能是出于过拟合的原因 。 该研究推测 , 根据不同的 TM 大小调整模型超参数将获得更好的结果 。
文章图片
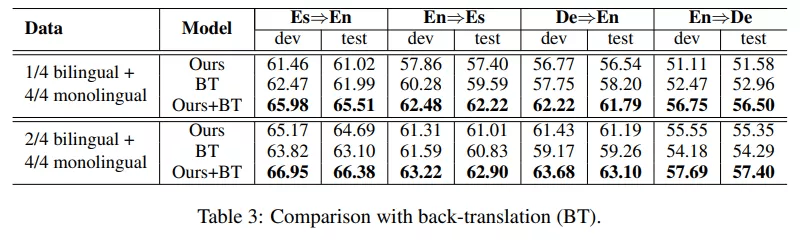
该研究还与反向翻译 (BT)进行了比较 , 这是一种将单语数据用于 NMT 的流行方法 。 该研究使用双语对训练目标到源的 Transformer Base 模型 , 并使用得到的模型翻译单语语句以获得额外的合成并行数据 。 如表 3 所示 , 该研究所用方法在 2/4 双语对上比 BT 表现得更好 , 但在 1/4 双语对上表现较差 。最令人惊喜的是 , 结果表明两种方法是互补的 , 他们的结合使翻译性能取得了进一步的巨大提升 。
文章图片
非参数领域自适应
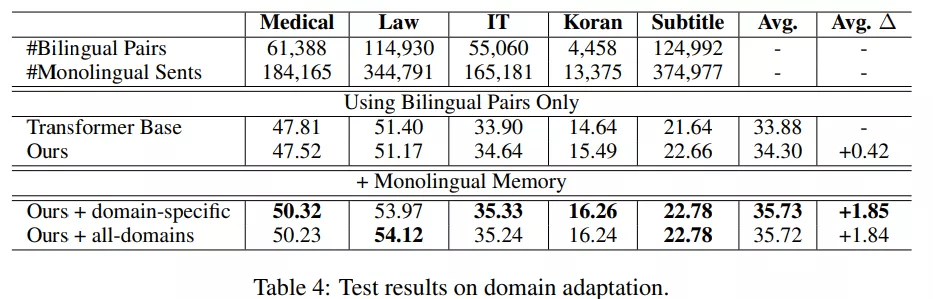
由下表 4 可得 , 当仅使用双语数据时 , 与 non-TM 基线相比 , TM 增强模型在数据较少的域中获得更高的 BLEU 分数 , 但在其他域中的分数略低 。 然而 , 当研究者将 TM 切换到特定域的 TM 时 , 所有域的翻译质量都得到了显著提升 , 将 non-TM 基线平均提高了 1.85 个 BLEU 点 , 在 Law 上提高了 2.57 个 BLEU 点 , 在 Medical 上提高了 2.51 个 BLEU 点 。
该研究还尝试将所有特定领域的 TM 合并成一个 TM , 并将其用于所有域(如表 4 最后一行所示) , 但实验结果并没有获得明显的改进 。 这表明域外数据不能提供帮助 , 因此较小的域内 TM 就足够了 。
文章图片
运行速度
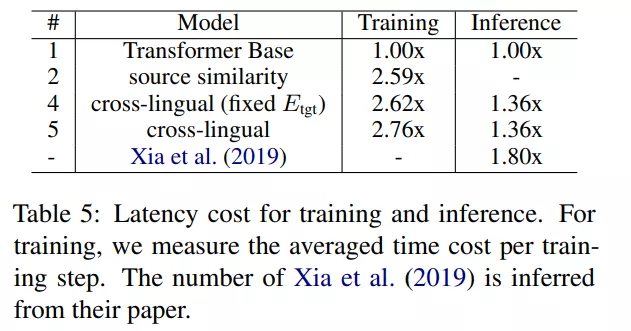
FAISS in-GPU 索引能够让搜索数百万个向量变得非常高效(通常在几十毫秒内完成) 。 在该研究中 , 记忆搜索的执行速度甚至比原生的 BM25 还要快 。 对于表 2 中的结果 , 以普通的 Transformer Base 模型(模型 #1)为基线模型 , 该研究模型(包括模型 #4 和模型 #5)的推断延迟大约是基线的 1.36 倍(所有模型都使用一个 Nvidia V100 GPU) 。
至于训练成本 , 模型 #4 和模型 #5 每个训练 step 的平均时间成本分别是基线的 2.62 倍和 2.76 倍 , 与传统的 TM-augmented 基线相当(模型 #2 是 2.59 倍)( 全部使用两个 Nvidia V100 GPU) , 实验结果如下表 5 所示 。 此外 , 该研究还观察到 , 就训练 step 而言 , 记忆增强型模型的收敛速度比普通模型快得多 。
文章图片
推荐阅读





- Google|谷歌暂缓2021年12月更新推送 调查Pixel 6遇到的掉线断连问题
- 精度|将建模速率提升10倍,消费级3D扫描仪Magic Swift在2021高交会大显“身手”
- 四平|智慧城市“奥斯卡”揭晓!祝贺柯桥客户荣获2021世界智慧城市治理大奖
- 系列|2021中国航天发射圆满收官!年发射55次居世界第一
- 项目|常德市二中2021青少年科技创新大赛再获佳绩
- 选型|数据架构选型必读:2021上半年数据库产品技术解析
- 殊荣|蝉联殊荣!数梦工场荣获DAMA2021数据治理三项大奖
- 公司|外媒:2021,人类太空事业的重大年份
- 语境|B站2021个人年度报告发布:你共计看了多少个视频
- 最新消息|IT系统出错 英国银行给7.5万人多发11亿工资